Introduction
The terms deep learning and artificial intelligence appear in headlines, boardroom discussions, and product marketing materials with growing frequency, yet most people use them interchangeably without understanding what separates one from the other. Deep learning is not a synonym for artificial intelligence; it is a specialized subset that sits within a layered hierarchy of technologies stretching from rule-based expert systems all the way down to multi-layered neural networks. According to Mordor Intelligence’s 2026 market report, the global deep learning market was valued at $47.89 billion in 2025 and is projected to reach $296.23 billion by 2031, registering a compound annual growth rate of 35.48 percent. That explosive trajectory signals a technology that has moved far beyond academic research labs and into production-grade enterprise systems. Understanding the boundary between deep learning and the broader field of AI is essential for anyone evaluating technology investments, building data teams, or simply trying to keep pace with the most consequential shift in computing since the internet. This article unpacks how deep learning works, where it fits inside the larger AI ecosystem, and why the distinction matters for practitioners and decision-makers alike.
Quick Answers on Deep Learning and AI
What is deep learning in simple terms?
Deep learning is a branch of machine learning that uses layered neural networks to automatically learn patterns from large datasets, enabling tasks like image recognition and language translation without manual feature engineering.
Is deep learning the same as artificial intelligence?
Deep learning is not the same as AI. Artificial intelligence is the broad discipline of creating intelligent systems, while deep learning is a specific technique within AI that relies on multi-layered neural networks to solve complex problems.
Why does the distinction between deep learning and AI matter?
Confusing deep learning with AI leads to unrealistic expectations, misallocated budgets, and poor vendor evaluations. Knowing the hierarchy helps organizations select the right tool for each business problem.
Key Takeaways
- Responsible deployment demands attention to algorithmic bias, data privacy, model transparency, and the environmental cost of training large-scale neural networks.
- Deep learning is a subset of machine learning, which is itself a subset of artificial intelligence; the three terms are related but not interchangeable.
- Neural networks with multiple hidden layers give deep learning its “depth,” enabling it to learn hierarchical features from raw data without human-crafted rules.
- The deep learning market is expanding at a 35.48 percent CAGR, driven by adoption in healthcare, autonomous vehicles, finance, and natural language processing.
Understanding Deep Learning in Simple Terms
Deep learning is a method of teaching computers to recognize patterns by processing data through multiple layers of interconnected mathematical functions called neurons. Each layer in a deep learning network transforms the input it receives, extracting progressively more abstract features before producing a final output such as a classification, prediction, or generated text. A beginner’s guide to artificial intelligence will typically describe AI as the broad goal of making machines intelligent, and deep learning as one of the most powerful tools for achieving that goal. The word “deep” refers not to philosophical complexity but to the literal depth of the network, meaning the number of hidden layers stacked between the input and the output. Shallow networks with one or two hidden layers can handle simpler tasks, but it is the addition of many layers that allows deep learning models to capture intricate relationships in images, audio, and text. This layered architecture is what separates deep learning from earlier machine learning approaches that required human experts to manually identify and engineer the features a model should pay attention to.
Deep Learning Readiness Calculator
Evaluate whether your project needs deep learning, traditional ML, or rule-based AI. Adjust the sliders to match your scenario.
Your Project Parameters
The simplest analogy is a factory assembly line where each station performs a specialized task and passes its output to the next station. In a deep learning network, the first layers might detect edges and simple shapes in an image, the middle layers combine those shapes into recognizable parts like eyes or wheels, and the final layers assemble those parts into a classification such as “cat” or “truck.” This hierarchical feature extraction is the core reason deep learning has outperformed traditional algorithms on tasks involving unstructured data. Each layer’s output becomes the next layer’s input, creating a chain of increasingly sophisticated representations that no human programmer could realistically hand-code. The process of adjusting the connections between neurons so that the network produces accurate outputs is called training, and it relies on a mathematical technique known as backpropagation. During training, the network compares its predictions against known correct answers and then adjusts its internal weights to reduce the error, repeating this cycle across millions of data points. The result is a model that can generalize to new, unseen data with remarkable accuracy.
Deep learning’s practical significance becomes clear when you consider the types of problems it solves that were previously intractable for computers. Speech recognition systems that power virtual assistants, real-time language translation tools, and medical imaging diagnostics that rival the accuracy of experienced radiologists all rely on deep learning architectures. Before deep learning, engineers spent years hand-crafting features for each new domain, and even then, performance plateaued on complex tasks involving images, audio, or natural language. The breakthrough came when researchers demonstrated that sufficiently deep networks, given enough data and computing power, could learn those features on their own. Organizations exploring machine learning vs deep learning differences will find that the dividing line often comes down to whether the task demands automatic feature extraction from raw, unstructured data. That capability is precisely what makes deep learning the engine behind the most visible AI products of the past decade.
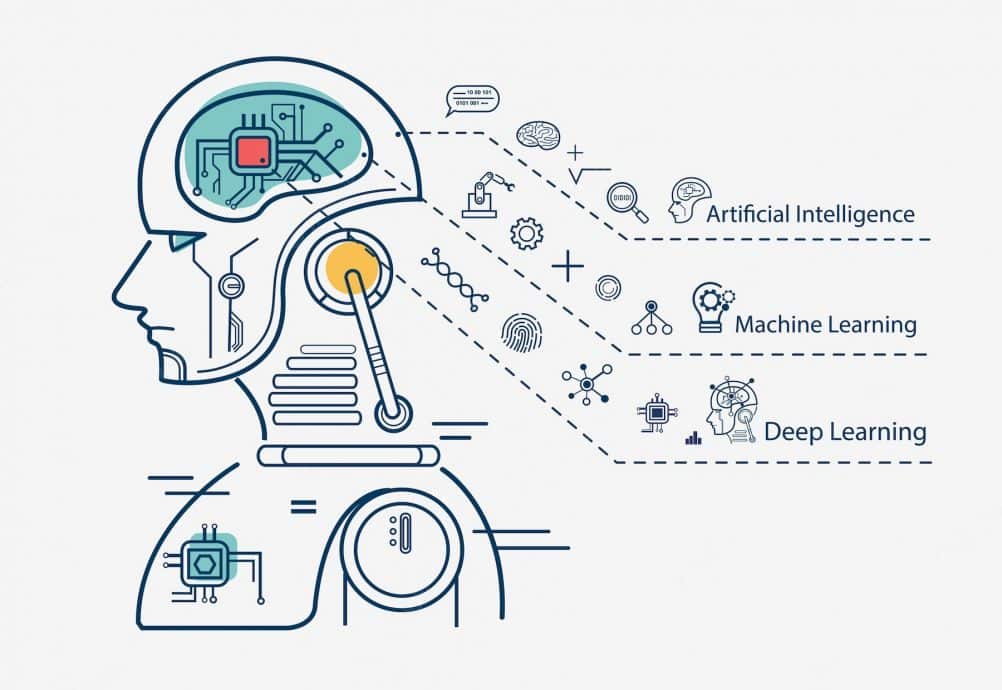
The AI, Machine Learning, and Deep Learning Hierarchy
Artificial intelligence is the broadest category, encompassing every technique designed to give machines the ability to perform tasks that normally require human intelligence. AI includes rule-based expert systems, search algorithms, probabilistic reasoning, and evolutionary computing, many of which predate modern neural networks by decades. Machine learning is a subset of AI that focuses specifically on algorithms capable of improving their performance by learning from data rather than being explicitly programmed for every scenario. Within machine learning, deep learning occupies a further specialized niche, using multi-layered neural networks to learn representations of data at multiple levels of abstraction. This nested hierarchy means that all deep learning is machine learning and all machine learning is AI, but the reverse is not true. Understanding machine learning theory and algorithms is essential before diving into deep learning, because the foundational concepts of training, validation, overfitting, and generalization apply across all three layers.
The confusion between these terms often arises because marketing materials and news outlets use “AI” as a catch-all label for any intelligent software, regardless of the underlying technique. A chatbot running on a simple decision tree is AI, but it is not deep learning. A spam filter using logistic regression is machine learning, but it is not deep learning. A self-driving car’s perception system analyzing live camera feeds through convolutional neural networks is all three: AI, machine learning, and deep learning simultaneously. The practical implication for organizations is that selecting the right level of technology for a given problem can save significant time, money, and computational resources. Not every business problem requires a deep learning model; some are better served by classical machine learning or even rule-based logic. The hierarchy is not a ladder of superiority but a spectrum of complexity, where each layer adds capability at the cost of increased data requirements, computational demands, and interpretability challenges.
