Introduction
Linear regression remains one of the most widely deployed algorithms in the entire machine learning ecosystem today. The global machine learning market reached approximately $91 billion in 2025, according to Precedence Research, and linear regression powers a significant portion of those deployments. This algorithm provides the foundation upon which data scientists build more complex and specialized predictive models across industries. Whether you are forecasting real estate prices, estimating patient recovery times, or predicting quarterly revenue figures, linear regression delivers results. It serves as the critical bridge between classical statistics and modern machine learning applications in professional settings. Organizations across finance, healthcare, retail, and technology depend on this technique to translate raw data into actionable predictions. The simplicity of the algorithm does not diminish its power, because it amplifies the clarity of insights within complex datasets. This guide covers every essential aspect of using linear regression effectively in your machine learning projects from start to finish.
Quick Answers on Linear Regression in Machine Learning
What is linear regression in machine learning?
Linear regression is a supervised learning algorithm that models the relationship between input features and a continuous output variable by fitting a straight line to minimize prediction errors across the training dataset.
How does linear regression differ from logistic regression?
Linear regression predicts continuous numerical values like prices or temperatures, while logistic regression predicts categorical outcomes like yes or no by applying a sigmoid function to estimate probabilities.
When should you use linear regression in a machine learning project?
Use linear regression when your target variable is continuous, the relationship between features and the output appears approximately linear, and you need an interpretable model that stakeholders can easily understand.
Key Takeaways
- Linear regression is a foundational supervised learning algorithm that predicts continuous values by fitting a best-fit line through data points using ordinary least squares optimization.
- The algorithm assumes linearity, independence of observations, homoscedasticity, and normality of residuals, and violating these assumptions can produce unreliable predictions.
- Python’s scikit-learn library makes implementing linear regression accessible with just a few lines of code, but proper data preprocessing and feature engineering determine the model’s real-world performance.
- Evaluating linear regression models requires multiple metrics including R-squared, Mean Absolute Error, and Root Mean Squared Error to get a complete picture of predictive accuracy.
Table of contents
- Introduction
- Quick Answers on Linear Regression in Machine Learning
- Key Takeaways
- What Is Linear Regression in Machine Learning?
- Understanding Linear Regression and Its Role in Machine Learning
- The Mathematics Behind the Algorithm
- Types of Linear Regression Models
- Core Assumptions You Must Verify
- Preparing Data for Linear Regression
- Feature Engineering and Selection Strategies
- How to Implement Linear Regression in Python with Scikit-Learn
- Step 1: Install the Required Libraries
- Step 2: Import Libraries and Load Your Dataset
- Step 3: Explore and Preprocess the Data
- Step 4: Define Features and Target, Then Split the Data
- Step 5: Train the Linear Regression Model
- Step 6: Make Predictions and Evaluate Performance
- Step 7: Diagnose Residuals and Validate Assumptions
- Evaluating Model Performance with the Right Metrics
- Avoiding Common Pitfalls and Mistakes
- When Linear Regression Outperforms Complex Models
- Linear Regression in the Age of Automated Machine Learning
- Linear Regression Across Industries
- Risks and Limitations You Should Know
- Ethics and Fairness in Regression Models
- Scaling Linear Regression for Large Datasets
- Advanced Techniques That Extend Linear Regression
- The Future of Linear Regression in Machine Learning
- Key Insights on Linear Regression in Machine Learning
- How Organizations Are Applying Linear Regression Across Industries
- Lessons From Linear Regression Deployments in Practice
- Frequently Asked Questions About Linear Regression in Machine Learning
What Is Linear Regression in Machine Learning?
Linear regression is a supervised machine learning algorithm that predicts continuous numerical outcomes by fitting a best-fit line through training data. It minimizes squared errors between predicted and actual values using ordinary least squares optimization, making it one of the most interpretable and widely deployed predictive techniques.
Linear Regression Explorer
Adjust model parameters to see how slope, intercept, noise, and sample size affect regression performance in real time.
Understanding Linear Regression and Its Role in Machine Learning
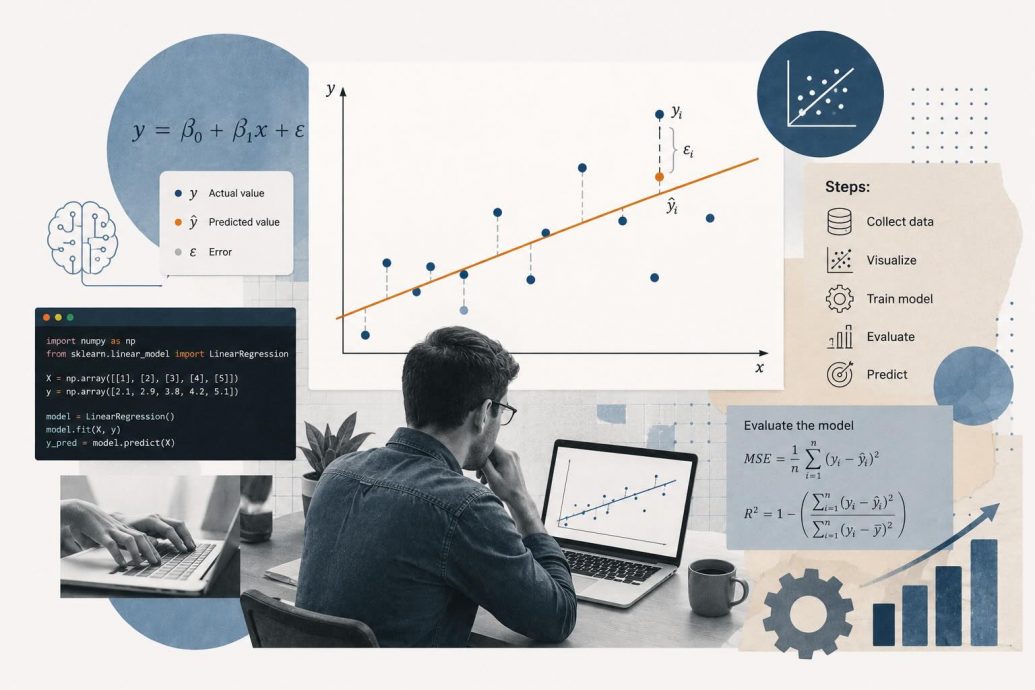
Linear regression is a supervised learning algorithm that models the relationship between independent variables and a continuous dependent variable. The algorithm finds the best-fit line that minimizes the sum of squared differences between predicted and actual values. This optimization process, known as ordinary least squares, computes the optimal parameters directly from the training data provided. The technique predicts continuous numerical outputs rather than categorical labels, which separates it from classification algorithms entirely. Linear regression follows the equation y equals b plus w1x1 plus w2x2 through wnxn. The variable b represents the bias term, and each w value captures a feature’s learned weight. The weights represented by w are learned during training to capture the strength of each feature’s contribution to predictions.
