
Introduction
In today’s data-driven world, machine learning (ML) is reshaping industries, revolutionizing decision-making processes, and automating tasks. But how exactly does machine learning work? It’s not just about building a model — it’s a carefully structured process known as the machine learning lifecycle. From defining a problem to model deployment and ongoing iteration, understanding the ML lifecycle is crucial for businesses aiming to unlock the potential of AI.
In this blog post, we’ll explore each stage of the machine learning lifecycle in detail, with practical insights and tips for navigating this complex yet essential process. Whether you’re a data scientist, business leader, or just curious about AI, this guide will walk you through how to successfully implement machine learning models in your organization.
Table of contents
- Introduction
- Problem Definition: The Foundation of Your ML Journey
- Data Collection: The Fuel for Machine Learning Models
- Data Preprocessing: Cleaning the Raw Data
- Feature Engineering: Selecting the Right Variables
- Model Selection: Picking the Right Algorithm
- Model Training: Teaching the AI
- Model Evaluation: Testing for Accuracy
- Model Deployment: Taking It Live
- Model Maintenance: Keeping It Relevant
- References
Problem Definition: The Foundation of Your ML Journey
In any machine learning project, defining the problem is by far the most crucial step. While it may seem like a simple or obvious starting point, the process of clearly identifying and articulating the problem sets the direction for every subsequent action. A well-defined problem ensures that the entire machine learning project is aligned with the business goals and objectives, and helps to focus efforts on the right data, algorithm, and evaluation metrics. Without a clear problem definition, it’s easy to veer off course, wasting time, resources, and effort.
Why Clear Problem Definition is Key
A well-articulated problem not only guides the selection of the right tools but also drives alignment between technical teams, business stakeholders, and end-users. This stage ensures that the scope of the project is well understood and that the machine learning model will be tailored to meet specific needs rather than being a generic solution.
Here’s why this step is essential:
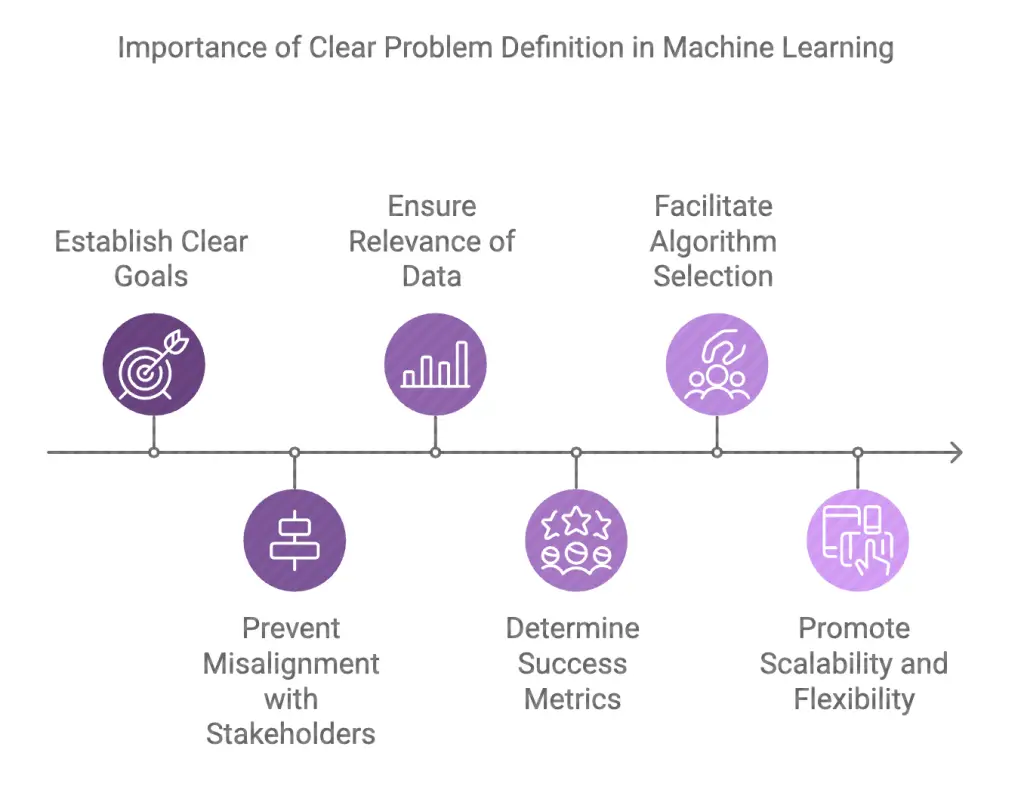
Establishes Clear Goals: Defining the problem helps to translate the business objective into a clear machine learning goal. Are you trying to predict sales? Classify customer behavior? Detect fraudulent activity? Your problem definition will shape the type of model to build and the data to use.
Prevents Misalignment with Stakeholders: Often, data scientists and business stakeholders may have different perspectives on the project. A clear problem definition ensures that all parties are on the same page, which is critical to avoid costly miscommunications or unproductive efforts later on.
Ensures Relevance of Data: By understanding the problem at the core, you can identify the exact kind of data needed for your model. For instance, if the goal is to predict house prices, historical real estate data, economic indicators, and location features will be critical. A poorly defined problem might result in irrelevant data that does not serve the intended purpose.
Determines Success Metrics: Clear problem definition helps set the stage for defining the metrics that will be used to evaluate the success of the model. Is the objective to maximize accuracy, minimize errors, or strike a balance with metrics like precision and recall? These decisions cannot be made until the problem is fully understood.