How Neural Networks Power Deep Learning
Neural networks are the foundational architecture that makes deep learning possible, consisting of interconnected layers of artificial neurons that process data in a forward pass from input to output. Each neuron receives one or more inputs, multiplies each input by a learned weight, sums the results, applies a nonlinear activation function, and passes the output to neurons in the next layer. The activation function is critical because it introduces the nonlinearity that allows neural networks to model complex, curved relationships in data rather than being limited to straight-line approximations. Without nonlinear activation, stacking additional layers would yield no benefit, as the entire network would collapse into a single linear transformation regardless of its depth. Common activation functions include the rectified linear unit (ReLU), the sigmoid function, and the hyperbolic tangent, each offering different mathematical properties suited to specific tasks. The combination of weighted sums and nonlinear activations, repeated across dozens or even hundreds of layers, gives deep learning models their extraordinary capacity to approximate virtually any function.
Training a neural network requires a dataset of labeled examples, a loss function that quantifies how far the network’s predictions are from the correct answers, and an optimization algorithm that adjusts the weights to minimize that loss. The most widely used optimization approach is stochastic gradient descent, which computes the gradient of the loss function with respect to each weight and then nudges the weights in the direction that reduces the error. Backpropagation is the mathematical technique that efficiently computes these gradients by propagating error signals backward through the network, layer by layer. Modern training pipelines also incorporate techniques like learning rate scheduling, batch normalization, and dropout regularization to stabilize the training process and prevent the network from memorizing the training data rather than learning generalizable patterns. The entire process can take hours, days, or even weeks depending on the size of the dataset, the depth of the network, and the available hardware. Organizations that invest in top machine learning algorithms quickly discover that deep learning training demands GPU or TPU acceleration to remain practical at scale.
The architecture of a neural network determines what kinds of patterns it can efficiently learn, and researchers have developed specialized designs for different data types. Convolutional neural networks excel at spatial data like images and video, recurrent neural networks handle sequential data like time series and text, and transformer architectures have revolutionized language modeling and generative AI. Each of these designs imposes a structural bias that helps the network learn relevant features more efficiently than a generic fully connected architecture. The choice of architecture is one of the most consequential decisions in any deep learning project, directly influencing training speed, model accuracy, and computational cost. Advances in hardware, particularly graphics processing units from NVIDIA and custom tensor processing units from Google, have been essential in making deep neural network training feasible for both research institutions and commercial enterprises. The interplay between network architecture and hardware acceleration defines the practical frontier of what deep learning can accomplish at any given moment.
The output of a trained neural network is a set of weight values, often numbering in the millions or billions, that encode the patterns the network has extracted from the training data. These weights are stored as a model file that can be deployed in production systems to make predictions on new inputs in real time, a process called inference. Inference is typically much faster and less resource-intensive than training, which is why many organizations train models on powerful cloud infrastructure and then deploy them to edge devices or lighter servers for real-time use. Model compression techniques such as quantization, pruning, and knowledge distillation further reduce the computational footprint of inference without significantly sacrificing accuracy. The lifecycle of a deep learning system extends well beyond initial training, requiring ongoing monitoring, retraining on fresh data, and management of model drift. This operational complexity is why deep learning adoption in enterprise environments demands not only data science expertise but also robust engineering infrastructure for model deployment and governance.
Types of Neural Network Architectures
Convolutional neural networks, commonly known as CNNs, are purpose-built for tasks involving spatial data such as images, video frames, and even structured grids like satellite imagery. A CNN applies small, learnable filters across the input, sliding them over the data to detect local patterns such as edges, textures, and shapes in the initial layers and combining them into higher-level features in deeper layers. Pooling layers periodically reduce the spatial dimensions of the data, keeping the computation manageable while preserving the most important information. CNNs achieved their breakthrough moment in 2012 when AlexNet won the ImageNet competition by a dramatic margin, demonstrating that deep convolutional networks could outperform traditional computer vision applications by a significant gap. Since then, architectures like VGGNet, ResNet, and EfficientNet have pushed accuracy even further while introducing design innovations such as skip connections that allow gradients to flow through very deep networks without vanishing. CNNs remain the backbone of modern image classification, object detection, medical imaging analysis, and autonomous vehicle perception systems.
Recurrent neural networks (RNNs) and their more advanced variants, long short-term memory (LSTM) networks and gated recurrent units (GRUs), were designed to process sequential data where the order of inputs carries meaning. Unlike feedforward networks that treat each input independently, RNNs maintain a hidden state that carries information from previous time steps, enabling them to model temporal dependencies in data such as speech, text, and financial time series. LSTMs introduced gating mechanisms that selectively remember or forget information, solving the vanishing gradient problem that made standard RNNs impractical for long sequences. These architectures powered the first generation of effective machine translation systems, speech recognition engines, and text generation tools before being largely superseded by transformers. Organizations working with natural language processing challenges still encounter LSTMs in legacy systems and specific niche applications where sequential processing is preferred over parallel attention mechanisms. The evolution from RNNs to transformers illustrates how architectural innovation can reshape entire subfields within deep learning in a matter of years.
Transformer architectures, introduced in the landmark 2017 paper “Attention Is All You Need,” replaced sequential processing with a parallel self-attention mechanism that allows every element in a sequence to attend to every other element simultaneously. This design eliminated the bottleneck of processing tokens one at a time, enabling transformers to train on vastly larger datasets and produce models with billions of parameters. The transformer is the foundation of large language models such as GPT-4, Claude, and Gemini, and it has also been adapted for computer vision (Vision Transformers), audio processing, and protein structure prediction. Self-attention computes a weighted combination of all input elements for each output, with the weights learned during training, making transformers exceptionally good at capturing long-range dependencies. The scalability of the transformer architecture, combined with the availability of massive text corpora scraped from the internet, catalyzed the generative AI revolution that began in 2022 and continues to accelerate. Understanding transformers is now a prerequisite for anyone working in deep learning, as the architecture underpins the majority of state-of-the-art models across modalities.
Why Deep Learning Needs Massive Amounts of Data
Deep learning models contain millions or billions of adjustable parameters, and fitting those parameters accurately requires correspondingly large volumes of training data to prevent the model from simply memorizing the examples it sees. A model with more parameters than training examples will likely overfit, producing impressive accuracy on the training set but poor performance on new, unseen data. The relationship between model capacity and data requirements is one of the central tensions in deep learning engineering, and it explains why data collection, labeling, and curation consume a substantial share of any deep learning project’s budget and timeline. Data quality matters as much as data quantity, because biased, noisy, or mislabeled training data will produce a model that amplifies those flaws at inference time. Organizations building deep learning systems invest heavily in data pipelines, annotation platforms, and quality assurance processes to ensure that the information feeding their models is representative and accurate. The emergence of self-supervised and semi-supervised learning techniques has partially reduced the dependence on manually labeled data, but large-scale labeled datasets remain the gold standard for most production deep learning applications.
The compute costs associated with training deep learning models on large datasets have made cloud infrastructure and specialized hardware essential components of the deep learning stack. Training GPT-3, for example, was estimated to cost millions of dollars in compute alone, and subsequent models have grown even larger. This economic reality has concentrated cutting-edge deep learning research within a small number of organizations with the resources to afford massive compute budgets, raising concerns about equitable access and the centralization of AI capability. Techniques such as transfer learning and fine-tuning offer a partial remedy, allowing organizations to start with a pre-trained foundation model and adapt it to their specific domain using a much smaller, task-specific dataset. Foundation models trained on broad internet data can be fine-tuned for specialized tasks such as legal document analysis, medical report generation, or customer support automation with a fraction of the compute and data that training from scratch would require. The emergence of fog computing in machine learning and edge deployment strategies is further expanding the ways organizations can run deep learning inference without relying entirely on centralized cloud resources.