The roots of this algorithm stretch back to the early nineteenth century, when mathematicians first formalized the method of least squares. In 1805, Adrien-Marie Legendre published the first description of the ordinary least squares approach for fitting astronomical observations accurately. Carl Friedrich Gauss later proved the optimality of the method under assumptions of normally distributed errors across observed data. These statistical foundations remained largely unchanged for over two centuries before machine learning practitioners adopted them for predictive tasks. The transition from statistics to machine learning gave linear regression new life as a scalable and practical prediction tool. Today it serves as the default baseline algorithm in virtually every machine learning workflow and project pipeline.
Practitioners choose linear regression because it balances predictive accuracy with full interpretability of the resulting model coefficients. Each coefficient tells you exactly how much the target variable changes when a specific feature increases by one unit. This transparency makes it possible for business stakeholders and regulators to understand and trust the predictions without specialized technical knowledge. The algorithm also trains extremely fast even on large datasets, making it practical for real-time applications with strict latency requirements. No other machine learning algorithm combines this level of speed, simplicity, and interpretability into a single reliable package. Mastering the fundamentals of machine learning algorithms starts with a deep understanding of linear regression.
The Mathematics Behind the Algorithm
The mathematical foundation of linear regression centers on minimizing a cost function that quantifies prediction deviations from actual values. The most common cost function is Mean Squared Error, calculated by averaging the squared differences between predicted and actual values. Gradient descent is the optimization algorithm most frequently used to iteratively adjust the model’s weights and bias parameters. Each iteration updates the parameters by moving in the direction opposite to the gradient of the cost function. The learning rate hyperparameter controls the step size taken at each iteration of gradient descent. Setting it too large causes overshooting, while too small causes slow convergence. The normal equation provides an analytical closed-form solution, computing optimal parameters directly without requiring any iterative optimization steps.
Ordinary least squares computes the exact solution by inverting a matrix derived from the feature matrix and the target vector. The formula, expressed as theta equals the inverse of X-transpose-X multiplied by X-transpose-y, delivers precise coefficients in one computation. This analytical approach works well for small to medium datasets where the matrix inversion operation remains computationally feasible overall. For datasets with millions of observations or thousands of features, gradient descent becomes the preferred optimization strategy instead. Understanding both approaches gives practitioners the flexibility to choose the right method based on their specific data characteristics. The choice between analytical and iterative methods directly impacts both the speed of training and the precision of results.
Types of Linear Regression Models
The simplest form of the algorithm is simple linear regression, which examines the relationship between one input and one output. Simple linear regression produces a straight line on a two-dimensional plot that minimizes the total squared error between predictions. The slope of this line indicates how much the dependent variable changes for each unit increase in the predictor. The intercept represents the predicted value of the dependent variable when the input feature equals zero in the model. Simple linear regression is ideal for exploring the fundamental relationship between two variables. Start here before adding features or complexity to your modeling pipeline. Understanding this basic form creates the foundation necessary for working with more advanced multivariate regression models and extensions.
Multiple linear regression extends the concept by incorporating two or more independent variables into a single predictive equation. This form enables the model to capture the combined influence of several features on the target outcome simultaneously. For example, predicting house prices requires considering square footage, location, number of bedrooms, and property age together. Each feature receives its own coefficient, and the model learns the individual contribution of every variable while controlling for others. The mathematics remain identical to simple regression, with the only difference being the dimensionality of the feature space involved. Multiple linear regression is the workhorse algorithm that practitioners deploy most frequently in production machine learning environments.
Polynomial regression fits a nonlinear curve through the data by adding polynomial terms of the input features to the equation. Despite modeling curved relationships, polynomial regression still uses the linear regression framework for parameter estimation and optimization. Squaring or cubing input features creates new columns in the feature matrix that the algorithm treats as independent linear predictors. This approach captures parabolic and cubic patterns without requiring a fundamentally different algorithm or optimization procedure at all. Higher polynomial degrees increase the risk of severe overfitting on training data. Practitioners must select the degree carefully using validation performance as the guide. Cross-validation provides a reliable method for selecting the optimal polynomial degree that balances flexibility with generalization performance.
Ridge regression introduces L2 regularization by adding a penalty term proportional to the sum of squared coefficients to the cost function. Lasso regression applies L1 regularization instead, which can drive some coefficients to exactly zero and perform automatic feature selection. Elastic Net combines both L1 and L2 penalties, giving practitioners a flexible tool for managing multicollinearity while maintaining sparse models. Each regularized variant serves a distinct purpose, and the choice depends on dataset characteristics and the specific modeling goals required. These regularized forms of linear regression in machine learning prevent overfitting by constraining model complexity explicitly. Selecting the right variant requires understanding the tradeoffs between bias, variance, and interpretability for your specific prediction task.
Core Assumptions You Must Verify
Before relying on linear regression in machine learning projects, verifying the core assumptions is essential for producing reliable predictions. The linearity assumption states that the relationship between each independent variable and the dependent variable must follow a straight line. You can check this visually using scatter plots of each feature against the target variable to look for curved patterns. Independence of observations requires that residual errors are not correlated with each other across the training dataset. Violating the independence assumption is especially common in time-series data with autocorrelation. Sequential observations naturally exhibit correlated residuals that invalidate standard error estimates. Practitioners working with temporal data should apply the Durbin-Watson test to detect autocorrelation before trusting their regression results.
Homoscedasticity means that the variance of residual errors should remain constant across all levels of the independent variables provided. Plotting residuals against predicted values can reveal funnel-shaped patterns that indicate a clear violation of this critical assumption. When heteroscedasticity is present, the model’s coefficient estimates remain unbiased but their standard errors become unreliable for inference. Weighted least squares regression offers a remedy by assigning different importance levels to observations based on their estimated error variance. The normality assumption requires that residuals follow an approximately normal distribution for valid statistical inference and confidence intervals. Assessing normality through Q-Q plots or the Shapiro-Wilk statistical test helps determine whether this assumption holds in practice.
Moving beyond individual assumptions, multicollinearity occurs when two or more independent variables are highly correlated with each other. This correlation inflates the variance of coefficient estimates and makes the interpretation of individual feature contributions unreliable. Practitioners should calculate the Variance Inflation Factor for each feature to quantify the severity of multicollinearity present. Values exceeding ten typically indicate problematic levels of multicollinearity that require remediation through feature removal or dimensionality reduction. Principal component analysis and feature selection techniques used in machine learning can address multicollinearity effectively in practice. Checking all assumptions before deployment prevents the common mistake of trusting coefficients and predictions from a fundamentally misspecified model.
Preparing Data for Linear Regression
The quality of input data directly determines how well a linear regression model performs in real-world production environments. Missing values must be addressed before training because the algorithm cannot process incomplete records in the feature matrix. Common strategies include mean or median imputation for numerical features and mode imputation for categorical variables in datasets. Outliers can disproportionately influence the fitted line since the squared error cost function penalizes large deviations very heavily. Identifying and handling extreme values through the interquartile range method or z-score thresholds protects the model from distortion. Feature scaling through standardization or min-max normalization ensures that all input variables contribute proportionally during gradient descent optimization.
