
Introduction
Image annotation sits at the foundation of every computer vision system that powers self-driving cars, medical diagnostics, and retail automation across the globe. The data annotation tools market reached approximately USD 2.14 billion in 2026 and is projected to grow at a compound annual growth rate of 26.76% through 2034, signaling the enormous demand for labeled visual data. Every time a machine learning model recognizes a pedestrian on a crosswalk or identifies a tumor on a medical scan, it relies on thousands of carefully annotated training images to make that decision. The process of annotating an image involves adding labels, tags, bounding boxes, or pixel-level masks to visual data so that algorithms can learn to interpret what they see. Skilled annotators and increasingly sophisticated AI-assisted tools work together to produce the structured datasets that train these models. Without high-quality image annotation, even the most advanced neural networks would be unable to distinguish a stop sign from a billboard. Understanding how image annotation works, which techniques to use, and which pitfalls to avoid is essential for any organization building computer vision applications. This guide covers every aspect of image annotation, from fundamental concepts to advanced implementation strategies.
Essential Questions About Image Annotation
What is image annotation and why is it important for AI?
Image annotation is the process of labeling visual data with tags, bounding boxes, polygons, or segmentation masks so that machine learning models can recognize and classify objects within images.
What are the main types of image annotation techniques?
The primary techniques include bounding box annotation, polygon annotation, semantic segmentation, instance segmentation, keypoint annotation, and polyline annotation, each offering different levels of precision.
How do you choose the right image annotation method?
The ideal annotation method depends on the complexity of the objects being labeled, the required level of precision, the downstream task such as detection or segmentation, and the available budget and timeline.
Key Takeaways
- Quality assurance through inter-annotator agreement metrics and review workflows is critical for producing training data that yields accurate and unbiased models.
- Image annotation transforms raw visual data into structured training datasets that teach computer vision systems to detect, classify, and segment objects.
- Choosing the right annotation type (bounding boxes, polygons, segmentation masks, or keypoints) depends on project requirements, object complexity, and budget constraints.
- AI-assisted annotation tools now combine human expertise with machine learning pre-labeling to reduce manual effort and accelerate dataset creation.
Table of contents
- Introduction
- Essential Questions About Image Annotation
- Key Takeaways
- What Image Annotation Means for Machine Learning
- Why Accurate Image Labeling Matters
- Bounding Box Annotation Explained
- Polygon Annotation for Irregular Shapes
- Semantic Segmentation at the Pixel Level
- Instance Segmentation and Object Counting
- Keypoint and Landmark Annotation
- Polyline and 3D Cuboid Techniques
- Choosing the Right Annotation Type for Your Project
- Top Image Annotation Tools and Platforms
- How to Annotate Images for a Computer Vision Project
- Step 1: Define Your Annotation Ontology and Guidelines
- Step 2: Collect and Prepare Your Image Dataset
- Step 3: Select and Configure Your Annotation Tool
- Step 4: Annotate a Calibration Batch and Measure Agreement
- Step 5: Execute Full-Scale Annotation with Quality Checkpoints
- Step 6: Export, Validate, and Integrate the Annotated Dataset
- Quality Assurance and Inter-Annotator Agreement
- The Human-in-the-Loop Approach
- Industries Transformed by Image Annotation
- Ethical Considerations and Annotator Bias
- Privacy and Regulatory Compliance in Annotation
- AI-Assisted Annotation and Active Learning
- The Future of Image Annotation Technology
- Key Insights on the Image Annotation Market
- How Organizations Use Image Annotation in Practice
- Lessons From Large-Scale Image Annotation Deployments
- Frequently Asked Questions About Image Annotation for Machine Learning
What Image Annotation Means for Machine Learning
Image annotation is the practice of adding structured metadata to digital images so that machine learning algorithms can learn to interpret visual content. This metadata takes many forms, including rectangular boxes drawn around objects, pixel-level masks that outline exact boundaries, and point markers placed on anatomical landmarks. The purpose is to create ground-truth datasets that serve as the reference standard against which a model measures its own predictions during training. Machine learning engineers define the categories, attributes, and spatial representations that annotators must apply to each image in the dataset. These labeled images then feed into supervised learning pipelines where the model iteratively adjusts its parameters to minimize the gap between its predictions and the annotated ground truth. The quality of these annotations directly determines the upper limit of a model’s accuracy, making annotation the most consequential step in the entire training pipeline.
The scope of image annotation extends well beyond simply tagging what appears in a photograph. Depending on the use case, an annotation project may require identifying every pixel that belongs to a particular class, tracking the movement of objects across video frames, or recording three-dimensional spatial relationships between elements in a scene. A medical imaging project might require annotators to outline the precise contours of a lesion at the pixel level, while a retail application might only need bounding boxes around product items on a shelf. The complexity and granularity of the annotation directly affect both the cost and the timeline of the project. Organizations must carefully scope their annotation requirements before beginning any machine learning training initiative to ensure that the resulting dataset meets the model’s needs without unnecessary expenditure.
The annotation workflow typically begins with the creation of an ontology, which is a structured set of class definitions, attributes, and labeling guidelines that annotators follow throughout the project. This ontology ensures consistency across thousands or millions of images labeled by different team members working in parallel. After the ontology is established, annotators use specialized software platforms to apply labels to each image according to the defined guidelines. The labeled data then passes through a quality review stage where senior reviewers or automated checks verify that annotations meet accuracy thresholds. Completed datasets are exported in standardized formats such as COCO JSON, Pascal VOC XML, or YOLO text files, which integrate seamlessly into popular training frameworks. This structured pipeline transforms raw, unstructured visual data into the refined fuel that powers modern artificial intelligence systems.
Image Annotation Cost and Time Estimator
Compare annotation types by cost, speed, and precision. Adjust parameters to estimate your project scope.
Select your annotation type and adjust dataset parameters to see a project estimate with cost and time breakdown.