Deep Learning vs Machine Learning: Where the Lines Blur
The boundary between deep learning and traditional machine learning is not a hard wall but a gradient, with many practical systems combining elements of both approaches to solve real-world problems. Classical machine learning algorithms such as random forests, gradient-boosted decision trees, and support vector machines excel on structured, tabular data where the relationships between features are relatively well understood. These algorithms require feature engineering, a process in which human experts identify, select, and transform the raw data into a set of informative input variables that the algorithm can learn from effectively. Deep learning eliminates much of this manual feature engineering by learning features directly from raw data, but it pays for that convenience with higher data requirements, longer training times, and reduced interpretability. In many enterprise analytics workflows, gradient-boosted trees outperform deep learning on tabular data while training in minutes rather than hours, making them the practical choice for fraud scoring, churn prediction, and demand forecasting. The skill of a good data scientist lies in knowing when deep learning’s automatic feature extraction justifies its costs and when a simpler model will deliver equivalent or superior results.
Hybrid architectures are becoming increasingly common, with deep learning components handling unstructured data such as images or text and traditional machine learning models processing structured features, all feeding into a combined prediction pipeline. A loan underwriting system, for instance, might use a convolutional neural network to extract information from scanned financial documents and then feed those extracted features into a gradient-boosted tree alongside conventional financial metrics for a final credit decision. This layered approach leverages the strengths of both paradigms: the pattern-extraction power of deep learning and the speed, interpretability, and tabular data proficiency of classical models. As organizations mature in their AI capabilities, the question shifts from “should we use deep learning” to “where in the pipeline does deep learning add the most value.” The distinction between deep learning and broader machine learning is therefore less about competing technologies and more about selecting the right tool for each stage of a complex analytical workflow. Exploring supervised and unsupervised deep learning further clarifies how learning paradigms influence which technique best fits a given problem.
The convergence of deep learning and classical machine learning is also evident in automated machine learning (AutoML) platforms that select and tune models without requiring users to choose between deep and traditional approaches. These platforms evaluate a portfolio of algorithms, including both deep learning and classical options, against the user’s dataset and automatically recommend the best-performing configuration. For organizations without deep data science expertise, AutoML democratizes access to sophisticated modeling techniques and often reveals that the optimal solution is a blended pipeline rather than a single model type. The blurring of lines between deep learning and machine learning reflects a broader trend toward pragmatic, outcome-driven AI engineering rather than ideology-driven allegiance to a single paradigm. As the tooling matures, the distinction will become less visible to end users even as it remains important for the engineers designing and maintaining the underlying systems.
Deep Learning vs Artificial Intelligence: Clearing the Confusion
The most persistent misconception in technology discourse is the conflation of deep learning with artificial intelligence, a mistake that distorts expectations, budgets, and strategic planning. Artificial intelligence, as a discipline, dates back to the 1956 Dartmouth Conference and encompasses everything from symbolic logic and expert systems to evolutionary algorithms, Bayesian networks, and modern neural networks. Deep learning is merely the latest and most visible chapter in that long history, having gained prominence only in the past decade thanks to the convergence of big data, powerful GPUs, and algorithmic breakthroughs. When a CEO announces that the company is “investing in AI,” the investment could range from deploying a simple rule-based chatbot to training a billion-parameter large language model, and the cost, complexity, and organizational impact of those two projects differ by orders of magnitude. Treating deep learning and AI as synonyms leads to the dangerous assumption that every AI initiative requires massive datasets, GPU clusters, and specialized Ph.D. researchers, which is simply not the case. Clarity in terminology allows leaders to match the right technology to the right problem and allocate resources accordingly.
The AI hierarchy also includes narrow AI and the theoretical concept of artificial general intelligence, which adds another layer of confusion when these terms are used loosely. All commercially deployed AI systems today, including deep learning models, fall under the category of narrow AI, meaning they are designed to perform specific tasks within defined boundaries. A deep learning model that classifies skin lesions with high accuracy cannot also write poetry or negotiate a business contract; it is specialized by design. Artificial general intelligence, the hypothetical capability of a machine to perform any intellectual task that a human can, remains an unsolved research challenge with no consensus timeline for achievement. When people hear “AI” and picture a sentient, all-knowing machine, they are imagining AGI, not the deep learning systems that actually exist and operate in the world. This gap between public perception and technical reality is one reason why organizations benefit from using precise terminology when communicating about their AI strategies to stakeholders, customers, and regulators.
Understanding the distinction also matters for regulatory and governance purposes, as different types of AI carry different risk profiles. A deep learning model making autonomous medical diagnoses carries far more regulatory weight than a rule-based system that routes customer service tickets, even though both qualify as AI. The European Union’s AI Act classifies AI systems by risk level, with high-risk applications in healthcare, criminal justice, and critical infrastructure subject to stringent requirements for transparency, documentation, and human oversight. Organizations that conflate deep learning with AI may underestimate the compliance burden of deploying deep learning in regulated domains or overestimate the risk of deploying simpler AI techniques in low-stakes applications. Precise vocabulary is therefore not merely an academic exercise but a practical necessity for navigating the emerging regulatory landscape that governs AI deployment worldwide. The ethics of artificial intelligence demand that practitioners communicate honestly about what their systems can and cannot do.
The economic implications of the distinction extend to hiring, vendor selection, and technology architecture. A company that needs predictive maintenance for factory equipment may find that a well-tuned gradient-boosted model trained on sensor data meets its accuracy requirements without the infrastructure overhead of a deep learning pipeline. Conversely, a company building a product that interprets medical images, generates natural language, or processes spoken commands will almost certainly need deep learning and the associated investment in data, compute, and specialized talent. Mislabeling a project as “AI” when it requires “deep learning” can lead to underbudgeting for hardware and data infrastructure, while mislabeling a straightforward machine learning task as “deep learning” can lead to unnecessary complexity and cost. Strategic clarity begins with terminological precision, and the organizations that draw clean lines between AI, machine learning, and deep learning in their planning documents consistently make better technology decisions. The competitive advantage lies not in using the trendiest label but in deploying the technique that best fits the problem.
How Deep Learning Is Transforming Healthcare
Deep learning is reshaping healthcare by enabling diagnostic accuracy that rivals and in some cases exceeds the performance of experienced clinicians, particularly in medical imaging analysis. Convolutional neural networks trained on millions of annotated medical images can detect tumors, fractures, retinal diseases, and skin conditions with sensitivity and specificity that match board-certified specialists. Google’s DeepMind Health expanded its retinal scan AI in 2025, detecting over 50 eye conditions with 94 percent accuracy, a benchmark that signals the transition from research prototype to clinical-grade tool. Hospitals such as the Mayo Clinic have deployed deep learning models for early cancer detection, reporting measurable reductions in diagnostic turnaround times and improvements in early-stage identification rates. The ability of deep learning to analyze images at pixel-level resolution, continuously and without fatigue, addresses a critical bottleneck in healthcare: the shortage of specialist physicians relative to the growing volume of imaging studies. For a deeper exploration of how intelligence systems are being used in medical environments, the article on artificial intelligence in healthcare provides comprehensive coverage. The integration of deep learning into clinical workflows is not replacing doctors but augmenting their capabilities, allowing them to focus on complex cases while the algorithm handles high-volume screening.
Drug discovery is another domain where deep learning has delivered measurable results, compressing timelines that traditionally stretched across a decade into significantly shorter cycles. Deep learning models analyze molecular structures, predict binding affinities, and generate novel candidate compounds by learning patterns from vast databases of known drug-molecule interactions. Insilico Medicine, a biotechnology company, used deep learning to identify a novel drug candidate for idiopathic pulmonary fibrosis and moved it into clinical trials in under 30 months, a fraction of the industry average. The economic stakes are enormous, as bringing a single drug to market through traditional methods costs an estimated $2.6 billion on average, and AI-driven approaches promise to reduce both cost and failure rate. Researchers leveraging personalized cancer screening with AI are demonstrating how deep learning can tailor treatment recommendations to individual patient profiles based on genomic, imaging, and clinical data. The convergence of deep learning with genomics and electronic health records is creating a new paradigm of precision medicine that was computationally unimaginable just ten years ago.