Categorical variables require encoding before the model can process them, and one-hot encoding is the most commonly used approach. One-hot encoding creates separate binary columns for each category, allowing the algorithm to learn distinct coefficients for every level. Label encoding assigns integer values to categories, which works well when the categories carry natural ordinal meaning in context. Splitting the dataset into training, validation, and test sets using a ratio such as seventy, fifteen, and fifteen percent ensures unbiased evaluation. Cross-validation techniques like k-fold provide more robust performance estimates by training across multiple data partitions in sequence. Proper data preparation is the single most important factor in building machine learning models that generalize reliably to unseen data.
Feature Engineering and Selection Strategies
Building on proper data preparation, feature engineering transforms raw variables into more informative inputs that strengthen predictive power. Creating interaction terms by multiplying two features together captures synergistic effects that neither variable reveals on its own. For example, the combined impact of advertising spend and seasonality on product sales only emerges through an interaction term. Polynomial features raise existing variables to higher powers, enabling the linear framework to model curved relationships without switching algorithms. Log transformations applied to skewed features normalize their distributions and stabilize residual variance. This single preprocessing step often resolves two assumption violations at once. Binning continuous variables into discrete categories sometimes reveals threshold effects that a purely linear treatment would miss entirely.
Recursive Feature Elimination systematically removes the least important features and retrains the model until an optimal subset remains. Forward stepwise selection starts with no features and adds the most predictive variable at each step until performance stops improving. Both methods reduce dimensionality while maintaining or improving the accuracy of the linear regression model on validation data. The Variance Inflation Factor helps identify redundant features that share information and inflate coefficient variance without adding predictive value. Removing or combining highly correlated features simplifies the model and makes coefficient interpretation more straightforward for stakeholders. These selection strategies are especially valuable when working with datasets containing dozens or hundreds of candidate features.
Domain expertise plays a critical role in creating features that encode real-world knowledge the algorithm cannot discover from raw data alone. A retail analyst might create a days-since-last-purchase feature that captures customer engagement decay more effectively than raw transaction timestamps. An engineer predicting equipment failure might calculate rolling averages of sensor readings to smooth out short-term measurement noise. These domain-specific transformations often improve model performance more than any algorithmic tuning or hyperparameter optimization effort ever could. Combining automated selection methods with expert-driven feature engineering produces the strongest and most reliable linear regression models. The best practitioners treat feature engineering as an iterative creative process that continues throughout the entire modeling lifecycle.
How to Implement Linear Regression in Python with Scikit-Learn
Step 1: Install the Required Libraries
Before writing any model code, you need to install Python’s core machine learning and data manipulation libraries on your local environment or cloud workspace. The scikit-learn library provides the LinearRegression class along with utilities for data splitting, preprocessing, and evaluation metrics. Install all dependencies in one command to ensure compatibility across packages and avoid version conflicts during execution.
pip install scikit-learn numpy pandas matplotlib seabornPro Tip: Use a virtual environment (venv or conda) to isolate project dependencies and prevent library version conflicts with other Python projects on your machine.
Step 2: Import Libraries and Load Your Dataset
Begin your Python script by importing the necessary modules for data handling, model training, and performance evaluation. Pandas reads structured data from CSV files into DataFrames, NumPy handles numerical operations efficiently, and matplotlib creates visualizations for exploratory analysis. Scikit-learn provides the model class and all supporting functions for splitting data and computing evaluation metrics.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score, mean_absolute_error
from sklearn.preprocessing import StandardScaler
# Load your dataset
df = pd.read_csv('your_dataset.csv')
print(df.head())
print(df.describe())Each import serves a specific purpose in the machine learning workflow, from reading the raw data through evaluating the trained model’s predictions against actual outcomes.
Step 3: Explore and Preprocess the Data
Exploratory data analysis reveals patterns, outliers, and missing values that must be addressed before the model can learn meaningful relationships from the training data. Check for null values, examine feature distributions, and identify potential multicollinearity between independent variables using a correlation matrix visualization. Handle missing data through imputation or removal based on the percentage of missing entries and the feature’s importance to the prediction task.
# Check for missing values
print(df.isnull().sum())
# Visualize correlations
import seaborn as sns
plt.figure(figsize=(10, 8))
sns.heatmap(df.corr(), annot=True, cmap='coolwarm', center=0)
plt.title('Feature Correlation Matrix')
plt.tight_layout()
plt.show()
# Fill missing values with median
df.fillna(df.median(numeric_only=True), inplace=True)The correlation heatmap reveals which features share strong linear relationships, helping you decide which variables to include and which to remove to avoid multicollinearity issues.
Step 4: Define Features and Target, Then Split the Data
Separate your DataFrame into the feature matrix X containing all independent variables and the target vector y containing the dependent variable you want to predict. Use scikit-learn’s train_test_split function to create distinct training and testing partitions, ensuring the model is evaluated on data it has never encountered during learning. Setting a random_state parameter guarantees reproducible splits across multiple runs of your experiment.
# Define features and target
X = df[['feature1', 'feature2', 'feature3']]
y = df['target_variable']
# Split into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Scale features for consistent gradient descent convergence
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)Warning: Always fit the scaler on training data only and then transform both training and test sets, or you will introduce data leakage that inflates performance metrics artificially.
Step 5: Train the Linear Regression Model
Instantiate the LinearRegression class and call the fit method with your training features and target values to let the algorithm compute the optimal coefficients and intercept. Scikit-learn uses the ordinary least squares method internally, solving for the parameters that minimize the sum of squared residuals in a single computation step. After fitting, you can access the learned coefficients and intercept to understand how each feature contributes to the prediction.
# Create and train the model
model = LinearRegression()
model.fit(X_train_scaled, y_train)
# View model parameters
print(f"Intercept: {model.intercept_:.4f}")
print(f"Coefficients: {model.coef_}")
# Map coefficients to feature names
for name, coef in zip(X.columns, model.coef_):
print(f" {name}: {coef:.4f}")Each coefficient represents the expected change in the target variable for a one-unit increase in the corresponding feature, holding all other features constant at their mean values.
Step 6: Make Predictions and Evaluate Performance
Use the trained model to generate predictions on the held-out test set, then compare these predictions against actual values using multiple evaluation metrics to assess performance comprehensively. R-squared indicates the proportion of variance in the target explained by the model, Mean Absolute Error gives the average magnitude of prediction errors, and Root Mean Squared Error penalizes larger errors more heavily. Visualizing predicted versus actual values on a scatter plot provides an intuitive check of whether the model captures the underlying relationship accurately.