Facilitates Algorithm Selection: Whether you’re dealing with classification, regression, clustering, or reinforcement learning, the problem definition directly impacts the type of algorithm to use. For example, if the task requires predicting future outcomes (e.g., next quarter’s sales), you’ll need a regression model. In contrast, classification tasks, like categorizing emails into spam or not, would require a different approach.
Promotes Scalability and Flexibility: A problem well-defined today sets you up for scaling the solution later. If the problem definition is vague or too broad, the model might lack flexibility, making it difficult to apply the solution to new situations or expanding the scope.
How to Define a Problem in Machine Learning
A good problem definition is often iterative. It’s a dynamic process that involves collaboration and thorough analysis of business needs and technological capabilities. Here’s a step-by-step guide to defining a machine learning problem:
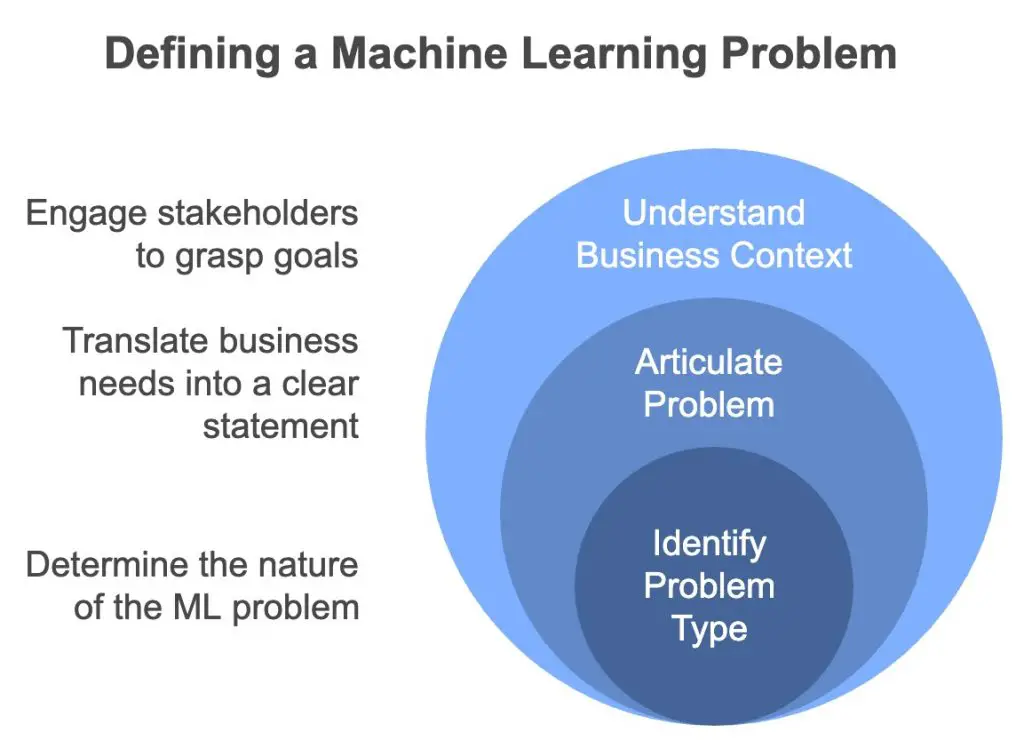
Understand the Business Context:
Engage with stakeholders to understand their goals and challenges. What is the primary issue that the machine learning model should solve? It could be optimizing supply chain management, improving customer retention, or predicting equipment failures. Understanding the bigger picture allows you to align your ML model with the business strategy.
Clearly Articulate the Problem:
Based on the business needs, translate them into a machine learning problem statement. For instance, instead of simply stating “improve customer experience,” define it as: “Predict which customers are most likely to churn in the next three months based on usage patterns, demographics, and customer feedback.” This clear articulation is the foundation upon which the entire machine learning lifecycle will be built.
Identify the Type of Problem:
Is the problem classification (predicting categories), regression (predicting continuous values), clustering (grouping similar items), or something else entirely? Understanding the problem type helps you narrow down which algorithms and techniques to apply.
Example: A classification task would be classifying emails as spam or not, while a regression problem would be predicting the price of a house.
Formulate the Success Metrics:
Define how the success of the model will be measured. Common metrics include:
Accuracy: How often the model’s predictions are correct.
Precision and Recall: Used primarily for classification tasks where false positives and false negatives carry different weights.
F1 Score: The harmonic mean of precision and recall.
RMSE (Root Mean Square Error): For regression tasks, this metric measures the difference between predicted and actual values.
Map Out Constraints and Limitations:
Every machine learning problem has constraints such as computational limitations, time constraints, data availability, and ethical concerns. For example, if there is limited data available, the model might be overfitting. If ethical considerations around data privacy exist, those will need to be factored into the problem definition. Clear awareness of these limitations will help in designing a feasible solution.
Clarify Expected Output:
What form will the model’s output take? Is it a decision that needs to be made based on predictions, a recommendation, or just a classification? Knowing the expected output helps inform the downstream systems that will use the model’s predictions.
Example: If the goal is to identify fraudulent transactions, the output should be a binary decision (fraudulent or not) rather than a continuous probability.
Set a Timeline for Results:
Decide how soon the model needs to be deployed and how often it will need to be retrained. For instance, in dynamic markets like e-commerce, models might need to be retrained regularly to account for new consumer behaviors or trends.
Common Pitfalls in Problem Definition
Even though defining the problem seems simple, it’s easy to overlook certain aspects, leading to issues later in the project. Here are a few common pitfalls:
Ignoring Business Objectives: The ultimate goal of machine learning is to solve a business problem. It’s easy to get caught up in the technical aspects, but every step of the ML process should be aligned with business goals. Failure to do so results in technical success but business failure.