Why Accurate Image Labeling Matters
The relationship between image annotation quality and model performance is direct and unforgiving, because a model can only be as good as the data it learns from. When bounding boxes are drawn too loosely around objects, the model learns to associate irrelevant background pixels with the target class, leading to false positives in production. When labels are inconsistent across annotators, the model receives contradictory signals that degrade its ability to generalize to new, unseen images. Research from multiple computer vision benchmarks has shown that models trained with instance segmentation annotations can outperform those trained with bounding boxes alone by up to 30% on object counting tasks. Investing in precise, consistent annotation is not an optional refinement but a prerequisite for building models that perform reliably in real-world conditions.
Beyond technical accuracy, the image annotation process introduces human judgment into the training pipeline, and that judgment carries inherent subjectivity. Two annotators looking at the same image may disagree on whether a partially obscured pedestrian should be labeled, how to classify an ambiguous object at the edge of a frame, or where exactly the boundary of an irregularly shaped item falls. These disagreements, if left unmanaged, propagate through the dataset and create noise that confuses the learning algorithm. Establishing clear guidelines, providing annotator training, and implementing inter-annotator agreement metrics are all essential practices for controlling this variability. Organizations that skip these steps often discover their model failures trace back not to architecture choices or hyperparameter tuning but to inconsistencies buried deep within the training data.
The financial stakes of poor image annotation quality are substantial, particularly in safety-critical applications such as autonomous vehicle perception systems or medical diagnostic tools. A mislabeled training image in an autonomous driving dataset could teach the model to misclassify a cyclist as a road sign, with potentially catastrophic consequences. In healthcare, an inaccurately segmented tumor boundary could lead a diagnostic algorithm to underestimate the size of a malignancy. The cost of fixing these errors after deployment far exceeds the cost of getting annotation right during the data preparation phase. Teams that treat annotation as a low-value outsourcing task rather than a core engineering discipline frequently encounter expensive rework cycles, delayed product launches, and models that fail to meet regulatory approval thresholds.
Bounding Box Annotation Explained
Bounding box image annotation is the most widely used technique in the image annotation field, and it involves drawing a rectangular box tightly around the perimeter of an object of interest within an image. Each box is defined by the pixel coordinates of its top-left and bottom-right corners, and the annotator assigns a class label to the enclosed region. This method is the standard approach for object detection use cases where the goal is to locate and classify discrete items within a scene, such as identifying vehicles, pedestrians, and traffic signals in street imagery. Bounding boxes provide a practical balance between annotation speed and spatial precision, making them the default choice for large-scale projects where millions of images must be processed within tight deadlines. Teams working on deep learning models for object detection frequently begin with bounding box annotation before considering more granular approaches.
The primary limitation of bounding boxes is that they capture a rectangular region that inevitably includes background pixels surrounding irregularly shaped objects. A bounding box around a person walking down a street will also enclose portions of the sidewalk and any adjacent objects that fall within the rectangular frame. For many detection tasks, this trade-off is acceptable because the model learns to focus on the dominant features within the box. Best practices for bounding box annotation require annotators to draw “tight boxes” that enclose the entire object while minimizing the amount of extraneous background included. Loose boxes introduce noise by associating irrelevant visual features with the target class, while boxes that cut off portions of the object impair the model’s ability to recognize incomplete instances. The simplicity and speed of bounding box annotation have made it the backbone of datasets like ImageNet, COCO, and Open Images, which collectively contain hundreds of millions of annotated instances.
Polygon Annotation for Irregular Shapes
While bounding boxes provide fast and efficient labeling, they fall short when objects have complex, non-rectangular contours that require more precise spatial representation in image annotation workflows. Polygon annotation addresses this gap by allowing annotators to place a series of vertices along the outline of an object and connect them to form a closed shape that closely follows its actual boundaries. This technique captures the true silhouette of irregularly shaped items such as vehicles, animals, buildings, and agricultural crops far more accurately than a simple rectangle can. The resulting polygon masks give the model much richer spatial information about where the object begins and where the background ends, which is particularly valuable for applications that require precise localization.
Polygon annotation represents a middle ground between the speed of bounding boxes and the pixel-perfect precision of full segmentation masks. An annotator working with polygons needs to click multiple points around the object’s perimeter, which takes significantly more time per instance than drawing a single rectangle. The number of vertices required depends on the complexity of the object’s shape, with simple geometric objects needing fewer points and organic, curved shapes demanding many more. In autonomous driving contexts, companies like Waymo and Tesla leverage polygon annotations to train their perception systems to identify the exact outlines of pedestrians, lane markings, and road obstacles. The higher labor cost of polygon annotation is justified when the downstream task demands spatial accuracy that bounding boxes simply cannot provide.
Organizations must weigh the trade-offs between polygon and bounding box annotation based on their specific project requirements and constraints. If the use case involves counting objects or detecting their presence within a frame, bounding boxes are typically sufficient and far more cost-effective. If the application requires understanding exact object boundaries for tasks like background removal, content moderation, or precision measurement, polygons deliver the necessary level of detail. Hybrid approaches are also common, where annotators apply bounding boxes to simple objects and reserve polygon annotation for complex or critical items within the same dataset. This strategic allocation of annotation resources optimizes both the quality and the cost-efficiency of the labeling process.
Semantic Segmentation at the Pixel Level
Semantic segmentation takes image annotation to its most granular level by assigning a class label to every single pixel in the image, creating a complete partition of the visual scene into distinct categories. Unlike bounding boxes or polygons, which identify individual objects, semantic segmentation as an image annotation technique classifies the entire image so that every pixel belongs to a defined class such as road, sky, building, vegetation, or vehicle. This comprehensive labeling approach produces dense, pixel-level maps that enable models to understand the full spatial layout of a scene, including the relationships between different regions. Semantic segmentation is essential for applications where the model needs to differentiate between foreground objects and background elements with absolute precision, such as autonomous navigation systems that must distinguish drivable road surfaces from sidewalks and medians.