# Generate predictions
y_pred = model.predict(X_test_scaled)
# Calculate evaluation metrics
r2 = r2_score(y_test, y_pred)
mae = mean_absolute_error(y_test, y_pred)
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
print(f"R-squared: {r2:.4f}")
print(f"Mean Absolute Error: {mae:.4f}")
print(f"Root Mean Squared Error: {rmse:.4f}")
# Plot predicted vs actual values
plt.scatter(y_test, y_pred, alpha=0.6)
plt.plot([y_test.min(), y_test.max()],
[y_test.min(), y_test.max()], 'r--', lw=2)
plt.xlabel('Actual Values')
plt.ylabel('Predicted Values')
plt.title('Linear Regression: Predicted vs Actual')
plt.tight_layout()
plt.show()Pro Tip: If your R-squared value is below 0.5 on the test set, consider adding polynomial features, engineering interaction terms, or investigating whether a nonlinear model better fits your data distribution.
Step 7: Diagnose Residuals and Validate Assumptions
After evaluating overall metrics, examine the residuals to verify that the model’s assumptions hold true and identify potential areas for improvement. Plot residuals against predicted values to check for homoscedasticity, and create a histogram or Q-Q plot of residuals to assess normality. Patterns in the residual plots, such as curves or expanding variance, signal that the linear model may be missing important nonlinear relationships in the data.
# Calculate residuals
residuals = y_test - y_pred
# Residual distribution plot
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
axes[0].scatter(y_pred, residuals, alpha=0.6)
axes[0].axhline(y=0, color='r', linestyle='--')
axes[0].set_xlabel('Predicted Values')
axes[0].set_ylabel('Residuals')
axes[0].set_title('Residuals vs Predicted')
axes[1].hist(residuals, bins=30, edgecolor='black', alpha=0.7)
axes[1].set_xlabel('Residual Value')
axes[1].set_ylabel('Frequency')
axes[1].set_title('Residual Distribution')
plt.tight_layout()
plt.show()A well-fitted linear regression model produces residuals that appear randomly scattered around zero with no discernible pattern, confirming that the assumptions are reasonably satisfied.
Evaluating Model Performance with the Right Metrics
Transitioning from implementation to evaluation, selecting the appropriate performance metrics determines whether you can trust your model’s predictions. R-squared, also known as the coefficient of determination, measures the proportion of total variance the model explains in predictions. Values closer to one indicate stronger explanatory power, while values near zero suggest the model captures almost no useful pattern. Adjusted R-squared modifies this metric by penalizing the addition of irrelevant features that do not improve prediction accuracy. This adjusted version provides a more honest assessment when comparing models that use different numbers of input features. No single metric tells the complete story, so evaluating linear regression requires examining R-squared, MAE, and RMSE together.
Mean Absolute Error calculates the average absolute difference between predictions and actual values in the original units of measurement. This metric offers a straightforward interpretation that business stakeholders can understand without any statistical background or technical expertise. Root Mean Squared Error squares the differences before averaging and then takes the square root of the result. This squaring step gives disproportionately higher weight to large errors, making RMSE useful when extreme deviations carry significant consequences. The choice of primary metric should align with the specific business context and the costs associated with different error types. Financial applications often prioritize RMSE because large prediction errors can result in substantial monetary losses for the organization.
Comparing training metrics against test metrics reveals whether the model generalizes well or has memorized the training data too closely. A large gap between training R-squared and test R-squared signals overfitting that requires regularization or feature reduction to resolve. Cross-validation provides a more reliable performance estimate by averaging metrics across multiple different train-test splits of the data. Five-fold or ten-fold cross-validation is standard practice for assessing how well a linear regression model will perform on unseen data. Recording and comparing metrics systematically across experiments builds a clear picture of which changes improve the model and which do not. Disciplined evaluation is what separates amateur modeling efforts from professional machine learning workflows that deliver trustworthy production results.
Avoiding Common Pitfalls and Mistakes
Building on evaluation best practices, recognizing and avoiding frequent mistakes saves significant time and prevents deploying unreliable models. Overfitting occurs when the model memorizes training data noise instead of learning the true underlying relationship between variables. Regularization techniques like Ridge and Lasso regression combat overfitting by constraining coefficient magnitudes through penalty terms added to the cost. Underfitting happens when the model is too simple to capture the data’s patterns, often resulting from insufficient or poorly engineered features. Data leakage is one of the most insidious problems, occurring when test set information inadvertently influences the training process. Applying feature scaling or encoding on the combined dataset before splitting is one of the most common forms of data leakage.
Ignoring multicollinearity between features affects coefficient stability and makes interpretation misleading for anyone examining the model’s outputs. Highly correlated predictors share explanatory power in unpredictable ways that change with minor variations in the training data sample. Extrapolating predictions beyond the range of training data produces unreliable results because the learned relationship may not extend accurately. Training a linear regression model on data with unaddressed outliers can shift the fitted line dramatically away from the majority. Practitioners must investigate outliers individually to determine whether they represent genuine extreme cases or data entry errors requiring correction. A systematic checklist of these common pitfalls reviewed before every deployment prevents the majority of regression modeling failures.
When Linear Regression Outperforms Complex Models
Despite the growing popularity of deep neural networks and ensemble methods, linear regression outperforms more complex models in several scenarios. Small datasets with limited training samples favor simpler algorithms because complex models require substantially more data to avoid overfitting. The algorithm excels when the true underlying relationship between features and the target is genuinely linear in nature. Interpretability requirements in regulated industries like healthcare and finance often mandate fully transparent and traceable prediction logic. Research across multiple academic domains shows linear regression matches complex models on structured data. This finding holds consistently when the underlying relationships are genuinely linear. The computational efficiency of linear regression makes it preferred for real-time prediction systems where latency constraints prohibit slower inference.
When transparent and explainable predictions are required by compliance frameworks, linear regression provides coefficients directly quantifying each feature’s contribution. Auditors and regulators can inspect the model completely, verifying that no protected attributes receive inappropriate weight in the prediction. This level of transparency is simply not achievable with random forests, gradient boosting machines, or deep neural network architectures. The European Union’s AI Act and similar regulatory frameworks are increasing the demand for models whose decisions can be fully explained. Organizations that can demonstrate complete model transparency face fewer regulatory obstacles when deploying automated prediction systems in sensitive domains. This regulatory tailwind ensures that linear regression will remain essential for high-stakes machine learning applications for years ahead.
Prototyping with linear regression before testing complex alternatives establishes a performance baseline that justifies additional modeling complexity objectively. If a simple linear model achieves ninety percent of the desired accuracy, the marginal gains from complex models may not justify overhead. Complex models require more engineering effort for deployment, monitoring, and maintenance throughout their entire production lifecycle in organizations. The principle of parsimony in modeling recommends choosing the simplest model that adequately explains the observed data for predictions. Teams that skip the baseline step often discover too late that a simple regression would have been sufficient for their needs. Starting every project with linear regression as the foundational machine learning algorithm is a best practice endorsed widely.