The risks of deploying deep learning in healthcare are proportional to the stakes, and the field must grapple with questions of validation, equity, and accountability. A model trained predominantly on data from one demographic group may perform poorly on patients from underrepresented populations, potentially widening existing health disparities rather than closing them. Regulatory bodies including the U.S. Food and Drug Administration are developing frameworks for evaluating and approving AI-based medical devices, requiring evidence of safety and efficacy across diverse patient populations. Clinicians and patients alike need to understand that deep learning models are tools that augment human judgment rather than replacements that eliminate the need for clinical expertise. The most effective healthcare AI deployments embed deep learning within decision-support systems that present recommendations alongside confidence scores and explanatory information, enabling physicians to make the final call. Transparency, validation, and equitable data representation are non-negotiable prerequisites for deploying deep learning in any healthcare setting.
Deep Learning in Autonomous Vehicles and Robotics
Self-driving vehicles represent one of the most ambitious and visible applications of deep learning, with perception systems relying on convolutional and transformer-based neural networks to interpret real-time sensor data from cameras, lidar, and radar. These networks must detect and classify pedestrians, cyclists, traffic signs, lane markings, and other vehicles at speeds measured in milliseconds, making split-second decisions that directly affect passenger and public safety. Tesla’s Full Self-Driving suite, powered by vision-based deep neural networks, logged over one billion miles of driving data in 2025, continuously feeding that data back into model retraining pipelines to improve performance. Waymo has deployed autonomous ride-hailing services in multiple U.S. cities, using deep learning to handle the unpredictable complexity of urban driving environments. The scale of data required for autonomous driving, encompassing billions of video frames, lidar point clouds, and annotated edge cases, makes it one of the most data-intensive deep learning applications in existence. Organizations investigating AI and autonomous driving will find that the engineering challenge extends far beyond model accuracy to include real-time inference latency, sensor fusion, and fail-safe system design.
Deep learning’s impact on robotics extends well beyond transportation, powering manufacturing robots, warehouse automation systems, surgical robots, and agricultural drones that adapt to their environments in real time. Traditional industrial robots followed fixed, pre-programmed routines, but deep learning enables a new generation of robots that perceive their surroundings, learn from experience, and handle variability such as irregularly shaped objects or unexpected obstacles. Companies like Boston Dynamics and Amazon Robotics use reinforcement learning, a branch of deep learning, to train robots in simulated environments before deploying them in physical warehouses and distribution centers. The connection between robotics and AI grows tighter each year as deep learning models shrink in size and improve in efficiency, making it feasible to run complex inference directly on the robot’s onboard processor rather than relying on cloud connectivity. Surgical robotics platforms such as Intuitive Surgical’s da Vinci system are incorporating deep learning for tasks like tissue identification and instrument tracking, enhancing precision during minimally invasive procedures. The convergence of deep learning, sensor technology, and mechanical engineering is creating robots that can operate in unstructured, real-world environments with increasing autonomy and reliability.
Natural Language Processing and the Rise of Conversational AI
Natural language processing (NLP) has been fundamentally transformed by deep learning, with transformer-based models enabling machines to understand, generate, and reason about human language at an unprecedented level of fluency. Before deep learning, NLP relied on hand-crafted rules, statistical models, and feature-engineered pipelines that struggled with ambiguity, context, and the vast variability of human expression. The introduction of word embeddings (Word2Vec, GloVe) and then contextual embeddings (ELMo, BERT) brought incremental improvements, but the transformer architecture unlocked a qualitative leap by allowing models to attend to entire passages of text simultaneously rather than processing words one at a time. Large language models trained on trillions of tokens now power chatbots, search engines, coding assistants, content generation tools, and customer support automation platforms used by millions of people daily. The shift from rule-based NLP to deep learning-driven NLP compressed decades of incremental progress into a few years of exponential capability gains. For those exploring how to build intelligent chat interfaces, the guide on how to make an AI chatbot offers practical starting points.
Real-time translation, sentiment analysis, and document summarization are among the NLP tasks where deep learning has moved from experimental to production-grade at global scale. Google Translate shifted from phrase-based statistical models to deep learning-based neural machine translation in 2016, achieving a 60 percent reduction in translation errors for many language pairs and continuing to improve annually since. Enterprises use transformer models to automate the extraction of key information from legal contracts, medical records, insurance claims, and regulatory filings, tasks that previously required large teams of human analysts working for weeks. Sentiment analysis powered by deep learning allows brands to monitor millions of social media posts, product reviews, and customer feedback messages in near real time, identifying emerging issues before they escalate. The combination of deep learning and NLP is also driving the development of agentic AI systems that can autonomously plan, execute, and verify multi-step workflows involving natural language understanding and generation. These applications represent a significant shift from passive information retrieval to active, goal-oriented AI agents that interact with digital environments on behalf of users.
The limitations of deep learning in NLP remain significant, with hallucination, factual inaccuracy, and the inability to reliably cite sources ranking among the most pressing challenges for enterprise adoption. Large language models generate text by predicting the most probable next token in a sequence, a mechanism that produces fluent prose but offers no guarantee of truthfulness or logical consistency. Organizations deploying deep learning for NLP must implement guardrails including retrieval-augmented generation, human review workflows, and confidence scoring to mitigate the risk of presenting fabricated information to end users. The energy cost of training and serving large language models is also a growing concern, with a single training run for a frontier model consuming electricity comparable to the annual usage of thousands of households. Balancing the transformative potential of deep learning in NLP against its environmental footprint, accuracy limitations, and the societal risks of synthetic text generation remains one of the defining challenges of the current era. Responsible NLP deployment requires continuous investment in evaluation, monitoring, and transparency rather than a one-time model training effort.
Deep Learning in Finance, Fraud Detection, and Risk Analysis
Financial institutions were among the earliest enterprise adopters of deep learning, deploying neural networks for fraud detection, credit scoring, algorithmic trading, and anti-money laundering compliance. Credit card companies process billions of transactions daily, and deep learning models analyze each transaction in real time, comparing patterns against learned representations of legitimate and fraudulent behavior to flag suspicious activity in milliseconds. These models outperform traditional rule-based fraud detection systems by capturing subtle, nonlinear patterns that human analysts and simple threshold rules consistently miss. JPMorgan Chase reported that its deep learning-based fraud detection system reduced false positive rates by over 50 percent compared to its previous rule-based approach, saving the bank significant operational costs while improving customer experience. Algorithmic trading firms use deep learning to analyze market microstructure data, predict short-term price movements, and execute trades at speeds and volumes that are beyond human capability. The intersection of deep learning and finance is also expanding into insurance underwriting, where neural networks analyze satellite imagery, sensor data, and historical claims to assess risk more granularly than traditional actuarial models.
Risk modeling in banking and insurance has been transformed by deep learning’s ability to process multiple data types simultaneously, combining structured financial data with unstructured text from news articles, earnings call transcripts, and regulatory filings. Recurrent and transformer-based models analyze sequences of financial events to predict default probabilities, market volatility, and systemic risk indicators. These models provide portfolio managers and risk officers with real-time dashboards that surface emerging threats before they materialize in traditional accounting metrics. The trade-off is interpretability, as regulators require financial institutions to explain the rationale behind consequential decisions such as loan approvals and insurance pricing, and deep learning’s black-box nature complicates compliance with these requirements. Explainable AI techniques such as SHAP values, attention visualization, and surrogate models help bridge the gap, providing approximate explanations for deep learning predictions without sacrificing the accuracy gains. Financial institutions that successfully balance predictive power with regulatory transparency will gain a lasting competitive advantage in risk management and customer acquisition.
The deployment of deep learning in finance is not without cautionary tales, as models trained on historical data can amplify existing market biases and behave unpredictably during unprecedented market conditions. Flash crashes, where algorithmic trading systems interact in unexpected feedback loops, have highlighted the systemic risks of deploying autonomous deep learning models in high-speed, high-stakes financial markets. Regulators in the United States and European Union are increasing scrutiny of AI-driven financial services, requiring model risk management frameworks, bias audits, and documentation of model limitations. The challenge for financial institutions is to capture the efficiency gains of deep learning while maintaining the human oversight necessary to prevent cascading failures during tail-risk events. Ongoing research into adversarial robustness, distributional shift detection, and causal inference for financial deep learning models represents the frontier of responsible AI in the financial sector. As AI applications in finance deepen, the firms that invest equally in model governance and model performance will be best positioned for sustainable growth.