Vague Problem Statements: If the problem is not clearly articulated, it becomes difficult to track progress or determine success. A vague problem, like “improve user experience,” leaves too much room for interpretation and may lead to irrelevant model designs.
Overcomplicating the Problem: Sometimes, people try to create overly complex models when simpler approaches may suffice. Starting with a straightforward problem definition and iterating from there allows for easier validation and troubleshooting.
Example: If the goal is to reduce customer churn, your problem definition might be: “Predict customers likely to cancel their subscriptions in the next 30 days.”
Also Read: How to Train an AI?
Data Collection: The Fuel for Machine Learning Models
Once the problem has been clearly defined in the machine learning (ML) lifecycle, the next crucial step is data gathering. Data serves as the foundation upon which machine learning models are built, making it one of the most critical components of any AI project. The quality and quantity of data directly affect the performance, reliability, and accuracy of the model.
In the landscape of 2025, data is more abundant and varied than ever before. This sheer volume can present both opportunities and challenges. To navigate this effectively, it’s essential to source data from the right channels, understand how it will be used in the model, and ensure that it’s clean, relevant, and representative of the real-world scenario you aim to predict or classify.
Key Data Sources for Machine Learning
There are multiple ways to gather data for machine learning, and the method you choose depends on the problem you’re solving, the industry you’re in, and the specific needs of your model.
Internal Databases: Leveraging Existing Business Data
Internal databases are often the first and most reliable source of data for machine learning models. Companies generate vast amounts of structured data through their regular operations, including customer records, transaction history, sales figures, and inventory data.
Examples:
CRM Systems: Customer relationship management platforms store a wealth of information, such as demographic details, purchase behavior, and engagement history.
Enterprise Resource Planning (ERP): Includes operational data such as financials, employee data, and resource management.
Transactional Data: Includes e-commerce transactions, point-of-sale data, and website interactions, providing rich insights into customer behavior.
Advantages:
The data is readily available within your organization.
It is highly relevant to your business problem, ensuring that the model is grounded in real-world scenarios.
Challenges:
Data Silos: Different departments may store data in various formats, making it difficult to consolidate.
Data Privacy Concerns: Sensitive customer data needs to be handled in compliance with regulations like GDPR.
External APIs: Sourcing Public Data
External APIs (Application Programming Interfaces) provide access to a variety of data sources that can supplement internal data. APIs allow you to collect public data from third-party services, such as social media platforms, financial services, or government databases.
Examples:
Social Media Data: Twitter, Facebook, or LinkedIn APIs can provide insights into customer sentiment, preferences, and trends.
Weather APIs: APIs that provide real-time and historical weather data, useful for sectors like agriculture, transportation, or retail.
Financial Data APIs: Access to financial data like stock prices, market trends, or company performance reports through services such as Alpha Vantage or Quandl.
Advantages:
Provides rich, real-time data that may not be captured internally.
Can be used to enhance models by adding external factors (e.g., weather data for predicting sales).
Challenges:
Data Consistency: Data from third-party APIs may have varying formats, and you need to ensure that it’s aligned with your internal data.
Access Limitations: Some APIs may have rate limits or access restrictions, or charge fees for usage.
Web Scraping: Extracting Data from Websites
Web scraping involves extracting data from websites and online resources, especially for specialized needs where other data sources may be unavailable. Scraping can be a useful technique for gathering publicly available information from the web, such as market prices, product reviews, or news articles.
Examples:
Product Pricing: Scraping online retail websites to monitor competitor pricing strategies.
Job Market Data: Scraping job boards to gather data about employment trends and salaries.
News Articles and Blogs: Collecting data about current events, which can be used for sentiment analysis or market research.
Advantages:
Provides access to a vast amount of publicly available data.
Useful for gathering real-time information on specific topics.
Challenges:
Legality and Ethics: Web scraping can violate terms of service agreements, so it is essential to review the website’s legal guidelines before scraping data.
Data Quality: Data scraped from the web may be noisy or incomplete, requiring additional cleaning and preprocessing.
Surveys and User Feedback: Collecting Primary Data
Surveys and direct user feedback are excellent sources for gathering primary data. In cases where internal or external data isn’t sufficient, creating surveys or collecting user feedback can provide valuable insights directly from your target audience.
Examples:
Customer Satisfaction Surveys: Collecting data on customer experiences to improve services or products.
User Experience Research: Gathering feedback about the usability of websites, apps, or software platforms.
Market Research: Understanding consumer preferences and behaviors through tailored surveys.
Advantages:
Customizable Data: You can design surveys to gather exactly the data you need.
Targeted Audience: You can select specific groups to survey, ensuring the data is relevant to your problem.
Challenges:
Survey Bias: Poorly designed questions or a skewed sample of respondents can lead to biased results.
Low Response Rates: It can be challenging to get enough responses to make meaningful conclusions.