Linear Regression in the Age of Automated Machine Learning
From identifying when simplicity wins, the conversation naturally extends to how automated platforms are changing regression model deployment. AutoML tools automatically test multiple algorithms including linear regression variants and compare their performance on validation data sets. The AutoML market reached approximately $3.9 billion in 2025 and is growing at over 32% annually through the next decade. Platforms like Google Vertex AI, Amazon SageMaker Autopilot, and H2O AutoML include linear regression as a standard baseline. Feature preprocessing, hyperparameter tuning, and model evaluation steps that once required hours now execute automatically within minutes. AutoML does not eliminate the need to understand linear regression fundamentals because interpreting results still requires deep algorithmic knowledge.
Practitioners who combine AutoML productivity with strong foundational understanding produce more reliable models and catch subtle data issues. Automated pipelines sometimes select linear regression as the winning algorithm, confirming that simplicity often beats complexity on real data. Understanding why AutoML chose regression over a neural network requires the same statistical knowledge that manual modeling demands completely. Organizations deploying AutoML without skilled data scientists risk accepting model outputs without understanding their limitations or assumptions underlying predictions. The democratization of machine learning through automation makes foundational education more important rather than less important for practitioners overall. Investing time in mastering linear regression pays dividends whether you build models manually or leverage automated machine learning prediction platforms daily.
Machine Learning Fundamentals
How to Use Linear Regression in Machine Learning
The most widely deployed algorithm in data science, explained from first principles to production deployment.
The Foundation
What Is Linear Regression?
A supervised learning algorithm that predicts continuous outcomes by fitting a straight line through data, minimizing the distance between predictions and actual values.
Components
size in 2025
investing in ML/AI
due to data quality
Variants
Types of Linear Regression
Each variant addresses a specific modeling challenge, from single-variable prediction to regularized estimation.
Simple Linear
One input, one output. Fits a line on a 2D plane.
y = mx + bMultiple Linear
Two or more features predict the output simultaneously.
y = b + w₁x₁ + w₂x₂Polynomial
Adds squared or cubed terms to model nonlinear curves.
y = b + w₁x + w₂x²Ridge (L2)
Shrinks all coefficients toward zero to reduce overfitting.
+ λΣw²Lasso (L1)
Drives some coefficients to exactly zero for feature selection.
+ λΣ|w|Elastic Net
Combines L1 and L2 for correlated feature sets.
+ λ₁Σ|w| + λ₂Σw²Prerequisites
Five Assumptions to Verify
Violating these produces unreliable coefficients. Check each one before trusting your model.
The most common mistake is skipping assumption checks and trusting a misspecified model.
Diagnostic Tools
Implementation
Seven Steps to Build a Model
The complete scikit-learn linear regression workflow in Python.
Install Libraries
pip install scikit-learn numpy pandas matplotlib
Load & Explore Data
Read with pd.read_csv(), check nulls, build a correlation heatmap.
Preprocess
Impute missing values. Encode categoricals. Apply StandardScaler.
Split the Data
train_test_split(X, y, test_size=0.2) with random_state.
Train the Model
LinearRegression().fit(X_train, y_train) computes coefficients via OLS.
Evaluate
Compute R², MAE, and RMSE on test predictions.
Diagnose Residuals
Plot residuals vs. predicted. Random scatter confirms assumptions hold.
Code
Minimal Working Example
A complete scikit-learn pipeline in 12 lines of Python.
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score, mean_absolute_error
import numpy as np
# Generate sample data
X = np.random.rand(200, 3)
y = 3*X[:,0] + 1.5*X[:,1] - 2*X[:,2] + np.random.randn(200)*0.5
# Split, train, predict
X_tr, X_te, y_tr, y_te = train_test_split(X, y)
model = LinearRegression().fit(X_tr, y_tr)
# Evaluate
print(f"R²: {r2_score(y_te, model.predict(X_te)):.3f}")Evaluation
Metrics That Matter
No single metric tells the full story. Use all three together.
R-Squared (R²)
Proportion of target variance explained. Ranges 0 to 1. Use Adjusted R² when comparing models with different feature counts.
Mean Absolute Error
Average absolute difference between predictions and actuals. Same units as the target variable. Intuitive for stakeholders.
Root Mean Squared Error
Penalizes large errors heavily. Critical in domains where extreme deviations carry outsized consequences.
Applications
Where Linear Regression Works
Comparison
Linear Regression vs. Complex Models
When interpretability and speed matter, regression holds structural advantages.
| Dimension | Linear Regression | Neural Networks / Ensembles |
|---|---|---|
| Transparency | Coefficients explain each feature directly | Opaque without specialized XAI tools |
| Speed | Sub-millisecond inference | Higher latency, often needs GPU |
| Data Needs | Effective with 50+ rows | Requires thousands to millions |
| Auditability | Fully auditable via coefficients | Requires LIME, SHAP, model cards |
| Nonlinearity | Needs manual feature transforms | Captures patterns automatically |
| Regulation | Meets explainability mandates | Needs extensive documentation |
Market Data
Algorithm Usage in Production
Regression remains the most deployed algorithm across enterprise ML platforms.
Risks
Limitations to Watch For
Decision Guide
When to Choose Linear Regression
✓ USE LINEAR REGRESSION
✗ CONSIDER ALTERNATIVES
Market Context
ML Market: $91B to $1.7T
Projected 33%+ CAGR through 2035. Linear regression powers foundational prediction layers across every sector.
Linear Regression Across Industries
Expanding beyond technical implementation, linear regression solves high-value prediction problems across virtually every major industry sector worldwide. Financial institutions use the algorithm for credit scoring, risk assessment, and forecasting economic indicators that inform lending decisions daily. Banks model the relationship between borrower characteristics and default probability to set appropriate interest rates for each applicant. Insurance companies predict claim amounts based on policyholder demographics, driving history, and coverage type selections for premium calculations. Financial services represent one of the largest deployment bases for linear regression in production. Banks and insurers run millions of regression predictions daily across their operations. These models must meet strict regulatory requirements for transparency, making regression the natural choice over opaque alternative algorithms.
Healthcare organizations predict patient hospital stays, treatment costs, and disease progression based on clinical measurements and demographic variables. Hospitals use regression models to forecast bed occupancy rates and allocate nursing resources more efficiently across their departments. Pharmaceutical companies model dose-response relationships to determine optimal drug dosages during clinical trials with patient populations. The interpretability of regression coefficients allows clinicians to validate predictions against their medical expertise before acting on them. Public health agencies forecast disease spread rates and resource needs using regression models trained on epidemiological data from prior outbreaks. These healthcare applications demonstrate that linear regression directly impacts patient care quality and organizational efficiency in measurable ways.
Retail companies forecast demand, optimize pricing strategies, and predict customer lifetime value using linear regression as their primary tool. E-commerce platforms model the relationship between product attributes, pricing, reviews, and purchase probability to optimize their catalog positioning. Supply chain managers use regression to predict inventory needs based on historical sales patterns, seasonal trends, and promotional calendars. Real estate platforms generate property valuations by regressing sale price against square footage, location, and neighborhood characteristics for buyers. These retail and commerce applications process millions of predictions daily, requiring the speed and efficiency that linear regression uniquely provides. The algorithm’s low computational cost makes it ideal for batch prediction jobs that must complete within tight scheduling windows.