The Tools and Frameworks Behind Modern Deep Learning
The deep learning ecosystem is anchored by a small number of open-source frameworks that provide the building blocks for designing, training, and deploying neural networks across research and production environments. PyTorch, developed by Meta AI, has become the dominant framework in academic research due to its dynamic computation graph, intuitive Python interface, and strong ecosystem of libraries for computer vision (torchvision), natural language processing (torchtext), and audio (torchaudio). TensorFlow, developed by Google, remains widely used in production systems thanks to its mature serving infrastructure (TensorFlow Serving), mobile deployment tools (TensorFlow Lite), and integration with Google Cloud’s AI Platform. JAX, also from Google, has gained traction among researchers who need fine-grained control over automatic differentiation and just-in-time compilation for high-performance training on TPU clusters. The convergence toward a small number of dominant frameworks has standardized deep learning development, making it easier for practitioners to share code, reproduce results, and build on each other’s work. Hugging Face has emerged as a central hub for pre-trained models, datasets, and training pipelines, particularly for NLP and generative AI tasks, lowering the barrier to entry for organizations that want to fine-tune existing models rather than train from scratch.
Beyond the core frameworks, a rich ecosystem of tools supports the end-to-end deep learning lifecycle, from data preparation and experiment tracking to model deployment and monitoring. Weights and Biases and MLflow provide experiment tracking and model registry capabilities that help teams manage the complexity of iterating on model architectures, hyperparameters, and training datasets. NVIDIA’s CUDA toolkit and cuDNN library are essential for GPU-accelerated training, and the company’s Triton Inference Server handles high-throughput model serving in production environments. Docker and Kubernetes have become standard for containerizing and orchestrating deep learning training jobs across distributed compute clusters, enabling reproducibility and scalability. The rapid maturation of this tooling ecosystem means that the barrier to building and deploying deep learning systems is lower than it has ever been, though the skill required to operate these tools effectively remains substantial. Organizations that invest in platform engineering for deep learning, creating internal tools and standardized pipelines, consistently ship models to production faster than those that treat each project as a standalone effort.
Implementing Deep Learning in Enterprise Environments
Moving deep learning from a research prototype to a production system that delivers reliable business value is one of the most underestimated challenges in enterprise AI adoption. The gap between a model that achieves impressive accuracy on a test set and a system that operates reliably under real-world conditions, handles edge cases gracefully, and integrates with existing business processes is often larger than the initial model development effort. Successful enterprise deployment requires investment in data infrastructure, feature stores, model serving pipelines, monitoring dashboards, and incident response processes that most organizations do not have in place when they begin their deep learning journey. The concept of MLOps (machine learning operations) has emerged specifically to address this gap, applying DevOps principles of continuous integration, continuous delivery, and infrastructure-as-code to the machine learning lifecycle. Teams that adopt MLOps practices deploy models faster, detect performance degradation sooner, and retrain models more efficiently than teams operating with ad hoc workflows. The organizational change management required to embed deep learning into business processes is as significant as the technical challenge, demanding collaboration between data scientists, software engineers, product managers, and domain experts.
Data governance is a critical pillar of enterprise deep learning, encompassing data quality, lineage tracking, privacy compliance, and access control. Deep learning models are only as good as the data they are trained on, and enterprise data is often fragmented across silos, inconsistent in format, and subject to regulatory constraints such as GDPR and HIPAA that limit how it can be collected, stored, and used. Organizations that invest in centralized data platforms, standardized schemas, and automated data quality checks create a foundation that accelerates every subsequent deep learning initiative. Privacy-preserving techniques such as federated learning and differential privacy allow organizations to train deep learning models on sensitive data without centralizing it, addressing regulatory concerns while still capturing the value locked in distributed datasets. The cost of poor data governance compounds over time, as models trained on flawed data produce flawed predictions that erode trust and generate compliance risk. Building a data governance practice that scales alongside deep learning ambitions is not optional; it is a prerequisite for sustainable AI value creation.
Change management and talent strategy are the third pillar, because the most sophisticated deep learning infrastructure is useless without people who know how to operate it and a culture that trusts AI-informed decisions. The global shortage of experienced deep learning engineers and research scientists means that most organizations will need to combine external hiring with internal upskilling, investing in training programs that bridge the gap between traditional software engineering and deep learning development. Cross-functional teams that include domain experts alongside data scientists produce better results than isolated AI labs, because domain knowledge is essential for framing business problems correctly, interpreting model outputs, and identifying failure modes that pure technologists might miss. Executive sponsorship is equally important, as deep learning projects often require sustained investment over months before delivering measurable returns, and leadership commitment prevents premature cancellation of initiatives that need time to mature. The organizations that succeed with deep learning at scale are those that treat it as a capability to build rather than a product to buy, investing simultaneously in technology, data, talent, and organizational alignment.
Bias, Privacy, and the Black Box Problem
Algorithmic bias is one of the most consequential risks of deploying deep learning systems, because models trained on biased data will produce biased outputs that can reinforce and amplify existing societal inequalities. Facial recognition systems have been shown to exhibit significantly higher error rates for women and people with darker skin tones, a disparity traced directly to training datasets that underrepresented these demographic groups. Hiring algorithms trained on historical employment data have been found to penalize candidates from underrepresented backgrounds, replicating the very biases that organizations intended to eliminate by automating the process. The challenge is structural: deep learning models learn whatever patterns are present in the data, including patterns that reflect discriminatory historical practices, and they do so at a scale and speed that makes the resulting harm both widespread and difficult to detect. Bias is not a bug that can be patched with a single fix but a systemic property that requires ongoing auditing, diverse training data, and deliberate design choices throughout the model lifecycle. Organizations must build bias testing into their model development pipelines and establish regular audit schedules that evaluate model performance across demographic subgroups.
Privacy concerns intensify as deep learning systems are trained on ever-larger datasets that often contain sensitive personal information, from medical records and financial transactions to browsing histories and biometric data. The ability of deep learning models to memorize and potentially reconstruct individual data points from training data poses a direct threat to data privacy, even when the data was ostensibly anonymized before training. Membership inference attacks and model inversion attacks have demonstrated that trained neural networks can leak information about specific individuals in the training set, undermining the assumption that aggregation provides sufficient privacy protection. Regulatory frameworks such as GDPR grant individuals the right to know how automated decisions are made about them, creating a direct tension with deep learning’s opacity. Differential privacy, which adds carefully calibrated noise to training data or model gradients, offers a mathematically rigorous approach to limiting information leakage while preserving model utility. Organizations deploying deep learning on personal data must implement defense-in-depth strategies that combine technical privacy measures with legal compliance, data minimization, and transparent communication with data subjects.
The “black box” nature of deep learning, the difficulty of understanding how and why a model produces a particular output, compounds both the bias and privacy problems and introduces its own distinct risks. When a deep learning model denies a loan application, recommends a medical treatment, or flags a transaction as fraudulent, the individuals affected by that decision have a legitimate right to understand the reasoning behind it. Explainability techniques such as LIME (Local Interpretable Model-agnostic Explanations), SHAP (SHapley Additive exPlanations), and attention visualization provide partial explanations by approximating the model’s local behavior, but none fully captures the global decision logic of a complex neural network. The tension between accuracy and interpretability is a defining trade-off in deep learning: the models that perform best on complex tasks tend to be the least interpretable, while simpler, more transparent models sacrifice some accuracy for understandability. Regulators, ethicists, and affected communities are increasingly demanding that organizations deploying high-stakes deep learning systems provide meaningful explanations of model behavior, not just accuracy metrics. Building interpretability into the model design process from the outset, rather than bolting it on after deployment, is becoming a best practice for organizations that take accountability seriously.
The intersection of bias, privacy, and opacity creates a compounding risk that demands governance frameworks tailored specifically to deep learning rather than generic IT risk management. A biased model that is also opaque is doubly dangerous, because the bias is harder to detect and correct when the decision process cannot be inspected. A model trained on private data that leaks information is triply dangerous if the leak goes undetected because the training pipeline lacks transparency. Organizations responding to these overlapping challenges are establishing AI ethics boards, adopting model cards that document training data, known limitations, and performance disparities, and investing in red-team exercises that specifically target deep learning vulnerabilities. The maturation of deep learning governance from an afterthought to a core function will determine whether the technology earns and retains public trust. Without proactive governance, the backlash against irresponsible deployment could stifle innovation and restrict access to a technology with enormous potential to benefit society.