Also Read: What Are Machine Learning Models
Data Preprocessing: Cleaning the Raw Data
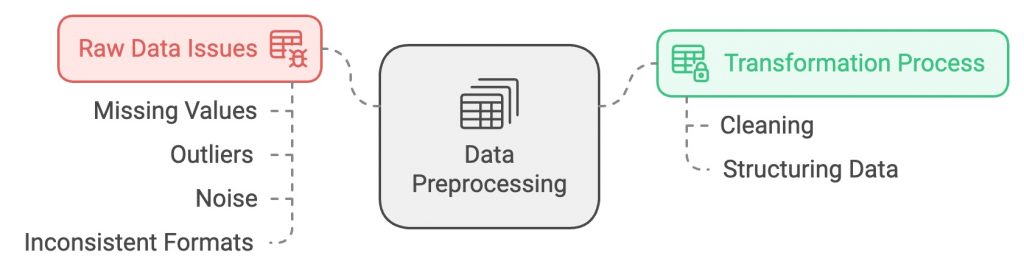
In machine learning, data preprocessing is one of the most crucial stages of the lifecycle, and it often takes up a significant portion of the overall project timeline. While gathering raw data is important, it’s rarely in the right format to be used directly for training machine learning models. Raw data often contains missing values, outliers, noise, and inconsistent formats that need to be cleaned and transformed into a structured, usable form. The process of transforming raw data into something that the model can learn from is what we call data preprocessing.
Why Data Preprocessing Is Crucial
Machine learning models depend on the quality of the data they are trained on. If the data is noisy, incomplete, or improperly formatted, the model will struggle to make accurate predictions or generalizations. The accuracy and generalization ability of a model depend heavily on how well the preprocessing step is handled. Think of data preprocessing as setting the stage for the model to learn effectively.
Key Reasons Why Data Preprocessing Is Important:
Quality of Data Affects Model Accuracy:
Poor-quality data can lead to models that underperform or fail to make accurate predictions. For instance, if data contains duplicate records or irrelevant information, it can confuse the model during training.
Consistency Is Essential for Accurate Learning:
Machine learning models rely on consistent and structured data. Inconsistent data formats (e.g., different date formats or missing values) can create confusion and cause the model to make inaccurate predictions.
Ensures Data is Interpretable by the Model:
Not all types of raw data are suitable for machine learning algorithms. Preprocessing ensures that the data is in the right format for the model to process and learn from effectively.
Improves Model Generalization:
Proper preprocessing helps the model generalize better by ensuring that it focuses on the most relevant features, avoiding overfitting to noise or irrelevant patterns in the data.
Steps Involved in Data Preprocessing
The process of data preprocessing can be broken down into several key steps, each focusing on a specific aspect of cleaning, transforming, and structuring the data:
Handling Missing Data:
One of the first issues to address in data preprocessing is missing data. Data can be incomplete for several reasons, such as incorrect data entry, system errors, or non-response in surveys. If left unchecked, missing data can skew model predictions and lead to biased outcomes.
Common Methods for Handling Missing Data:
Imputation: Replacing missing values with statistical values such as the mean, median, or mode, or using more complex imputation techniques like K-nearest neighbors (KNN).
Deletion: Removing rows or columns that contain missing values, especially when the missing data is too substantial to impute effectively.
Predictive Models: Using machine learning algorithms to predict and fill in missing values based on the relationships found in the data.
Removing Duplicates:
Duplicated records are common, especially in large datasets, and they can distort the model’s learning process by inflating certain features or values.
Approach to Handle Duplicates:
Identify duplicate rows and either remove them or aggregate the values depending on the context. For example, if duplicate transactions exist in sales data, they may need to be summed or averaged.
Handling Outliers:
Outliers are extreme values that deviate significantly from the other data points in the dataset. While outliers can sometimes represent important insights, they can also distort model predictions and lead to overfitting.
Techniques for Managing Outliers:
Removing Outliers: In some cases, outliers are simply mistakes or errors that can be removed without any loss of valuable information.
Transformation: Applying transformations, such as log transformations or scaling, can help reduce the impact of outliers on the overall dataset.
Winsorization: Replacing outliers with the nearest acceptable value to reduce their impact.
Data Transformation:
Once the data is cleaned, it often needs to be transformed into a format that’s suitable for the machine learning model. This includes scaling numerical data, encoding categorical variables, and feature engineering.
Normalization and Standardization:
Normalization scales data to a fixed range, usually between 0 and 1. This is especially important when working with distance-based models (e.g., k-nearest neighbors, support vector machines).
Standardization transforms the data to have a mean of 0 and a standard deviation of 1, which helps models that assume normally distributed data (e.g., linear regression).
Encoding Categorical Data:
Many machine learning algorithms can only process numerical data. Categorical variables (e.g., product type, gender, or region) need to be transformed into numerical form using techniques like:
One-Hot Encoding: Creating binary columns for each category in a variable.
Label Encoding: Assigning each category a unique number.
Feature Engineering:
Feature engineering is the process of creating new features or modifying existing ones to improve model performance. For example, in a time-series problem, creating additional features like the day of the week or month might help improve the model’s ability to capture seasonal patterns.
Handling Imbalanced Data:
In many real-world datasets, one class (e.g., fraud or churn) might be underrepresented compared to others. An imbalanced dataset can cause machine learning models to favor the majority class and ignore the minority class.
Techniques to Address Imbalance:
Resampling: Techniques like oversampling the minority class or undersampling the majority class to balance the dataset.
Synthetic Data Generation: Using algorithms like SMOTE (Synthetic Minority Over-sampling Technique) to generate synthetic examples of the minority class.
Class Weights: Modifying the algorithm to pay more attention to the minority class by assigning it higher class weights.
Data Augmentation:
In some cases, particularly with image, audio, and text data, you may have limited data. Data augmentation is a technique that artificially increases the size of the training dataset by applying random transformations such as rotations, translations, or cropping (for images) to generate new training examples.
Examples of Data Augmentation:
Image Data: Rotating, flipping, or changing the brightness of images.
Text Data: Adding synonyms, rephrasing sentences, or translating text between languages and back.
Audio Data: Adding noise or changing the pitch or speed of audio clips.