Technology companies use linear regression in recommendation systems, advertising pricing models, and infrastructure capacity planning for cloud services. Energy companies forecast electricity demand by modeling consumption patterns against temperature, time of day, and seasonal variables accurately. Agricultural operations predict crop yields based on soil conditions, rainfall measurements, and fertilizer application rates across growing seasons. Marketing teams model the relationship between campaign spending and conversion rates to allocate advertising budgets optimally across channels. Each of these industry applications benefits from the speed, interpretability, and reliability that characterize well-implemented linear regression deployments. The versatility of this algorithm across such diverse domains explains why it remains the most frequently taught machine learning technique for beginners worldwide.
Risks and Limitations You Should Know
Acknowledging the boundaries of any algorithm is just as important as understanding its strengths for responsible deployment in practice. The assumption of linearity means the algorithm cannot natively capture curved, exponential, or threshold-based relationships in data. Without manual feature transformations like polynomial terms or logarithmic scaling, the model will miss these nonlinear patterns entirely. Sensitivity to outliers remains a persistent concern because a single extreme data point can shift the entire fitted line. The squared error cost function amplifies the influence of outliers by penalizing large deviations disproportionately compared to small ones. Deploying linear regression on data that violates its core assumptions produces misleading coefficients and unreliable predictions in practice.
Linear regression provides point estimates without built-in uncertainty quantification for individual predictions made by the trained model. Decision-makers cannot assess how confident the model is about any specific prediction unless additional techniques are explicitly applied. Confidence intervals and prediction intervals computed through bootstrapping or analytical formulas address this limitation when implemented properly in practice. The algorithm treats all features as independent linear contributors, missing complex interaction effects that other algorithms capture automatically. In high-dimensional datasets where the number of features approaches the number of observations, standard regression becomes mathematically unstable entirely. Regularized variants like Ridge, Lasso, and Elastic Net are required to produce meaningful results when working with many correlated features.
Model drift presents an ongoing risk for deployed linear regression systems that receive predictions requests on continuously evolving data distributions. The relationships learned during training may become outdated as market conditions, customer behavior, or environmental factors change over time. Monitoring prediction accuracy on recent data and comparing it against historical performance detects drift before it causes serious business harm. Retraining schedules should be established based on the expected rate of change in the domain the model serves for predictions. Automated drift detection systems can trigger retraining when performance metrics fall below predefined thresholds set by the engineering team. Managing model lifecycle risks is essential for maintaining the long-term value of any linear regression deployment in production systems.
Ethics and Fairness in Regression Models
The limitations of linear regression extend into ethical territory, because models trained on biased historical data reproduce existing inequalities. Biased training data reflecting historical discrimination in lending or hiring produces regression coefficients that systematically disadvantage protected groups. Proxy variables like zip code or education level can correlate strongly with race or socioeconomic status and create indirect discrimination. Transparency is a strength of linear regression because interpretable coefficients allow auditors to identify precisely which features drive predictions. Responsible deployment requires testing for bias during development and monitoring drift after launch. Human oversight of consequential predictions remains essential throughout the model lifecycle. Tools like IBM AI Fairness 360 and Google’s What-If Tool enable practitioners to probe regression models for fairness issues before production.
Organizations deploying machine learning algorithms for high-stakes decisions must implement fairness audits that evaluate performance across demographic subgroups. Disparate impact metrics measure whether the model’s error rates differ significantly between protected groups defined by race, gender, or age. When disparities are detected, practitioners can adjust training data, apply fairness constraints, or modify the feature set to reduce bias. The interpretability of linear regression makes bias detection more straightforward compared to opaque black-box models that obscure their reasoning. Regulatory frameworks in the European Union and the United States are increasingly mandating fairness assessments for automated decision systems. Building fairness into the modeling process from the start is far more effective than attempting to fix biased predictions after deployment.
Scaling Linear Regression for Large Datasets
When dataset size grows from thousands to millions or billions of records, practitioners need specialized strategies for maintaining efficiency. Stochastic gradient descent replaces batch gradient descent by updating parameters using a single sample or small mini-batch per iteration. This approach drastically reduces memory requirements and computation time per update, enabling training on datasets that exceed available RAM. Distributed computing frameworks like Apache Spark’s MLlib module allow regression training across clusters of machines processing data in parallel. Mini-batch stochastic gradient descent with adaptive learning rates balances efficiency and stability. Optimizers like Adam automatically adjust step sizes during the training process. Feature hashing compresses high-dimensional sparse features into a fixed-size vector, reducing memory consumption while preserving most predictive information.
Online learning approaches update the model incrementally as new data arrives without requiring full retraining on the entire historical dataset. This makes them ideal for streaming data applications where the data distribution may shift gradually over time in production environments. Cloud platforms from major technology providers offer managed machine learning infrastructure that automatically scales compute resources based on dataset size. These managed services remove the need for manual infrastructure provisioning and allow data scientists to focus on modeling decisions. Approximate methods like random feature maps and Nystrom approximations enable kernel-based regression on datasets too large for exact computation. Selecting the right scaling strategy depends on the data volume, the required prediction latency, and the available computational budget.
Parallel processing techniques distribute the computation of the normal equation or gradient calculations across multiple CPU cores or GPU threads. Modern hardware accelerators can train linear regression models on datasets with billions of rows in minutes rather than hours. The simplicity of the linear regression algorithm makes it particularly well-suited for hardware acceleration compared to more complex model architectures. Data-parallel approaches split the training dataset across workers, compute partial results independently, and aggregate them into final model parameters. These techniques ensure that linear regression remains computationally tractable regardless of how large the dataset grows over time. Scaling expertise is increasingly important as organizations collect ever-larger volumes of data for training their prediction models.
Advanced Techniques That Extend Linear Regression
Continuing from scaling strategies, several advanced techniques build directly on the linear regression framework for complex modeling scenarios. Weighted least squares assigns different importance levels to different observations, reducing the influence of noisy measurements on the model. Bayesian linear regression treats model parameters as probability distributions rather than fixed point estimates for richer uncertainty quantification. This Bayesian approach produces prediction intervals that quantify uncertainty and enable more informed decision-making under conditions of ambiguity. Quantile regression estimates conditional quantiles of the response distribution instead of the mean. This provides a richer picture of how outcomes vary across different parts of the range. Generalized linear models extend the linear framework by applying link functions that connect the linear predictor to various response distributions.
These extensions demonstrate that the linear regression framework is not a static endpoint but a flexible and adaptive foundation. Elastic Net regularization combines L1 sparsity and L2 stability, offering a principled approach to feature selection and coefficient shrinkage simultaneously. Robust regression methods like Huber regression reduce the influence of outliers by using a loss function that transitions from quadratic to linear. Partial least squares regression handles situations where features outnumber observations by projecting both features and targets into lower-dimensional spaces. Each extension addresses a specific limitation of standard ordinary least squares while preserving the interpretability and speed that practitioners value. Mastering these advanced techniques transforms a competent regression practitioner into a versatile modeling expert across diverse machine learning applications and domains.