Ethical Guardrails for Responsible Deep Learning
Responsible deep learning deployment requires a combination of technical safeguards, organizational practices, and regulatory engagement that goes beyond simply training an accurate model. Fairness constraints can be incorporated directly into the training objective, penalizing the model for producing disparate outcomes across protected groups and steering the optimization toward equitable performance. Adversarial testing, where teams deliberately probe the model with inputs designed to elicit biased or harmful outputs, reveals vulnerabilities that standard validation metrics miss. Documentation practices such as datasheets for datasets and model cards for trained models create an audit trail that enables external review and accountability. The shift from “move fast and break things” to “move thoughtfully and measure everything” represents a cultural change that the deep learning community is still actively negotiating. Organizations that embed ethical review into the model development workflow, rather than conducting it as a post-hoc compliance exercise, consistently produce more robust and equitable systems.
The environmental impact of training large deep learning models is an ethical consideration that is gaining urgency as models scale to hundreds of billions of parameters. A 2025 analysis by researchers at the University of Massachusetts Amherst found that training a single large transformer model can emit as much carbon dioxide as five cars over their entire lifetimes, a figure that has grown as model sizes increase. Cloud providers are responding by investing in renewable energy sources for their data centers and developing more energy-efficient hardware, but the responsibility extends to the organizations commissioning training runs. Techniques such as model pruning, knowledge distillation, and efficient architectures like mixture-of-experts reduce the computational footprint of deep learning without proportionally reducing performance. The emerging concept of “green AI” advocates for reporting the carbon cost of training alongside accuracy metrics, creating social and scientific norms that incentivize efficiency. Balancing the societal benefits of deep learning against its environmental cost requires transparency, innovation, and a willingness to acknowledge that bigger is not always better.
Regulatory frameworks are evolving rapidly to address the unique challenges of deep learning, with the European Union’s AI Act serving as a landmark piece of legislation that categorizes AI systems by risk level and imposes corresponding requirements. High-risk applications, defined as those affecting health, safety, fundamental rights, and access to essential services, must meet standards for transparency, human oversight, data quality, and robustness before deployment. The United States has taken a more sector-specific approach, with agencies like the FDA, SEC, and FTC developing guidance for AI in healthcare, finance, and consumer protection respectively. Organizations operating globally must navigate a patchwork of regulatory requirements, making compliance a strategic priority that shapes technology decisions from the earliest stages of development. Proactive engagement with regulators, participation in industry standards bodies, and investment in compliance infrastructure are increasingly table stakes for organizations deploying deep learning at scale. The regulatory landscape will continue to tighten, and organizations that build compliance into their deep learning pipelines early will face less disruption than those that retrofit governance onto already-deployed systems.
The Deep Learning Market and Global Investment Landscape
The global deep learning market is experiencing extraordinary growth, with multiple research firms projecting compound annual growth rates exceeding 25 percent through the end of the decade. According to Mordor Intelligence’s 2026 report, the market is projected to grow from $64.92 billion in 2026 to $296.23 billion by 2031, driven by enterprise AI adoption, generative AI applications, and advanced data analytics across industries. North America accounts for the largest regional share, supported by substantial venture capital investment, a dense concentration of technology firms, and leading research universities that produce a steady pipeline of deep learning talent. Asia-Pacific is emerging as the fastest-growing region, with national AI strategies in China, India, Japan, and South Korea fueling investment in deep learning infrastructure, semiconductor manufacturing, and industrial automation. The competitive landscape includes hyperscale cloud providers (AWS, Google Cloud, Microsoft Azure), semiconductor companies (NVIDIA, AMD, Intel), enterprise software firms, and a vibrant ecosystem of startups focusing on vertical applications in healthcare, autonomous systems, fintech, and cybersecurity. The investment flowing into deep learning reflects a broad consensus across industries that the technology is not a passing trend but a foundational shift in how data is processed, decisions are made, and value is created.
Venture capital funding for deep learning startups has reached historic levels, with investors betting on the technology’s potential to transform every major industry from healthcare and transportation to agriculture and energy. Foundation model companies such as OpenAI, Anthropic, Mistral, and Cohere have raised billions of dollars to train increasingly capable general-purpose models, while application-layer startups build domain-specific solutions on top of those models. The hardware layer is equally active, with NVIDIA’s market capitalization surging past major traditional technology companies on the strength of demand for its AI accelerator chips. Government funding is also significant, with the U.S. National AI Initiative committing billions in federal research dollars and the European Union’s Horizon Europe program allocating substantial budgets to AI and deep learning research. The convergence of private capital, public investment, and customer demand is creating a market environment where deep learning companies can scale rapidly, and the insights on quantum computing’s influence on AI suggest that the next wave of growth may come from hybrid quantum-classical approaches that push deep learning beyond its current computational limits. The pace of investment shows no sign of slowing, suggesting that deep learning will remain a dominant focus for capital allocation in the technology sector for years to come.
What Comes Next: Agentic AI, Edge Models, and Neuro-Symbolic Systems
Deep learning in 2026 is evolving beyond pattern recognition and content generation toward agentic capabilities, where AI systems autonomously plan, execute, and verify multi-step workflows without continuous human guidance. Agentic AI combines deep learning’s perceptual and generative strengths with structured reasoning loops that allow models to decompose complex tasks, call external tools, and iteratively refine their outputs based on feedback. This paradigm shift represents a meaningful step toward AI systems that operate as collaborators rather than reactive tools, handling tasks such as research synthesis, code generation with testing, and multi-channel customer service workflows. The transition from generative AI to agentic AI is one of the most closely watched developments in the field, with major technology companies and research labs racing to build reliable agent frameworks. Concerns about safety, controllability, and unintended consequences are driving parallel investment in alignment research and containment strategies. The combination of deep learning perception with structured decision-making represents a new frontier that could dramatically expand the economic value of AI systems in the coming years.
Small language models and edge deployment represent a countertrend to the “bigger is better” paradigm that dominated deep learning from 2020 to 2024, with efficiency and privacy emerging as design priorities alongside raw performance. Techniques such as knowledge distillation, where a large “teacher” model transfers its knowledge to a much smaller “student” model, have matured to the point where models one-hundredth the size of frontier systems retain 90 percent of their capability on targeted tasks. Smartphones, wearables, and IoT devices now ship with neural processing units (NPUs) that can run deep learning inference locally, eliminating the latency, bandwidth costs, and privacy risks associated with sending data to the cloud. A lawyer’s phone running a compact model trained specifically on contract analysis, or a factory sensor running an anomaly detection model at the edge, exemplifies the shift toward domain-specific, locally deployed deep learning. This trend aligns with growing regulatory pressure around data sovereignty and user privacy, as on-device inference keeps sensitive information on the device rather than transmitting it to third-party servers. The democratization of deep learning through smaller, more efficient models will expand the technology’s reach into environments where cloud connectivity is unreliable, latency is unacceptable, or data sensitivity is paramount.
Neuro-symbolic AI, which combines the pattern recognition strengths of deep learning with the logical reasoning capabilities of symbolic AI, addresses one of the most fundamental limitations of pure neural network approaches: the inability to perform reliable, verifiable logical reasoning. Deep learning models excel at perception, generation, and pattern matching but struggle with tasks that require counting, multi-step deduction, or adherence to formal rules. Neuro-symbolic systems use neural networks to process raw data and extract features, then pass those features to symbolic reasoning engines that apply logical constraints to produce outputs that are both accurate and provably consistent with defined rules. This hybrid approach reduces hallucination in language models, improves performance on mathematical reasoning tasks, and enables AI systems to provide auditable explanations for their decisions. The integration of geometric deep learning with symbolic reasoning on structured data represents one promising direction for neuro-symbolic research. As the field matures, neuro-symbolic AI may resolve the tension between deep learning’s power and its opacity, creating systems that are simultaneously capable and trustworthy.