The computational and labor costs of semantic segmentation are substantially higher than those of bounding box or polygon annotation, because every pixel in the image must receive a label. Annotators typically use specialized tools that allow them to “paint” regions of the image with class-specific colors, and AI-assisted pre-labeling can accelerate this process by generating initial masks that humans then refine. The resulting labeled images serve as training data for encoder-decoder architectures such as UNet, DeepLab, and FCN that learn to produce pixel-level predictions on new, unlabeled images. Semantic segmentation is the annotation technique of choice for any application where understanding the complete spatial composition of a scene is more important than identifying individual object instances.
Instance Segmentation and Object Counting
Instance segmentation builds upon the foundation of semantic segmentation by not only classifying every pixel but also distinguishing between individual objects of the same class within the image annotation output. In a street scene with five pedestrians, semantic segmentation would label all pedestrian pixels with the same class color, while instance segmentation would assign each person a unique identifier so that the model can count and track them independently. This distinction is critical for applications such as crowd monitoring, inventory management, and wildlife census operations where knowing the exact number and location of individual objects directly impacts decision-making. Models trained on instance-segmented data, such as Mask R-CNN, combine the spatial precision of segmentation with the object-level awareness of detection.
The annotation process for instance segmentation requires annotators to create separate masks for each individual object, which is more time-consuming than producing a single class-level mask for semantic segmentation. When objects overlap or occlude one another, the annotator must make judgment calls about where one instance ends and another begins, introducing a layer of complexity that demands clear guidelines and experienced labelers. The COCO dataset pioneered large-scale instance segmentation annotation with over 2.5 million labeled instances across 328,000 images, establishing benchmarks that continue to drive research in the field. Teams evaluating whether to invest in instance segmentation should consider whether their application genuinely requires individual object differentiation or whether semantic-level understanding would suffice at a lower annotation cost.
Panoptic segmentation is an emerging annotation paradigm that unifies semantic and instance segmentation into a single, comprehensive labeling framework. In panoptic annotation, every pixel receives both a class label and, for countable objects (called “things”), an instance identifier, while uncountable regions (called “stuff” like sky or road) receive only class labels. This combined approach produces the most complete possible representation of a visual scene and is increasingly used in autonomous driving and robotics applications where both scene understanding and object tracking are required simultaneously. The progression from bounding boxes to polygons to semantic, instance, and panoptic segmentation represents a spectrum of increasing annotation depth, each level trading speed and cost for richer spatial information.
Keypoint and Landmark Annotation
Keypoint image annotation involves marking specific points of interest on an object, typically the joints and articulation points of the human body, facial features, or structural landmarks on manufactured parts. Each keypoint is defined by its two-dimensional coordinates within the image, and the collection of keypoints across an object forms a skeleton or landmark map that captures spatial relationships and articulation. This technique is fundamental to applications such as human pose estimation, gesture recognition, facial expression analysis, and sports performance tracking. Unlike region-based annotation methods, keypoint annotation is lightweight in terms of data volume but demands high precision in point placement, since even small positional errors can significantly distort the skeleton representation.
The most common use case for keypoint annotation is human pose estimation, where annotators mark the positions of body joints including shoulders, elbows, wrists, hips, knees, and ankles on images of people in various postures. Fitness and sports technology companies use pose-estimated data to build applications that analyze athletic movement, correct exercise form, and track rehabilitation progress. In the medical domain, keypoint annotation enables AI systems to measure anatomical angles, assess gait patterns, and detect postural abnormalities from clinical imagery. Keypoint annotation requires annotators with domain-specific training because the accuracy of landmark placement depends on understanding the anatomical or structural context of the points being marked. Facial landmark detection, another major keypoint application, powers features like face filters in social media apps and driver attention monitoring systems in automotive safety platforms.
Polyline and 3D Cuboid Techniques
Beyond the core image annotation types, specialized techniques such as polyline and 3D cuboid annotation address use cases that standard image annotation methods cannot fully serve. Polyline annotation creates connected line segments that follow linear features in an image, such as lane markings, road edges, power lines, railroad tracks, and cracks in infrastructure surfaces. Unlike closed polygons, polylines remain open-ended and trace paths rather than enclosing areas, making them ideal for annotating elongated, linear structures that extend across the field of view. Autonomous driving datasets rely heavily on polyline annotations to teach perception models where lane boundaries exist so that the vehicle can maintain its position within the correct lane.
Three-dimensional cuboid annotation extends the concept of bounding boxes into three-dimensional space by placing a box that captures the depth, height, and width of an object as viewed from the camera’s perspective. Annotators draw a 3D wireframe around objects such as vehicles, furniture, or shipping containers to provide the model with volumetric information that a flat, two-dimensional bounding box cannot convey. This technique is especially valuable for applications in robotics, warehouse automation, and augmented reality where understanding the spatial extent and orientation of objects in three dimensions is essential for accurate interaction. LiDAR-based autonomous driving systems also use 3D cuboid annotations on point cloud data to train models that must perceive the physical world in full three-dimensional context.
The choice between these specialized annotation types depends entirely on the geometry of the features being labeled and the requirements of the downstream model. Polylines are fast to annotate and produce minimal data overhead, making them a cost-effective choice for linear feature detection tasks. 3D cuboids require more annotator skill and time because the labeler must estimate depth and perspective from a two-dimensional image, but they deliver spatial intelligence that is critical for navigation and manipulation tasks. Teams should resist the temptation to over-annotate by applying complex techniques where simpler methods would suffice, as unnecessary annotation granularity increases cost without improving model performance. A thoughtful matching of annotation type to application need is one of the most impactful decisions in any computer vision project.