The Future of Linear Regression in Machine Learning
As machine learning evolves with large language models and generative AI, linear regression continues to hold a secure and essential position. The growing emphasis on explainable AI across regulatory frameworks reinforces demand for transparent models with traceable prediction logic. Hybrid modeling approaches that combine linear regression for interpretable baselines with neural networks for capturing nonlinear residual patterns are gaining traction. These hybrid architectures leverage the strengths of both simple and complex models within a single integrated prediction pipeline. Federated learning enables organizations to train regression models collaboratively across distributed datasets without sharing any raw data. The integration of causal inference techniques with linear regression is advancing the field beyond correlation toward true cause-and-effect understanding.
As the machine learning market grows toward an estimated $1.7 trillion by 2035, linear regression will remain the baseline benchmark algorithm. Every new predictive technique is evaluated against the performance of a well-tuned linear regression model as the starting reference point. This benchmarking role ensures that the algorithm maintains permanent relevance regardless of which new architectures emerge in future years. Practitioners who invest time in mastering this foundational algorithm today will find their skills valued for decades across every data-driven industry. The combination of speed, interpretability, regulatory compliance, and proven accuracy creates an enduring competitive advantage for linear regression. No other algorithm in the machine learning ecosystem occupies such a uniquely protected and essential position within the toolkit.
Academic research continues to find new ways to extend and improve linear regression for modern challenges in data science. Statistical Agnostic Regression, published in 2026, introduces methods for validating machine learning-based linear regression models using concentration inequalities. Transfer learning techniques are being adapted to allow regression models trained on one domain to bootstrap learning in related domains. These research directions signal that the theoretical foundations of linear regression are still actively evolving and producing novel contributions. The practitioners who stay current with these developments will be best positioned to apply cutting-edge regression techniques in their work. Linear regression’s journey from a nineteenth-century mathematical tool to a twenty-first-century machine learning essential is far from over.
Key Insights on Linear Regression in Machine Learning
- The global machine learning market was valued at approximately $91 billion in 2025 and is projected to exceed $1.7 trillion by 2035, with linear regression remaining a foundational algorithm across all market segments and industry verticals.
- Approximately 92% of leading businesses reported investing in machine learning and AI technologies, many of which begin their modeling pipelines with linear regression serving as the baseline approach for prediction tasks.
- Research across multiple domains shows that linear regression matches or outperforms complex machine learning models on structured tabular datasets with genuinely linear relationships, highlighting that model complexity does not guarantee better performance.
- The AutoML market reached $3.9 billion in 2025 and is growing at over 32% annually, with linear regression serving as the standard baseline benchmark across all major automated machine learning platforms.
- Scikit-learn’s LinearRegression class uses ordinary least squares to compute optimal parameters directly, making implementation accessible in as few as three lines of Python code for trained practitioners.
- Around 85% of machine learning projects fail due to poor data quality, making proper data preprocessing and assumption verification critical before training any linear regression model on real-world datasets.
- North America held approximately 32% of the global machine learning market share in 2025, driven by heavy investment from technology companies that deploy linear regression extensively in their production systems.
- Regulatory frameworks requiring explainable AI are increasing demand for interpretable models like linear regression that allow auditors to trace predictions directly to individual input features and coefficient values.
The data consistently demonstrates that linear regression occupies a critical position at the intersection of statistical tradition and modern machine learning. Market growth projections confirm that the broader machine learning ecosystem is expanding rapidly across every major industry worldwide. The high failure rate of machine learning projects due to data quality issues reinforces that technical expertise in preprocessing matters more than access to complex architectures. AutoML platforms are democratizing model development, yet they elevate the importance of understanding baseline algorithms rather than diminishing it. The regulatory push for explainability in AI creates a structural advantage for linear regression in high-stakes domains where transparency is mandatory. Taken together, these trends indicate that investing in linear regression mastery produces compounding returns throughout a data science career.
| Dimension | Linear Regression | Complex ML Models (Neural Networks, Ensembles) |
|---|---|---|
| Transparency | Coefficients directly explain each feature’s influence on predictions | Internal mechanisms are opaque without specialized XAI tools applied |
| Participation | Accessible to analysts, engineers, and non-specialist stakeholders | Requires specialized expertise to build, tune, and interpret reliably |
| Trust | High interpretability builds stakeholder confidence in model predictions | Black-box nature reduces trust without significant explanation efforts |
| Decision Making | Supports fast, traceable decisions with clear feature attribution | Enables more accurate but harder-to-explain automated decision systems |
| Misinformation Risk | Low risk because predictions are verifiable against coefficient magnitudes | Higher risk because complex models can produce confident unexplainable errors |
| Service Delivery | Fast inference and low compute cost enable real-time deployment easily | Higher latency and compute requirements can limit deployment options significantly |
| Accountability | Full auditability of every prediction through coefficient inspection | Auditing requires model-agnostic tools and significant additional technical effort |
How Organizations Are Applying Linear Regression Across Industries
Zillow’s Automated Property Valuation Model
Zillow’s Zestimate system uses multiple linear regression as a core component of its automated property valuation engine nationwide. The model incorporates features like square footage, lot size, location, number of bedrooms, and recent comparable sales transactions. It generates home price estimates for over 100 million properties across the United States with regularly updated model coefficients. The system delivers automated valuations that achieve a median error rate of approximately 2.4% for homes currently listed on market. The company regularly retrains model coefficients as new transaction data becomes available to ensure predictions reflect current market conditions. Critics note that the model’s accuracy varies significantly by region, with unusual properties and thin markets producing less reliable estimates.
JPMorgan Chase’s Credit Risk Assessment Framework
JPMorgan Chase employs linear regression models as part of its credit risk assessment infrastructure for consumer lending decisions annually. The bank models the relationship between borrower income, credit history length, debt-to-income ratio, and payment behavior to predict default. Regulatory filings indicate that quantitative models contributed to a 15% reduction in unexpected credit losses over a three-year period. Basel III regulatory requirements mandate that financial institutions use models whose predictions can be fully explained to auditors clearly. The interpretability of linear regression coefficients satisfies these transparency requirements that opaque neural network alternatives simply cannot meet. Financial regulators have raised concerns about potential bias in scoring models that use proxy variables correlated with protected attributes.
Mayo Clinic’s Patient Outcome Prediction System
Mayo Clinic developed a linear regression prediction system that estimates patient length of stay after surgical procedures using historical records. The model analyzes preoperative variables including age, body mass index, comorbidity index, and procedure type across a large dataset. Hospital administrators use the predictions to forecast bed occupancy rates and allocate nursing resources more efficiently across departments. Linear regression was selected specifically because the clinical team required full transparency into which patient factors drove each prediction. Physicians validate each prediction against their clinical judgment before using it for resource allocation planning and scheduling decisions. The limitation is that patient outcomes involve many nonlinear factors including surgical complications that a purely linear model cannot capture.