Preparing for a Deep Learning-Driven Future
Organizations that want to capitalize on deep learning must begin by building a realistic assessment of their data maturity, technical infrastructure, and talent pipeline rather than chasing the latest model release. A data audit that inventories available datasets, evaluates quality, identifies gaps, and maps regulatory constraints provides the foundation for every subsequent deep learning initiative. Investing in data engineering capabilities, including pipelines for collection, cleaning, labeling, and versioning, yields compounding returns as the organization launches multiple deep learning projects over time. The most common failure mode for enterprise deep learning is not model architecture selection but data readiness, with projects stalling because the training data does not exist, is too noisy, or cannot be legally used. Organizations that treat data as a strategic asset and invest in its management before investing in model development consistently outperform those that approach deep learning as a technology-first initiative. The technical sophistication of the model matters far less than the quality, relevance, and volume of the data it is trained on.
Talent development is equally critical, and the most effective strategy combines hiring experienced deep learning practitioners with upskilling existing employees who bring domain expertise and institutional knowledge. Online platforms such as Coursera, DeepLearning.AI, and fast.ai have made high-quality deep learning education accessible to anyone with a programming background, reducing the dependency on formal Ph.D. credentials. Internal hackathons, study groups, and dedicated learning time create an organizational culture that normalizes experimentation and reduces the stigma of failure that often accompanies AI projects. Cross-functional teams that pair deep learning engineers with business domain experts, product managers, and compliance officers produce solutions that are technically sound, commercially viable, and governable. The competitive landscape is shifting from who has the best model to who can deploy, operate, and govern models at scale, making operational excellence a more durable advantage than algorithmic novelty. Organizations that build deep learning as a core organizational capability, embedded in processes and culture rather than isolated in a research lab, will be best positioned to capture value from the next decade of AI advancement.
The broader societal implications of a deep learning-driven future extend beyond individual organizations to education systems, labor markets, and democratic institutions. Education curricula at every level, from elementary schools to executive programs, will need to incorporate AI literacy so that citizens can participate meaningfully in decisions about how these systems are deployed in their communities. Labor markets will continue to evolve, with deep learning automating some tasks while creating new roles in data annotation, model evaluation, AI ethics, and human-AI collaboration. Democratic institutions will face pressure to develop governance frameworks that balance innovation with accountability, ensuring that the benefits of deep learning are broadly shared rather than concentrated among a small number of technology companies and wealthy nations. The article on how artificial intelligence is changing our society explores these dynamics through multiple perspectives. The organizations, governments, and communities that approach this transition with intentionality, investing in both capability and governance, will shape a future where deep learning serves as a tool for broad human flourishing rather than a source of concentrated power and risk.
Key Insights
- According to Mordor Intelligence’s 2026 report, the deep learning market is projected to reach $296.23 billion by 2031 with a 35.48 percent CAGR, signaling that the technology has transitioned from experimental to foundational across industries.
- According to Fortune Business Insights, North America accounted for 38.61 percent of the global deep learning market in 2025, reflecting the region’s concentration of research talent, venture capital, and enterprise AI adoption.
- According to Grand View Research, image recognition held the largest deep learning application share at 43.38 percent in 2024, underscoring how computer vision remains the most commercially mature use case.
- According to IMARC Group, the deep learning market reached $30.9 billion in 2024 and is expected to hit $423.4 billion by 2033 at a 29.92 percent CAGR, with North America commanding over 36.5 percent market share.
- According to Markets and Markets, the global deep learning market was valued at $25.40 billion in 2024 and is estimated to reach $506.75 billion by 2035, with healthcare and automotive leading adoption.
- According to Fortune Business Insights’ ML report, the broader machine learning market is expected to grow from $65.28 billion in 2026 to $432.63 billion by 2034, demonstrating that deep learning’s growth is part of a larger AI investment wave.
- The EU’s Horizon Europe program has allocated €93.4 billion toward research including AI and deep learning, representing one of the largest public sector commitments to the technology globally, as reported by IMARC Group’s analysis.
- Google’s DeepMind Health achieved 94 percent accuracy in detecting over 50 eye conditions from retinal scans in 2025, demonstrating deep learning’s clinical-grade performance in medical diagnostics, according to industry reporting.
The data paints a clear picture: deep learning is no longer an emerging technology but a maturing market force reshaping multiple sectors simultaneously. Market projections consistently forecast growth rates above 25 percent annually, with enterprise adoption spreading from early movers in technology and finance to healthcare, automotive, retail, and government. North America leads in market share and research output, but Asia-Pacific’s rapid growth trajectory suggests that the center of gravity for deep learning innovation may shift eastward within the decade. The gap between deep learning leaders and laggards is widening, as organizations that build data infrastructure and governance early capture compounding advantages over time. Public investment from both U.S. and European governments signals that deep learning is now viewed as critical infrastructure rather than a discretionary technology experiment. The convergence of private capital, regulatory attention, and measurable business results indicates that deep learning will remain the dominant technology paradigm for the foreseeable future.
Deep Learning vs AI: A Comprehensive Comparison
| Dimension | Deep Learning | Artificial Intelligence (Broad) |
|---|---|---|
| Transparency | Low: multi-layered neural networks are inherently opaque, requiring specialized tools to approximate explanations | Variable: rule-based AI systems are fully transparent, while ML models range from transparent (decision trees) to opaque (ensemble models) |
| Participation | Concentrated: requires specialized hardware, large datasets, and expert practitioners, limiting participation to well-resourced organizations | Broad: simpler AI techniques are accessible to smaller teams and organizations with modest computational resources |
| Trust | Lower initial trust due to black-box nature; trust builds through validation, auditing, and proven track records | Higher initial trust for rule-based systems whose logic can be inspected; trust varies across ML techniques |
| Decision Making | Autonomous: capable of making high-speed, high-volume decisions without human intervention once deployed | Ranges from fully automated to human-in-the-loop, depending on the technique and risk level |
| Misinformation | High risk: generative deep learning models can produce convincing but fabricated text, images, and audio (deepfakes) | Lower risk for deterministic, rule-based systems; moderate risk for statistical ML models that can propagate data biases |
| Service Delivery | Transformative: enables personalized, real-time services at scale (medical diagnostics, fraud detection, recommendations) | Foundational: powers a broad range of services from basic automation to advanced analytics |
| Accountability | Challenging: difficulty in explaining decisions complicates attribution of responsibility and regulatory compliance | Clearer for transparent systems; accountability frameworks are more established for traditional AI techniques |
How Organizations Are Applying Deep Learning Across Industries
Google DeepMind’s Medical Imaging Breakthrough
Google DeepMind expanded its retinal scan AI system in 2025 to detect over 50 eye conditions with 94 percent accuracy, rivaling the performance of top ophthalmology specialists, as reported by industry analysts covering deep learning in healthcare. The system uses deep convolutional neural networks trained on hundreds of thousands of annotated retinal scans from the U.K.’s National Health Service. The measurable outcome has been a significant reduction in screening backlogs at partner hospitals, enabling faster triage for patients at risk of diabetic retinopathy and age-related macular degeneration. Critics point out that the system’s training data is predominantly drawn from a single national healthcare system, raising questions about its generalizability to populations with different demographic profiles and disease prevalence patterns. The deployment also highlighted the tension between algorithmic speed and clinical accountability, as physicians must still review and validate AI-generated findings before acting on them.
Tesla’s Vision-Based Autonomous Driving System
Tesla’s Full Self-Driving suite relies entirely on camera-based deep neural networks rather than lidar sensors, processing video from eight cameras to build a real-time 3D model of the vehicle’s surroundings, as described by autonomous vehicle analysts. By the end of 2025, the system had logged over one billion miles of real-world driving data, which Tesla uses to continuously retrain its neural networks and address edge cases such as unusual road conditions, construction zones, and emergency vehicles. The measured impact includes a demonstrable reduction in accident rates for vehicles using the supervised autonomy feature compared to non-assisted driving. The limitation is that the system still requires driver supervision and has been involved in incidents where the neural network failed to correctly classify stationary emergency vehicles or unusual obstacles. Regulatory scrutiny from the National Highway Traffic Safety Administration continues, underscoring the gap between deep learning capability and the level of reliability required for fully autonomous deployment.