Choosing the Right Annotation Type for Your Project
Selecting the appropriate image annotation technique requires balancing four interrelated factors: the complexity of the objects being labeled, the precision required by the downstream task, the scale of the dataset, and the available budget and timeline. A project focused on counting cars in parking lot aerial imagery can achieve excellent results with bounding box annotation, while a project building a surgical robot that must distinguish between tissue types at the pixel level will need semantic or instance segmentation. Starting with the simplest annotation type that meets the model’s requirements is a sound engineering practice that prevents wasted resources and keeps annotation timelines manageable. Many teams begin with bounding boxes for initial model prototyping and then upgrade to more granular annotation types only after confirming that additional spatial detail materially improves model performance.
The downstream task is the single most important consideration in this decision. Object detection models consume bounding boxes or polygons and output predicted locations and class labels for objects in new images. Image segmentation models require pixel-level masks and produce dense spatial maps of the scene. Pose estimation models need keypoint annotations to learn the spatial relationships between landmark points on articulated objects. Mismatching the annotation type to the model architecture creates a fundamental incompatibility that no amount of hyperparameter tuning can resolve. Teams must define their target model architecture before beginning annotation and ensure that the annotation format aligns with the model’s expected input specification.
Dataset scale introduces a practical constraint that often overrides theoretical preferences for image annotation granularity. A research lab annotating a few thousand images for a proof-of-concept can afford pixel-level segmentation masks, but an enterprise project labeling millions of production images may find that segmentation is prohibitively expensive at scale. The data annotation market offers various pricing structures, with bounding box annotation typically costing a fraction of what segmentation annotation commands on a per-image basis. AI-assisted pre-labeling can narrow this gap by generating draft annotations that human reviewers correct rather than create from scratch, but even with automation, segmentation remains the most resource-intensive annotation type. Budgetary realism at the project planning stage prevents costly mid-project pivots when the annotation backlog grows faster than expected.
The decision framework for image annotation type selection should follow a structured evaluation that considers object shape complexity, task-specific precision needs, dataset volume, and total project budget before committing to any single image annotation approach. Teams that invest time in this analysis upfront avoid the common trap of either under-annotating (which limits model accuracy) or over-annotating (which wastes budget and delays deployment). Consulting published benchmarks and case studies from similar projects can provide valuable guidance, since many common computer vision tasks have well-established annotation standards that have been validated across hundreds of research papers and production deployments.
Top Image Annotation Tools and Platforms
The landscape of image annotation tools in 2026 spans open-source platforms, enterprise SaaS solutions, and hybrid image annotation systems that combine both approaches. Open-source tools like CVAT (Computer Vision Annotation Tool), Label Studio, and LabelImg offer flexible, customizable environments that development teams can deploy on their own infrastructure without licensing costs. CVAT, originally developed by Intel, supports bounding boxes, polygons, polylines, keypoints, and segmentation masks across both image and video data, making it one of the most versatile free options available. Label Studio extends beyond image annotation to support text, audio, and time-series data, positioning itself as a multi-modal platform for teams that annotate diverse data types across a single project.
Enterprise platforms such as SuperAnnotate, Encord, Labelbox, and Scale AI provide managed annotation infrastructure with built-in quality assurance dashboards, role-based access controls, and compliance certifications for regulated industries. These platforms typically include AI-assisted pre-labeling features that use trained models to generate draft annotations, reducing the manual workload for human reviewers. SuperAnnotate and Encord natively support all major annotation modalities and offer cloud-based collaboration features that enable distributed annotation teams to work on shared projects in real time. For organizations operating in healthcare or finance, platforms that meet SOC 2, HIPAA, and GDPR compliance standards are essential for protecting sensitive image data throughout the annotation pipeline.
Selecting the right tool depends on the team’s technical capabilities, data security requirements, annotation volume, and integration needs. Small teams with strong engineering resources often prefer open-source tools because of the flexibility to customize workflows and avoid vendor lock-in. Larger organizations with high-volume annotation needs and strict compliance requirements gravitate toward enterprise platforms that provide managed infrastructure, dedicated support, and built-in quality metrics. The most important criterion for tool selection is whether the platform supports all annotation types required by the project and integrates cleanly into the existing machine learning pipeline through standard export formats and API access.
How to Annotate Images for a Computer Vision Project
This section provides a step-by-step guide for teams setting up and executing an image annotation workflow from start to finish.
Step 1: Define Your Annotation Ontology and Guidelines
Before any labeling begins, the project lead must create a detailed annotation ontology that specifies every class the annotators will apply, along with clear definitions and visual examples for each category. The ontology document should include rules for handling edge cases such as partially occluded objects, ambiguous class boundaries, and objects at the extreme edges of the image frame. Include at least five positive and five negative examples for each class to eliminate ambiguity about what qualifies for a given label. A well-constructed ontology reduces inter-annotator disagreement by providing a shared reference that standardizes decision-making across the entire team. Distribute the ontology to all annotators before the project begins and conduct a training session to walk through the guidelines with real sample images. Revisit and update the ontology during the first annotation sprint as edge cases emerge that the initial version did not anticipate.
Pro Tip: Version-control your ontology document using a system like Git so that all annotators always reference the latest guidelines, and changes are tracked with timestamps and rationale.
Step 2: Collect and Prepare Your Image Dataset
Gather images from the relevant domain, ensuring diversity in lighting conditions, camera angles, object sizes, occlusion levels, and environmental contexts to build a training set that generalizes well. Source images from production sensors, public datasets like COCO or Open Images, or domain-specific data collection campaigns tailored to your application’s operating conditions. Clean the dataset by removing duplicates, corrupted files, and images that do not contain relevant content, since low-quality inputs waste annotator time and introduce noise into the training pipeline. Standardize image resolution and format (JPEG, PNG, or WebP) to ensure compatibility with your chosen annotation tool. Organize images into batches of manageable size (typically 500 to 2,000 images per batch) to enable iterative quality reviews and prevent annotator fatigue from overwhelming volume.