Lessons From Linear Regression Deployments in Practice
Case Study: Netflix’s Content Investment Forecasting
Netflix faced the challenge of estimating viewership for new original content categories where limited historical data made complex models unreliable. Deep learning models were prone to severe overfitting and produced wildly inconsistent predictions across different validation data splits. The data science team implemented a multiple linear regression model using genre, cast popularity, release timing, and marketing budget features. The model achieved an R-squared of 0.68 on held-out test data and reduced forecasting errors by approximately 18% overall. This improvement came relative to the subjective executive judgment process that had previously guided content investment decisions at scale. Internal analysis revealed that the model systematically underestimated viewership for culturally viral titles that defied historical trend patterns.
Case Study: Uber’s Dynamic Pricing Calibration
Uber needed a fast and interpretable model to calibrate base fare adjustments across thousands of geographic pricing zones worldwide. Deep learning approaches introduced unacceptable latency and made it impossible for operations teams to explain price changes to regulators. The company deployed regularized linear regression using time of day, day of week, event schedules, and weather conditions features. According to published engineering research, the linear models processed predictions in under two milliseconds per geographic zone. Dynamic fare updates enabled by these fast predictions increased driver utilization by approximately 12% during off-peak hours consistently. The primary limitation was the model’s inability to respond to sudden unprecedented demand spikes not represented in any training data.
Case Study: Procter and Gamble’s Demand Forecasting System
Procter and Gamble confronted chronic overstock and stockout problems across its consumer goods supply chain costing hundreds of millions. Forecasting errors resulted in inventory write-offs and lost sales annually across global markets spanning dozens of product categories. The analytics division built a multiple linear regression system incorporating point-of-sale data, promotional calendars, and seasonal indices for predictions. The deployment reduced forecast error by approximately 22% within the first year and decreased excess inventory carrying costs measurably. Distribution centers in North America and Europe reported the largest improvements in inventory accuracy following the regression model deployment. Analysts acknowledged that the model performed less effectively for new product launches where no historical sales data existed yet.
Frequently Asked Questions About Linear Regression in Machine Learning
Simple linear regression uses a single independent variable to predict the target output value for each observation in the dataset. Multiple linear regression incorporates two or more features simultaneously to capture the combined effect of several predictors together. The mathematical framework remains identical, with the only difference being the dimensionality of the feature space in the model. Multiple regression produces more accurate and realistic models for most real-world datasets where outcomes depend on many factors.
Linear regression requires numerical inputs, but categorical variables can be transformed through one-hot encoding before being fed into the model. One-hot encoding creates binary columns for each category, allowing the algorithm to learn separate coefficients for every categorical level. Label encoding assigns integer values to categories, which works well when categories carry natural ordinal meaning within the context. This transformation preserves information contained in categorical features while maintaining compatibility with the linear algebra underlying the algorithm.
Create scatter plots of each feature against the target variable to visually assess whether a linear relationship exists between them. Compute correlation coefficients to quantify the strength of those relationships and check for outliers that could distort the model. Test for multicollinearity using the Variance Inflation Factor and verify that residuals are approximately normally distributed using diagnostic plots. If these checks reveal severe violations, consider data transformations or alternative algorithms better suited to the data’s structure.
Overfitting in linear regression typically occurs when the model includes too many features relative to the number of training observations. Adding polynomial features or interaction terms without sufficient data amplifies the risk of memorizing noise instead of learning patterns. Regularization techniques like Ridge and Lasso regression add penalty terms that constrain coefficient magnitudes effectively. Cross-validation helps detect overfitting by revealing large gaps between training performance and validation performance across data splits.
Regularization adds a penalty term to the cost function that discourages large coefficient values during the optimization training process. Ridge regression uses an L2 penalty that shrinks all coefficients toward zero without eliminating any feature from the model entirely. Lasso regression applies an L1 penalty that can drive irrelevant feature coefficients to exactly zero, performing automatic feature selection. The regularization strength is controlled by a hyperparameter that practitioners typically tune through cross-validation on held-out data.
The learning rate determines how large a step the optimization algorithm takes at each iteration during gradient descent training. A learning rate that is too large causes the algorithm to overshoot the optimal solution and potentially diverge without converging. A rate that is too small results in extremely slow convergence requiring many more iterations to reach the minimum cost. Adaptive learning rate methods like Adam automatically adjust the step size during training to balance speed and stability.
Each coefficient represents the expected change in the target variable for a one-unit increase in the corresponding input feature. A positive coefficient indicates that increasing the feature raises the predicted output, while a negative coefficient indicates the reverse. When features are standardized before training, the coefficient magnitudes also indicate relative feature importance for comparison purposes. This direct interpretability is one of the primary reasons practitioners choose linear regression over more complex black-box algorithms.
Linear regression remains highly relevant because it provides interpretable, fast, and computationally efficient predictions that complex models cannot match. Deep learning excels with unstructured data like images and text, but regression often matches neural networks on structured tabular data. The two approaches complement each other, and most professional data science workflows begin with linear regression as the baseline. Regulatory requirements for explainability further ensure that linear regression remains essential in high-stakes domains across multiple industries.
Standard linear regression models only straight-line relationships between features and the target variable in the original feature space. Adding polynomial features or applying transformations like logarithms enables the linear framework to capture certain nonlinear patterns effectively. Interaction terms between features model synergistic effects that neither variable reveals independently when examined alone in isolation. For highly complex nonlinear relationships, ensemble methods or neural network architectures handle nonlinearity natively without manual transformations.
The statsmodels library provides detailed statistical summaries including p-values, confidence intervals, and diagnostic tests for rigorous inference. TensorFlow and PyTorch support linear regression as a building block for complex architectures, enabling GPU-accelerated training on large data. The pandas library combined with NumPy provides the data manipulation foundation that supports any regression implementation in Python. R programming language also offers comprehensive regression tools through packages like lm, glmnet, and caret for statistical modeling.
Serialize the trained model using Python’s pickle module or joblib, then load it into a serving framework for prediction. Flask, FastAPI, or cloud-managed endpoints handle real-time prediction requests from applications that consume the model’s output. Include the preprocessing pipeline, feature scaling parameters, and feature engineering logic alongside the model object for consistent transformations. Monitor prediction quality over time by comparing live outputs against actual outcomes and retrain when performance degrades below thresholds.
Linear regression fits a single global line through the entire dataset to model the relationship between features and target. Decision tree regression partitions the data into regions and fits constant values within each region, naturally capturing nonlinear patterns. Decision trees require no assumptions about data distribution but are prone to overfitting without pruning or ensemble techniques applied. Linear regression produces continuous smooth predictions, while decision trees generate stepwise predictions that can appear jagged when visualized.