Data Splitting:
Before training a machine learning model, the data should be split into training, validation, and test sets to evaluate the model’s performance.
Training Set: The portion of the data used to train the model.
Validation Set: A smaller subset used to tune hyperparameters and evaluate the model’s performance during training.
Test Set: Data that the model hasn’t seen before, used to assess the final performance and generalization ability.
Common Preprocessing Tasks:
- Handling Missing Data: Fill in missing values or remove rows/columns with missing data.
- Data Transformation: Normalize or standardize numerical values to ensure consistency.
- Data Encoding: Convert categorical variables (e.g., product types, regions) into numerical formats using techniques like one-hot encoding or label encoding.
- Outlier Detection: Identify and address outliers that could skew your model.
Why It Matters:
- Good preprocessing ensures that the model won’t overfit to noisy or inconsistent data.
- Clean data helps the model learn patterns and relationships that will generalize to new, unseen data.
Also Read: How to get started with machine learning
Feature Engineering: Selecting the Right Variables
Feature engineering is a critical step in the machine learning lifecycle, involving the process of selecting, modifying, or creating new features from raw data. In essence, it is about transforming the data into a form that best represents the underlying patterns needed for predictive models. By choosing or creating relevant features, data scientists ensure that machine learning algorithms can effectively capture the relationships in the data. For instance, in a housing price prediction model, creating a feature that combines the square footage and the number of bedrooms might provide more valuable insights than using them separately. This process helps reduce the model’s complexity while enhancing its ability to make accurate predictions.
Well-chosen features not only improve the model’s performance but also significantly reduce its training time. Irrelevant or redundant features, on the other hand, can severely hinder model accuracy by introducing noise or causing overfitting. For example, including highly correlated features (such as income and wealth) can cause the model to place too much emphasis on similar patterns, leading to a less generalizable model. This redundancy complicates the model without adding meaningful value. Through effective feature engineering, unnecessary complexity is removed, allowing the model to focus on the most important aspects of the data.
One of the most important aspects of feature engineering is feature extraction, which involves creating new features that might not be present in the raw data but are more useful for the model. This could involve combining several existing features to create new ones or performing mathematical transformations to better capture the relationships within the data. For instance, in time series data, extracting features like the day of the week or month from a timestamp can provide valuable information about patterns that repeat periodically. Similarly, in natural language processing, transforming raw text data into word counts or embedding vectors helps capture semantic meaning, enabling the model to learn from text in a structured manner.
Feature engineering is not a one-time task. As the model is developed and deployed, it’s important to iteratively refine the features based on model feedback and performance. The effectiveness of features may change as new data becomes available or as the model is fine-tuned. Continuous improvement and adjustment are crucial for ensuring the model remains accurate over time. Additionally, automated techniques like feature selection algorithms or dimensionality reduction methods (such as PCA) can be used to identify and retain the most important features, further enhancing model efficiency and performance. In short, feature engineering is a dynamic and ongoing process that plays a pivotal role in the success of machine learning projects.
Steps in Feature Engineering:
Feature Selection: Identifying which variables are most predictive for the target variable.
Feature Extraction: Creating new features by combining or transforming existing ones. For example, from a date column, you might create additional features like “day of the week” or “time of day.”
Dimensionality Reduction: Using methods like PCA (Principal Component Analysis) to reduce the number of features while retaining essential information.
Model Selection: Picking the Right Algorithm
Selecting the right machine learning algorithm is one of the most critical decisions in the ML lifecycle. The algorithm determines how your model will learn from data and ultimately how it will perform in making predictions or classifying new data. The choice of algorithm can significantly impact the efficiency, accuracy, and scalability of your model. There is no one-size-fits-all approach; the most appropriate algorithm depends on several factors, including the nature of the problem, the type of data available, and the desired outcome. Understanding the strengths and limitations of different algorithms is essential to making the right choice and building a model that solves the problem effectively.
The most common categories of machine learning algorithms are supervised learning, unsupervised learning, and reinforcement learning. Supervised learning is typically used when the dataset contains labeled data, meaning that the input features and the corresponding output labels are both known. This type of algorithm is most commonly used for classification and regression tasks, such as predicting whether an email is spam (classification) or forecasting the price of a house based on various features (regression). Examples of supervised learning algorithms include decision trees, support vector machines (SVM), and linear regression. The primary advantage of supervised learning is that the model can learn directly from the labeled data, which usually leads to high accuracy when enough quality data is available.
In contrast, unsupervised learning is used when the dataset lacks labeled output data. Instead of predicting or classifying an outcome, unsupervised learning algorithms aim to find hidden patterns or groupings within the data. For example, in clustering tasks, an algorithm like k-means might be used to group customers into segments based on purchasing behavior. Similarly, dimensionality reduction algorithms like Principal Component Analysis (PCA) help reduce the number of features in the dataset, making it easier to visualize and analyze. The challenge with unsupervised learning is that since there are no labeled outcomes to guide the model, it requires more experimentation to determine the best algorithm and approach for finding the most meaningful insights.
Reinforcement learning is a more advanced approach that falls outside the typical supervised or unsupervised learning paradigms. In reinforcement learning, an agent learns to make decisions through trial and error, interacting with its environment to maximize a reward. This type of learning is often used in areas like robotics, game playing (e.g., AlphaGo), and autonomous vehicles. Reinforcement learning algorithms like Q-learning or Deep Q-Networks (DQN) enable models to learn strategies by receiving feedback from the environment in the form of rewards or penalties. While it can be highly effective in complex decision-making tasks, reinforcement learning typically requires large amounts of computational power and data to train effectively, which makes it more resource-intensive than supervised or unsupervised learning.