Step 3: Select and Configure Your Annotation Tool
Choose an annotation platform that supports the specific annotation types your project requires, whether bounding boxes, polygons, segmentation masks, keypoints, or a combination of these methods. Configure the tool with your class labels, attribute fields, keyboard shortcuts, and any AI-assisted pre-labeling models that can accelerate the initial annotation pass. Set up user accounts with appropriate role-based permissions so that annotators, reviewers, and project managers each have access to the features they need. Test the configuration by running a small pilot annotation batch of 50 to 100 images to verify that the tool behaves as expected and that the export format matches your training framework’s requirements.
Warning: Always verify that your annotation tool’s export format is compatible with your target model framework (COCO JSON, Pascal VOC XML, YOLO TXT) before beginning full-scale annotation, as format mismatches discovered late in the project cause significant rework.
Step 4: Annotate a Calibration Batch and Measure Agreement
Before scaling to the full dataset, have multiple annotators independently label the same calibration batch of 100 to 200 images without consulting each other, and then measure inter-annotator agreement using metrics like Intersection over Union (IoU) for spatial annotations. An IoU threshold of 0.75 or higher between annotators indicates strong alignment with the project guidelines, while lower scores signal that the ontology needs clarification or that additional training is required. Review disagreements as a team, discuss the reasoning behind different labeling decisions, and update the guidelines to resolve ambiguities that caused the discrepancies. This calibration step is critical for establishing a consistent quality baseline before committing resources to annotating thousands of images. Repeat the calibration exercise whenever new annotators join the project or when the ontology changes significantly.
Step 5: Execute Full-Scale Annotation with Quality Checkpoints
Begin annotating the full dataset in batches, with designated reviewers checking a random sample (typically 10% to 20%) of each batch against the quality standards established during calibration. Implement a feedback loop where reviewers flag common errors and communicate corrections to annotators in real time, preventing systematic mistakes from propagating across the dataset. Track annotation metrics including throughput (images per hour), accuracy rate, and the most frequent error types to identify areas where additional annotator training or guideline updates are needed. Use the annotation platform’s built-in quality dashboards if available, or export annotation data for analysis in external tools. Complete each batch with a formal sign-off from the review team before integrating the labeled data into the training pipeline.
Step 6: Export, Validate, and Integrate the Annotated Dataset
Export the completed annotations in the format required by your training framework and run automated validation scripts to check for missing labels, malformed coordinate values, and class distribution imbalances that could bias the model. Split the dataset into training, validation, and test partitions using a ratio such as 70/15/15 or 80/10/10, ensuring that images from the same source or capture session are not split across partitions. Load the annotated data into your training pipeline and run an initial model training cycle to verify that the annotations produce expected learning curves and baseline performance metrics. Store the annotated dataset with version control and metadata documentation so that future team members can understand the labeling methodology and reproduce the training results.
Quality Assurance and Inter-Annotator Agreement
Quality assurance in image annotation is not a single checkpoint but a continuous process that runs in parallel with the image annotation workflow from the first image to the last. The most widely used quantitative metric for annotation quality is Intersection over Union (IoU), which measures the overlap between the predicted annotation and the ground truth annotation, expressed as a ratio between zero and one. Teams typically set minimum IoU thresholds that annotations must meet to be accepted into the dataset, with thresholds of 0.7 to 0.8 being common for bounding boxes and 0.8 to 0.9 for segmentation masks. Annotations that fall below these thresholds are returned to the annotator for correction, creating a feedback loop that progressively improves labeling consistency across the team. Tracking IoU scores over time provides objective visibility into whether annotation quality is improving, stable, or declining as the project progresses.
Inter-annotator agreement (IAA) measures the consistency between multiple human annotators labeling the same images and serves as a proxy for the clarity and completeness of the project’s annotation guidelines. High IAA scores indicate that the guidelines are unambiguous and that annotators share a consistent interpretation of what each label means. Low IAA scores reveal problems in the ontology, gaps in annotator training, or genuine ambiguity in the visual data that requires the guidelines to accommodate multiple valid interpretations. Calculating IAA at regular intervals throughout the project catches drift in annotation consistency before it contaminates a large portion of the dataset. The Cohen’s Kappa statistic and Krippendorff’s Alpha are commonly used measures that account for agreement occurring by chance, providing a more rigorous assessment than simple percentage agreement.
Automated quality checks complement human review by scanning completed annotations for structural errors that are difficult for reviewers to catch manually at scale. These scripts can detect missing labels on objects that are clearly present in the image, overlapping bounding boxes that violate project rules, annotations that extend beyond the image boundaries, and class distributions that deviate significantly from expected proportions. Running automated validation after each annotation batch catches systematic errors early, when the cost of correction is lowest. Combining human expertise for subjective quality judgments with automated systems for structural and statistical validation produces the most reliable annotation datasets. Teams that rely exclusively on one approach at the expense of the other invariably encounter quality gaps that surface only after the data has been used for model training.
The Human-in-the-Loop Approach
The human-in-the-loop (HITL) methodology recognizes that neither fully manual image annotation nor fully automated labeling produces optimal results in isolation, and that the best image annotation outcomes emerge from a collaborative workflow where humans and machines each contribute their respective strengths. In a HITL pipeline, an AI model generates initial annotations automatically through pre-labeling, and human annotators then review, correct, and refine these machine-generated labels to bring them up to the required quality standard. This approach dramatically reduces the time annotators spend on routine labeling tasks while preserving human judgment for complex edge cases that automated systems handle poorly. Leading annotation platforms such as Scale AI and Labelbox have built their entire service models around the HITL paradigm, routing different images to human or automated processing based on the model’s confidence score.