Amazon’s Deep Learning-Powered Warehouse Robotics
Amazon Robotics deploys deep learning models across its fulfillment centers to enable robotic systems that pick, pack, and sort items with increasing autonomy, as detailed in the company’s operational technology reports. The deep learning models process camera feeds and sensor data to identify objects of varying shapes and sizes, plan grasping strategies, and navigate crowded warehouse environments alongside human workers. Amazon reported that its robotic systems improved warehouse throughput by more than 20 percent while reducing order processing errors. The limitation is that the systems still struggle with irregularly shaped, transparent, or deformable objects that challenge current computer vision models, requiring human workers to handle these exceptions. The concentration of advanced robotics capability within a single dominant e-commerce player also raises broader questions about market competition and workforce displacement.
Lessons From Deep Learning Deployments in Practice
Case Study: Insilico Medicine’s AI-Driven Drug Discovery
Insilico Medicine faced the challenge of identifying viable drug candidates for idiopathic pulmonary fibrosis, a disease with limited treatment options and a traditionally slow drug development pipeline. The company deployed deep learning models to analyze molecular structures and predict binding affinities, generating novel candidate compounds from vast chemical databases. The measurable impact was striking: the company moved from target identification to Phase I clinical trials in under 30 months, a fraction of the pharmaceutical industry’s typical 10-to-15-year timeline. The deep learning system also reduced the number of failed candidates early in the pipeline, lowering development costs substantially. Critics note that the long-term clinical efficacy of AI-discovered drugs remains unproven, as the candidates are still in early trial stages and the technology’s track record in late-stage clinical success is not yet established.
Case Study: Waymo’s Urban Autonomous Ride-Hailing Service
Waymo confronted the problem of navigating unpredictable urban driving environments, where pedestrians, cyclists, and other vehicles create scenarios far more complex than highway driving. The company’s solution combines deep learning-based perception (using CNNs and transformers on lidar and camera data) with a rule-based planning system that enforces safety constraints on the neural network’s outputs. Waymo’s autonomous ride-hailing service, operating in cities including Phoenix, San Francisco, and Los Angeles, has completed millions of fully autonomous trips with a published safety record that compares favorably to human drivers, according to company safety reports. The deployment revealed that deep learning alone is insufficient for safety-critical driving; the combination of learned perception with structured safety rules creates a more robust system than either approach alone. The limitation is geographic: Waymo’s system performs best in the specific cities where it has accumulated extensive training data and high-definition maps, and generalizing to new cities requires significant additional data collection and testing.
Case Study: JPMorgan Chase’s Deep Learning Fraud Detection Platform
JPMorgan Chase faced escalating fraud losses and customer friction from a rule-based fraud detection system that generated high volumes of false positives, blocking legitimate transactions while missing sophisticated attack patterns. The bank deployed deep learning models trained on billions of historical transactions to identify subtle, nonlinear patterns indicative of fraud that static rules could not capture. The measurable impact included a reduction in false positive rates exceeding 50 percent, which simultaneously improved customer experience and allowed fraud analysts to focus on genuinely suspicious activity. The reduction in false positives also translated into significant operational cost savings by decreasing the volume of manual reviews required for each flagged transaction. The limitation is that deep learning fraud models must be continuously retrained to keep pace with evolving fraud tactics, and the opacity of neural network decisions complicates the bank’s ability to explain specific transaction blocks to regulators and customers.
Frequently Asked Questions on Deep Learning and Artificial Intelligence
Deep learning is a computer science technique that teaches machines to learn from data using layered networks of mathematical functions called neurons. Each layer processes the data and passes it forward, extracting increasingly complex patterns along the way. The result is a system that can recognize images, understand language, and make predictions without being explicitly programmed for each task.
Deep learning is not the same as artificial intelligence, though it is a subset of the broader AI field. AI encompasses all techniques designed to make machines intelligent, from simple rule-based systems to advanced neural networks. Deep learning is one of the most powerful tools within AI, but it is not the only one.
Machine learning is a broader category of algorithms that learn from data, including techniques like decision trees and linear regression that require human-crafted features. Deep learning eliminates much of that manual feature engineering by using multi-layered neural networks to learn features directly from raw data. The trade-off is that deep learning requires more data and compute power than most traditional machine learning approaches.
Neural networks are computational structures made up of interconnected nodes organized in layers, loosely inspired by the way biological neurons transmit signals. They matter because they are the foundational architecture that enables deep learning, with each layer transforming input data into progressively more abstract representations. The “depth” in deep learning refers to the number of these hidden layers stacked between input and output.
Healthcare, autonomous transportation, finance, retail, and natural language processing are among the industries most transformed by deep learning. In healthcare, deep learning powers medical imaging diagnostics and drug discovery. In finance, it drives fraud detection, credit scoring, and algorithmic trading at scales impossible for human analysts alone.
Deep learning models contain millions or billions of adjustable parameters, and fitting those parameters accurately requires proportionally large volumes of training data to prevent overfitting. Without sufficient data, the model memorizes the training examples rather than learning generalizable patterns. The relationship between model complexity and data requirements is a fundamental constraint of the deep learning paradigm.
The black box problem refers to the difficulty of understanding how a deep learning model arrives at a particular prediction or decision. Neural networks with millions of parameters make decisions through complex, nonlinear transformations that resist simple human interpretation. This opacity creates challenges for accountability, regulatory compliance, and trust in high-stakes applications.
Autonomous vehicles use deep learning to process real-time sensor data from cameras, lidar, and radar, detecting and classifying objects such as pedestrians, other vehicles, and traffic signs. The deep learning models make split-second decisions about steering, braking, and acceleration based on learned patterns from billions of miles of driving data. Safety-critical systems typically combine deep learning perception with rule-based planning to enforce safety constraints.
The primary ethical risks include algorithmic bias from unrepresentative training data, privacy violations from models trained on personal information, and the environmental cost of training large-scale models. The opacity of deep learning decisions also raises accountability concerns when models make consequential decisions about healthcare, finance, or criminal justice. Addressing these risks requires ongoing auditing, diverse data practices, and robust governance frameworks.
The future of deep learning includes agentic AI systems that autonomously execute multi-step tasks, smaller and more efficient models deployed on edge devices, and neuro-symbolic architectures that combine neural pattern recognition with logical reasoning. These trends point toward deep learning systems that are more capable, more efficient, and more explainable than current models. The convergence of these advances will expand deep learning’s reach into environments where cloud connectivity, latency, or interpretability constraints currently limit adoption.
Implementation costs vary dramatically depending on the use case, ranging from a few thousand dollars for fine-tuning a pre-trained model on a cloud platform to millions of dollars for training a custom foundation model on proprietary data. The major cost components include data collection and labeling, compute infrastructure (GPUs or TPUs), engineering talent, and ongoing model monitoring and retraining. Transfer learning and pre-trained models have significantly reduced entry costs for organizations that do not require custom architectures.
Small businesses can access deep learning through cloud-based AI services, pre-trained models, and AutoML platforms that require minimal technical expertise. Services such as Google Cloud Vision, AWS Rekognition, and Hugging Face’s model hub allow small teams to deploy image recognition, text analysis, and prediction models without building infrastructure from scratch. The democratization of deep learning tools means that the barrier to entry is now more about data availability and problem definition than about computational resources.
Deep learning is automating specific tasks rather than replacing entire jobs, creating a shift in the nature of work rather than wholesale job elimination. Roles that involve repetitive pattern recognition, data entry, and routine decision-making are most susceptible to automation, while roles requiring creativity, empathy, complex judgment, and cross-domain reasoning remain firmly in human territory. New roles in data annotation, model evaluation, AI governance, and human-AI collaboration are emerging alongside the automation of existing tasks.
Python is the dominant programming language for deep learning, supported by frameworks such as PyTorch, TensorFlow, and JAX that provide high-level APIs for building and training neural networks. C++ is used in performance-critical inference engines and hardware-level optimization. Julia is emerging as an alternative for high-performance numerical computing, and Rust is gaining traction for building production-grade inference infrastructure.
Deep learning processes images using convolutional neural networks that apply spatial filters to detect local patterns like edges, textures, and shapes, leveraging the spatial structure of pixel data. Text is processed using transformer architectures that apply self-attention mechanisms to capture relationships between words across entire passages, leveraging the sequential and contextual nature of language. The choice of architecture is dictated by the structure of the input data, with each design imposing biases that help the network learn relevant patterns efficiently.