The key to choosing the right algorithm is understanding the problem at hand and the type of data available. For example, if you’re working with labeled data and need to classify or predict outcomes, supervised learning algorithms are likely the best choice. If your goal is to uncover hidden patterns or groupings in data without predefined labels, unsupervised learning is more appropriate. On the other hand, if your project involves dynamic decision-making based on rewards and penalties, reinforcement learning will be the most effective approach. In all cases, evaluating the trade-offs between different algorithms and continuously testing and refining your approach is essential to building an efficient, accurate machine learning model.
Types of Machine Learning Models:
Supervised Learning: For tasks where data has labels. Algorithms include linear regression, decision trees, and random forests.
Unsupervised Learning: For tasks without labels, such as clustering (e.g., k-means) or dimensionality reduction.
Reinforcement Learning: For tasks where an agent interacts with an environment to maximize rewards (e.g., for robotics or game-playing).
Evaluation Criteria:
Model Complexity: Simple models may be faster but less accurate. Complex models may be accurate but prone to overfitting.
Training Time: Some algorithms take longer to train on large datasets.
Interpretability: In some cases, simpler models like decision trees are easier to interpret than complex models like deep neural networks.
Model Training: Teaching the AI
Once the machine learning algorithm has been selected, the next crucial step in the ML lifecycle is training the model. This phase is where the real magic happens: the model learns from the data and adjusts its internal parameters to make accurate predictions. The purpose of model training is to allow the algorithm to discover patterns, trends, and relationships within the data that can later be applied to unseen or new data. Training involves feeding the model with a large set of labeled data (for supervised learning) or unlabeled data (for unsupervised learning) and enabling it to learn from that data through iterative processes. This is often the most computationally intensive part of the process and requires careful management of data, hardware resources, and model tuning.
Training a machine learning model is essentially about optimization — adjusting the parameters (or weights) within the model to minimize prediction errors. The most common approach to optimization in machine learning is gradient descent, an algorithm used to minimize the error by iteratively adjusting the model’s parameters in the direction that decreases the loss function (the function that measures how far the model’s predictions are from the actual values). Gradient descent uses the concept of the gradient, which is a vector that points in the direction of the steepest increase in the loss function. By moving in the opposite direction of the gradient, the algorithm minimizes the loss function and gradually improves the model’s accuracy.
There are different variations of gradient descent that can be used depending on the nature of the problem and the data at hand. Batch gradient descent processes the entire dataset before updating the parameters, while stochastic gradient descent (SGD) updates the parameters more frequently, using only one data point at a time. This can make SGD faster, but it introduces more noise into the process, potentially leading to less stable convergence. Mini-batch gradient descent combines the advantages of both, updating parameters using small batches of data, which allows for faster convergence while reducing the noise. The choice of gradient descent technique depends on the dataset size and the model’s complexity, with trade-offs between speed and accuracy.
The process of model training is not just about reducing errors but also about finding the optimal balance between underfitting and overfitting. Underfitting occurs when the model is too simple to capture the underlying patterns in the data, while overfitting happens when the model becomes too complex, capturing noise and irrelevant details that don’t generalize well to new data. To address this, machine learning practitioners often use techniques such as regularization (which adds a penalty term to the loss function to prevent overfitting) and cross-validation (which tests the model on different subsets of the data to ensure it generalizes well). During training, it’s essential to regularly assess the model’s performance and make adjustments as needed to strike the right balance, ensuring that the model can learn the general patterns of the data while avoiding the pitfalls of overfitting or underfitting.
Training a model is an iterative process, and it’s important to monitor the learning progress throughout. As the model adjusts its parameters, it’s essential to track its performance on both the training and validation datasets. Over time, the model will learn to make predictions with decreasing error rates, but this process can take a considerable amount of time depending on the algorithm’s complexity and the size of the data. In some cases, early stopping is used to prevent excessive training, halting the process when further training no longer results in significant improvement. Once the model has successfully learned from the data, it is ready for the next phase — evaluation — where its effectiveness will be tested on new, unseen data.
Key Considerations:
Overfitting vs. Underfitting: Striking the balance between a model that’s too complex (overfits) and too simple (underfits) is essential for effective training.
Cross-Validation: Use techniques like k-fold cross-validation to evaluate the model on unseen data during training.
Hyperparameter Tuning: Optimizing the model’s parameters (e.g., learning rate, number of trees in random forest) can significantly impact performance.
Also Read: PCA-Whitening vs ZCA Whitening: What is the Difference?
Model Evaluation: Testing for Accuracy
Once a machine learning model has been trained, the next critical step is model evaluation. This phase involves testing the model’s performance to determine how well it generalizes to new, unseen data. Training the model is only part of the journey — ensuring that the model can apply the knowledge it has gained to predict or classify new data accurately is what ultimately makes it valuable. Without a proper evaluation, it’s impossible to know whether the model will perform well in real-world scenarios or if it will fail when exposed to new data. The goal of model evaluation is to assess how effectively the model has learned from the training data and whether it is capable of making predictions on new, previously unseen examples.
Model evaluation typically involves comparing the model’s predictions with the actual outcomes using a range of performance metrics. For classification tasks, common evaluation metrics include accuracy, precision, recall, and F1-score. Accuracy measures the proportion of correct predictions, but it may not be sufficient, especially when the data is imbalanced. In cases where one class is much more frequent than others, precision and recall provide a more nuanced view. Precision measures the accuracy of positive predictions, while recall focuses on how well the model identifies all relevant instances of the positive class. The F1-score is the harmonic mean of precision and recall, balancing both metrics and providing a more comprehensive evaluation when working with imbalanced data.