The HITL approach becomes increasingly efficient as the annotation project progresses, because the pre-labeling model improves with each batch of human-corrected data that feeds back into its training cycle. In early project stages, the model’s pre-labels may require substantial human correction, but as it learns from the accumulated corrections, its predictions become progressively more accurate. This virtuous cycle, known as active learning, prioritizes the most uncertain or informative images for human review while allowing the model to handle high-confidence predictions autonomously. Active learning strategies can reduce annotation costs by 40% to 70% compared to fully manual approaches, according to reports on AI-assisted annotation efficiency. The HITL framework is now the standard operating model for large-scale annotation projects across autonomous driving, medical imaging, and retail analytics.
Industries Transformed by Image Annotation
The autonomous vehicle industry represents one of the largest consumers of annotated image data globally, requiring billions of labeled frames to train the perception systems that enable safe self-driving operation through precise image annotation. Vehicles equipped with cameras, LiDAR, and radar sensors generate enormous volumes of visual data that must be annotated with bounding boxes, polygons, segmentation masks, and 3D cuboids before it can be used for model training. Every object class on the road, from pedestrians and cyclists to traffic cones and construction barriers, must be accurately labeled across diverse weather conditions, lighting environments, and geographic contexts. The annotation services market for roadway AI models alone is projected to reach $5.37 billion by 2030, underscoring the scale of investment flowing into this segment. Companies like Waymo, Tesla, and Cruise maintain large in-house and outsourced annotation teams that label millions of images daily to keep their training datasets current with evolving road conditions.
Healthcare imaging is another sector where image annotation has become indispensable for clinical AI development through specialized image annotation workflows. Annotated medical images train diagnostic algorithms that detect cancers in mammograms, identify diabetic retinopathy in retinal scans, and segment organs in CT and MRI volumes. The precision requirements for medical image annotation are exceptionally high because clinical decisions depend on the accuracy of the model’s predictions, and regulatory agencies like the FDA require documented evidence of training data quality for device approval. Annotators working on medical datasets typically possess specialized domain knowledge, such as training in radiology or pathology, that enables them to identify and label anatomical structures and pathological findings with clinical accuracy. The convergence of AI annotation and clinical expertise is creating a new category of skilled professionals who bridge the gap between data science and medicine.
Retail and e-commerce platforms use image annotation to power visual search engines, product recommendation systems, and automated quality inspection pipelines that rely on precise image annotation data. Annotated product images enable computer vision models to identify items on store shelves, detect out-of-stock conditions, verify planogram compliance, and extract product attributes from catalog photographs. Fashion retailers annotate images with fine-grained attributes such as garment type, color, pattern, and style to train recommendation engines that surface visually similar products to shoppers browsing online. The precision of these annotations directly impacts conversion rates and customer satisfaction, as poorly labeled product images lead to irrelevant search results and frustrated users.
Agriculture, manufacturing, and security represent additional sectors where annotated image data is driving automation and AI adoption. In agriculture, annotated aerial and drone imagery trains models that detect crop diseases, estimate yields, and identify weed infestations across vast farmland. In manufacturing, annotated images of production line output enable automated visual inspection systems that catch defects at speeds and consistency levels that human inspectors cannot match. Security and surveillance applications use annotated video data to train models for person detection, vehicle tracking, and anomaly recognition in monitored environments. Across all of these sectors, the quality and volume of annotated training data serve as the primary differentiator between AI systems that deliver production-grade performance and those that fail to meet operational requirements.
Ethical Considerations and Annotator Bias
Every human annotator brings subjective perspectives, cultural backgrounds, and unconscious biases to the image annotation process, and these biases can embed themselves into training datasets in ways that are difficult to detect and costly to correct. When annotation teams lack demographic and cultural diversity, the labels they produce may reflect narrow perspectives that cause the trained model to perform poorly on underrepresented populations or contexts. Facial recognition systems trained on datasets annotated primarily by individuals from one demographic group have demonstrated measurably lower accuracy when applied to faces from other groups, creating discriminatory outcomes that carry real-world consequences. Bias in image annotation is not a theoretical concern but a documented source of algorithmic discrimination that organizations must actively monitor and mitigate throughout the annotation lifecycle. Establishing annotator teams with diverse backgrounds and perspectives is a practical first step toward reducing the risk of biased training data.
The working conditions and compensation of annotators raise additional ethical questions that the industry is increasingly forced to confront. Much of the world’s image annotation labor is performed by workers in lower-cost regions who may receive wages below a living standard, work long hours under monotonous conditions, and have limited recourse when quality disputes arise. Some annotation content, particularly in content moderation and medical imaging, exposes annotators to graphic, disturbing, or emotionally taxing imagery without adequate psychological support. Organizations commissioning annotation work have an ethical responsibility to ensure that their data labeling partners provide fair compensation, reasonable working conditions, and appropriate mental health resources for annotators handling sensitive material. The EU AI Act, which took effect in phases beginning in 2025, introduces regulatory requirements for data quality and governance that place new obligations on organizations using annotated data to train AI systems.
Mitigating annotator bias in image annotation requires a combination of procedural safeguards, technical tools, and organizational commitment to fairness throughout the image annotation pipeline. Diverse annotator recruitment, structured training programs that include bias awareness modules, and regular calibration exercises where annotators discuss and resolve labeling disagreements all contribute to reducing systematic bias. Technical approaches such as computing disagreement rates across demographic subgroups, auditing model performance for disparate accuracy rates, and re-labeling flagged images with independent annotator panels provide quantitative tools for detecting and correcting bias. Organizations that treat bias mitigation as an ongoing process rather than a one-time checkbox produce training datasets that yield fairer, more reliable models across all populations.
Privacy and Regulatory Compliance in Annotation
Image annotation projects frequently involve sensitive visual data that raises significant privacy concerns, particularly when the images used for image annotation contain identifiable faces, license plates, medical records, or location-specific details. The European Union’s General Data Protection Regulation (GDPR) imposes strict requirements on how personal data is collected, stored, processed, and shared, and these requirements apply fully to annotated image datasets that contain identifiable information. Organizations must obtain appropriate consent or establish legitimate legal bases for processing images that depict identifiable individuals, and they must implement technical safeguards such as anonymization, pseudonymization, and access controls to protect annotator and subject privacy throughout the labeling workflow. Failure to comply with GDPR can result in fines of up to 4% of global annual revenue, making privacy compliance a financial imperative as well as an ethical one.
The EU AI Act introduces additional obligations specifically targeting the quality and governance of training data used to build AI systems classified as high-risk. Under this regulation, organizations deploying AI in areas such as autonomous vehicles, medical devices, and law enforcement must demonstrate that their training datasets are relevant, representative, free from errors as far as possible, and appropriate for the intended purpose of the system. In March 2026, the EU AI Act’s data governance mandates began directly increasing demand for compliant data labeling services that can provide the documentation, traceability, and audit trails required by regulators. Organizations operating in regulated domains must embed privacy and compliance requirements into their annotation workflows from the outset, rather than attempting to retrofit compliance after the dataset has been assembled. Annotation platforms that offer built-in compliance features, data residency controls, and audit logging are increasingly preferred by enterprises operating under these regulatory frameworks.
AI-Assisted Annotation and Active Learning
The integration of artificial intelligence into the image annotation workflow itself represents one of the most transformative developments in the image annotation field, shifting the annotator’s role from creator of labels to reviewer and corrector of machine-generated predictions. AI-assisted annotation tools use pre-trained computer vision models to automatically generate draft annotations (bounding boxes, segmentation masks, or keypoint skeletons) on incoming images, which human annotators then validate, correct, and approve. This pre-labeling capability can reduce annotation time by 50% to 70% depending on the complexity of the task and the quality of the pre-trained model, according to industry benchmarks from leading annotation platform providers. The Segment Anything Model (SAM) developed by Meta AI has been particularly influential in this space, enabling annotators to generate precise segmentation masks with minimal manual input across a wide range of object types and visual domains.
Active learning takes AI-assisted image annotation further by intelligently selecting which images should be sent to human annotators based on the model’s uncertainty about its own predictions. Instead of labeling images sequentially or randomly, the active learning system identifies the samples where human input will be most valuable for improving model performance and routes only those images to the annotation queue. High-confidence predictions are automatically accepted, medium-confidence predictions are sent for quick human verification, and low-confidence predictions receive full manual annotation. This prioritization strategy concentrates expensive human annotation effort on the images that provide the greatest marginal improvement to the model, while routine, easy-to-label images are handled automatically. Active learning has made it feasible to build high-performing models with annotated datasets that are 50% to 80% smaller than what fully manual approaches would require.
The convergence of AI-assisted annotation, active learning, and foundation models is reshaping the economics of the image annotation and data annotation industry. Foundation models trained on billions of images can transfer their learned representations to new annotation tasks with minimal task-specific training, enabling accurate pre-labeling even in specialized domains where labeled data is scarce. This capability is particularly valuable in fields like medical imaging and industrial inspection, where domain expertise is expensive and annotated datasets are small. As these AI-assisted tools mature, the annotation industry is evolving from a labor-intensive, manual-first model toward a technology-driven, review-first model where human annotators serve as quality gatekeepers rather than primary content creators. The organizations and platforms that successfully navigate this transition will capture the majority of value in the rapidly growing annotation market.
The Future of Image Annotation Technology
The image annotation field is evolving rapidly as advances in generative AI, foundation models, and automated quality assurance reshape how organizations create training data for computer vision systems through image annotation. The global data annotation tools market, valued at approximately USD 8.26 billion in 2026, is projected to grow at over 20% annually through 2035, driven by the insatiable demand for labeled visual data across autonomous driving, healthcare, retail, and manufacturing applications. Foundation models capable of zero-shot and few-shot annotation are reducing the amount of manually labeled data required to train specialized models, while multimodal AI systems that understand both text and images are enabling annotation through natural language instructions rather than manual drawing. These developments are not eliminating the need for human annotators but are fundamentally changing what annotators do, shifting their focus from routine labeling to complex judgment tasks that machines cannot yet handle reliably.
Synthetic data generation is emerging as a complementary strategy that reduces dependence on real-world image collection and annotation by producing photorealistic rendered images with automatically generated ground-truth labels. Game engines and neural rendering pipelines can create vast quantities of training images depicting scenarios that are rare, dangerous, or expensive to capture in the real world, such as pedestrian collisions, surgical complications, or extreme weather driving conditions. Because the labels are generated programmatically during the rendering process, synthetic data arrives fully annotated at near-zero marginal annotation cost. Combining synthetic and real-world annotated data in training pipelines has shown promising results in improving model robustness, particularly for safety-critical applications where edge cases are disproportionately important.
The regulatory landscape is also shaping the future of image annotation as governments worldwide implement frameworks that mandate transparency, traceability, and quality standards for AI training data. The EU AI Act’s requirements for data governance documentation, bias assessment, and dataset provenance are establishing compliance standards that annotation providers must meet to serve the European market. Similar regulatory initiatives are emerging in the United States, Canada, China, and India, creating a patchwork of requirements that multinational organizations must navigate when building global AI training datasets. Annotation platforms that offer built-in compliance features, audit trails, and data residency controls will have a significant competitive advantage as regulatory requirements continue to tighten across jurisdictions.
The future of image annotation lies at the intersection of human expertise, AI automation, regulatory compliance, and economic efficiency, and the organizations that master all four dimensions will build the training data infrastructure that powers the next generation of computer vision systems. As AI-driven automation continues to accelerate across industries, the demand for accurately annotated visual data will only intensify, making image annotation one of the most critical capabilities in the broader AI value chain. Teams that invest in scalable annotation infrastructure, ethical data practices, and advanced quality assurance workflows today are positioning themselves to lead in an era where the quality of training data is the primary competitive differentiator for computer vision applications.