For regression tasks, the evaluation metrics differ, focusing on the model’s ability to predict continuous outcomes. Metrics like mean squared error (MSE), root mean squared error (RMSE), and mean absolute error (MAE) are used to quantify how far off the model’s predictions are from the actual values. These metrics help determine how well the model can approximate real-world values, with lower values indicating better model performance. In addition to these standard metrics, cross-validation is often employed to provide a more robust evaluation by testing the model on multiple subsets of the data. This helps ensure that the model is not overfitting to a particular part of the training data and that it performs well on different data splits. Evaluating a model thoroughly is essential to ensure that it not only performs well on the training data but also generalizes effectively to new, unseen data, making it ready for deployment.
Evaluation Metrics:
Accuracy: The percentage of correct predictions.
Precision and Recall: Important for classification tasks, particularly when class imbalance exists.
F1 Score: The harmonic mean of precision and recall, giving a balanced view of the model’s performance.
Why It Matters:
Evaluation helps to identify if the model is underfitting, overfitting, or generalizing well to new data.
Proper evaluation ensures that the model will perform effectively in real-world scenarios.
Model Deployment: Taking It Live
After a machine learning model has been thoroughly trained and evaluated, the next critical phase is deployment. Deployment is the process of integrating the model into the operational or business environment, where it can begin to provide real-time predictions, automate processes, or make decisions that drive value. This step transforms the model from a theoretical concept into a functional tool that can actively influence business outcomes. Whether it’s recommending products to customers on an e-commerce site, detecting fraudulent transactions in real-time, or optimizing supply chain logistics, deployment ensures that the model is actively serving its intended purpose.
Once the model is deployed, it typically starts providing real-time predictions based on incoming data, which is used to inform decisions or automate certain tasks. For example, a model deployed for customer churn prediction can continuously monitor customer behavior, identify at-risk customers, and trigger retention strategies. A deployed fraud detection model might analyze transactions as they occur, flagging suspicious activity for further review. The value of a deployed model comes from its ability to perform these tasks autonomously, improving efficiency, reducing human intervention, and providing insights in real-time. Integration with existing systems is crucial at this stage, as the model needs to communicate effectively with databases, APIs, and other business processes.
Deployment is not a one-time event but an ongoing process that involves continuous monitoring and updating of the model. After deployment, the model’s performance should be continuously tracked to ensure that it is operating correctly and providing accurate results. This is particularly important as the model will be exposed to real-world data that may differ from the training data. Over time, models can become outdated if they are not updated to reflect new trends, patterns, or changes in the data. Model drift, where the data distribution changes over time, can lead to declining model performance. Regular monitoring helps identify any issues early, allowing for timely adjustments or retraining of the model to maintain its accuracy.
Another key aspect of deployment is scalability. As business needs evolve or as more data becomes available, the deployed model must be able to scale to handle increased volume, complexity, or different types of input. For instance, a recommendation engine that performs well for a few thousand users may need to be scaled to handle millions of users without compromising performance. To achieve this, models are often deployed in cloud-based environments where they can be easily scaled, maintained, and updated. Additionally, model versioning is essential for keeping track of different iterations of the model, ensuring that any changes made after deployment are well-documented and backward-compatible. Successful deployment requires not only technical integration but also a robust plan for maintenance, scaling, and adaptation to changing business needs, ensuring the model continues to deliver value in the long term.
Steps in Deployment:
Integration: Connect the model to other business systems like databases, APIs, or websites.
Monitoring: Track the model’s performance over time to ensure it continues to work effectively as the data evolves.
Automation: Some models need to be retrained periodically with new data to stay relevant.
Model Maintenance: Keeping It Relevant
The machine learning lifecycle does not conclude with deployment; in fact, the post-deployment phase is critical for ensuring that the model continues to deliver value over time. Ongoing model maintenance and iteration are essential for adapting to new challenges, maintaining model accuracy, and responding to changing data. After a model is deployed, it is exposed to real-world conditions that might not have been fully captured during the training phase. Changes in customer behavior, market trends, or even seasonal patterns can impact the model’s ability to provide accurate predictions. Without regular updates and adjustments, models can experience performance degradation over time, leading to suboptimal outcomes.
One of the key components of model maintenance is monitoring. Continuous monitoring ensures that the model’s performance remains consistent with expectations and that any potential issues, such as model drift or data shifts, are detected early. Model drift occurs when the underlying distribution of data changes, making the trained model less effective at predicting outcomes. For example, a fraud detection model trained on historical transaction data may become less accurate as fraud patterns evolve. Monitoring helps identify these issues, triggering retraining processes or adjustments to keep the model aligned with real-world conditions. Effective monitoring includes tracking performance metrics such as accuracy, precision, recall, or any other domain-specific measures that indicate the model’s effectiveness.
Model iteration is closely tied to maintenance and involves revisiting the model periodically to refine or update it. As new data becomes available, the model might need to be retrained or fine-tuned to ensure that it adapts to new trends, behaviors, or environmental changes. Retraining can involve incorporating fresh data, using it to update the model’s weights or parameters, and potentially reengineering features to capture more relevant aspects of the problem. For instance, a customer segmentation model used by a retailer may need to be iterated upon as consumer preferences evolve or as new products are introduced. Iteration doesn’t just improve accuracy but can also help in adapting the model to new problem requirements or business goals, ensuring that it remains effective and relevant over time.
Scalability and deployment flexibility are crucial when iterating on the model. As models evolve and improve, they may need to scale to accommodate growing datasets or an expanding user base. For example, if a deployed model is handling millions of requests per day, scaling it to meet increased demand while maintaining efficiency is essential. Additionally, version control becomes increasingly important as the model undergoes multiple iterations. Each version of the model needs to be carefully managed, ensuring that older versions are archived and that newer versions are properly deployed and tested. With effective version control, teams can easily roll back to previous iterations if an update results in degraded performance, offering flexibility and control over the model’s lifecycle. Through consistent maintenance and iteration, machine learning models can continue to provide high-quality, relevant insights long after deployment.
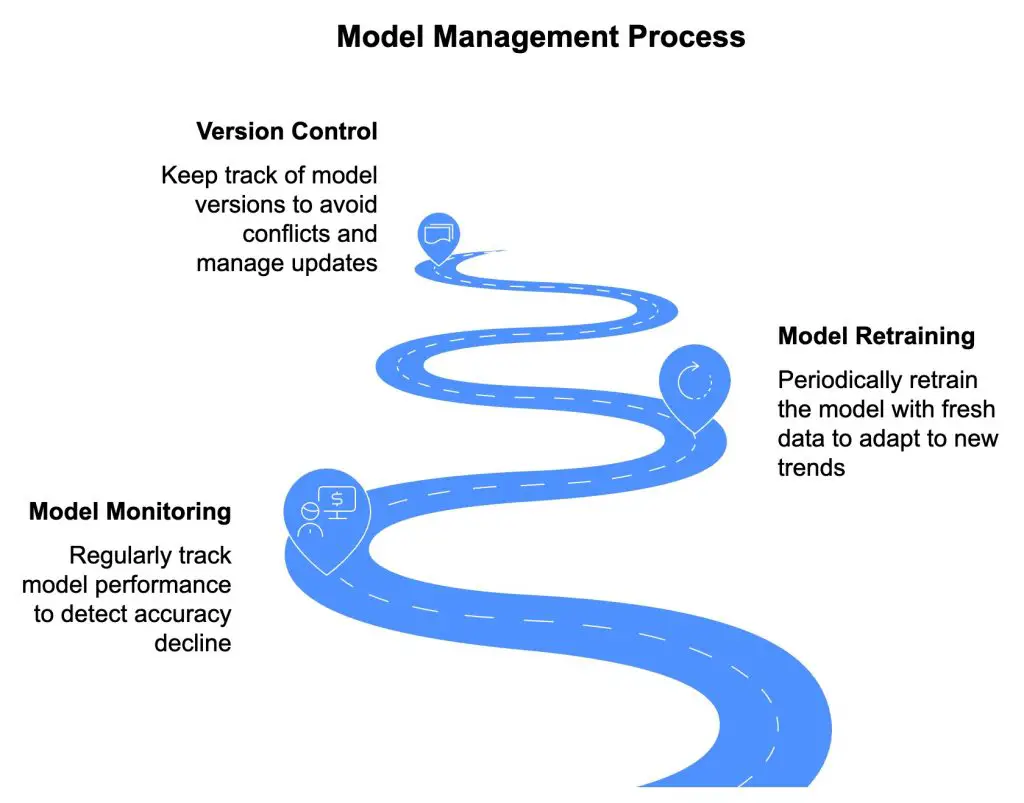
Maintenance Activities:
Model Monitoring: Track model performance regularly to detect any decline in accuracy.
Model Retraining: Retrain the model periodically with fresh data to adapt to new trends or patterns.
Version Control: Keep track of model versions to avoid conflicts and ensure updates are properly managed.
Conclusion: Navigating the ML Lifecycle for Success
The machine learning lifecycle is a comprehensive, multi-step process that requires careful attention to detail at each stage, from problem definition through to deployment and continuous maintenance. Each phase plays a crucial role in ensuring that the model performs effectively and delivers value. Starting with clearly defining the problem, the process moves through collecting and preprocessing data, selecting the right algorithms, training the model, evaluating its performance, and finally, deploying it for real-world use. The work doesn’t stop there — ongoing maintenance and iteration are vital to ensuring that the model continues to perform accurately as conditions change. By understanding and meticulously following the machine learning lifecycle, organizations can develop models that are not only powerful in solving complex problems but also reliable in delivering consistent performance and scalable to meet evolving business needs.
Machine learning is far more than just an automation tool — it has become a key driver of innovation across industries. By enabling machines to learn from data and make decisions, machine learning allows businesses to optimize operations, uncover hidden patterns, and create personalized experiences at scale. Whether it’s in healthcare, finance, marketing, or logistics, machine learning is transforming the way organizations interact with data and solve real-world challenges. It’s no longer just about automating repetitive tasks — it’s about creating intelligent systems that can enhance decision-making, predict future outcomes, and drive innovation across all areas of business. As machine learning technologies continue to advance, their potential to innovate and disrupt industries will only grow, making it essential for businesses to understand and leverage the full lifecycle of machine learning.
References
Agrawal, Ajay, Joshua Gans, and Avi Goldfarb. Prediction Machines: The Simple Economics of Artificial Intelligence. Harvard Business Review Press, 2018.
Siegel, Eric. Predictive Analytics: The Power to Predict Who Will Click, Buy, Lie, or Die. Wiley, 2016.
Yao, Mariya, Adelyn Zhou, and Marlene Jia. Applied Artificial Intelligence: A Handbook for Business Leaders. Topbots, 2018.
Murphy, Kevin P. Machine Learning: A Probabilistic Perspective. MIT Press, 2012.
Mitchell, Tom M. Machine Learning. McGraw-Hill, 1997.