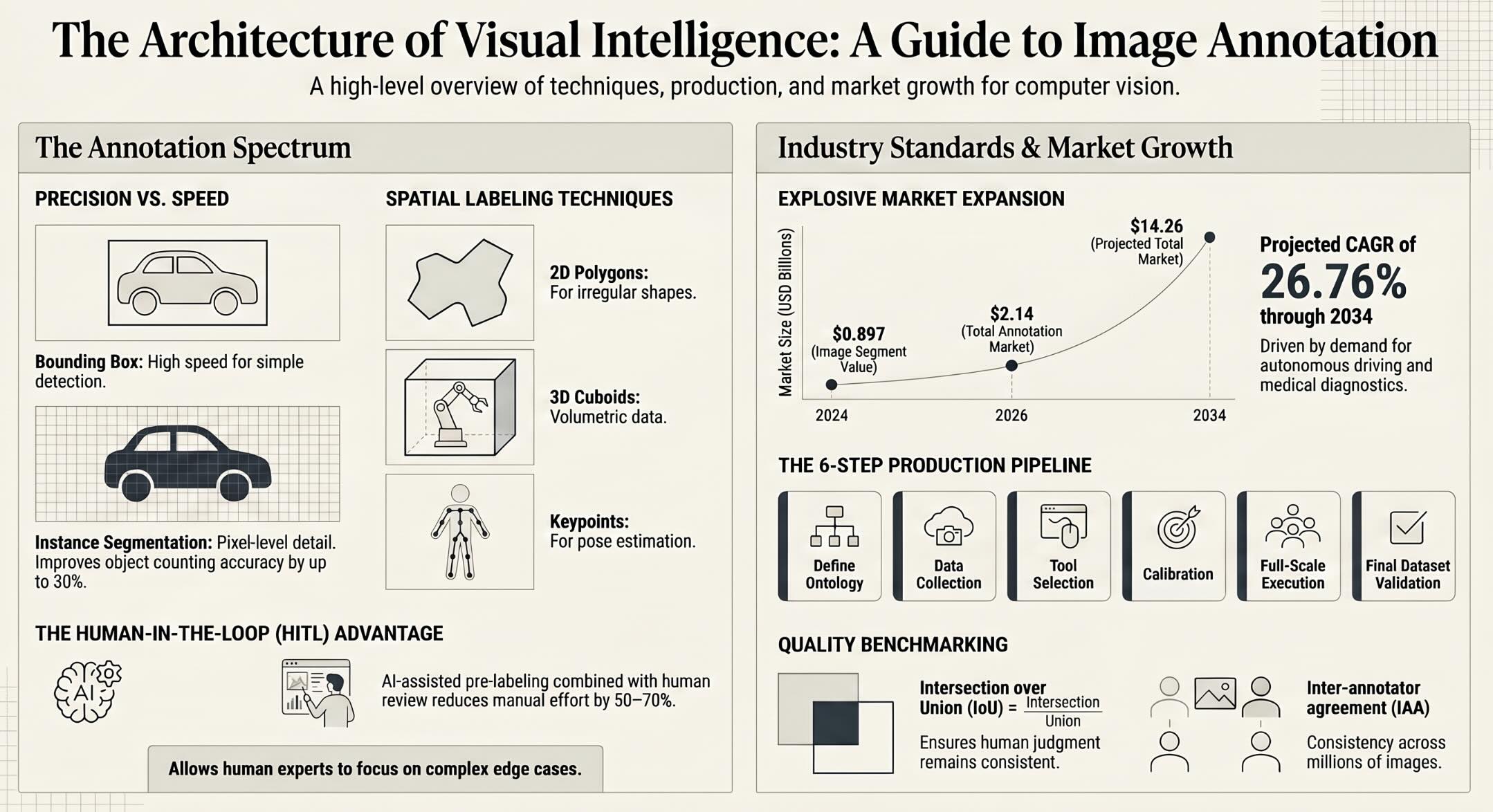
Key Insights on the Image Annotation Market
- The global data annotation tool market is projected to grow from USD 2.14 billion in 2026 to USD 14.26 billion by 2034, reflecting a 26.76% CAGR driven by rapid AI adoption across industries.
- Image and video annotation accounts for approximately 41% of the total data annotation market share, making it the largest segment ahead of text and audio annotation.
- Models trained with instance segmentation annotations outperform those trained with bounding boxes alone by up to 30% on object counting tasks, demonstrating the direct impact of annotation granularity on model accuracy.
- The autonomous vehicle annotation services market is projected to expand from $1.89 billion in 2025 to $5.37 billion by 2030, growing at a 23% CAGR as perception systems demand more labeled training frames.
- Cloud-based annotation platforms now account for over 45% of market usage due to their scalability, remote workforce enablement, and real-time collaboration capabilities.
- In machine learning projects across all industries, more than 80% of engineering labor is devoted to data preparation and labeling, underscoring annotation’s dominant position in the AI development lifecycle.
- The Image Annotation segment was valued at $0.897 billion in 2024 and is projected to reach $3.5 billion, driven by demand from computer vision applications in autonomous vehicles, healthcare, and retail.
- Companies can spend up to 30% of their AI development budgets on data labeling alone, making annotation cost optimization a strategic priority for AI-driven organizations.
The image annotation industry is experiencing a structural transformation driven by the convergence of three forces: the explosive growth of AI applications requiring visual training data, the maturation of AI-assisted annotation tools that reduce manual labor, and the emergence of regulatory frameworks that mandate data quality standards. These forces are creating a market where demand for annotation services is growing faster than the supply of qualified annotators, pushing organizations toward technology-driven solutions that amplify human productivity. The shift from fully manual annotation to hybrid human-AI workflows is not merely an efficiency improvement but a fundamental restructuring of how training data is produced. Organizations that continue to rely on purely manual annotation processes will find themselves at a growing cost and speed disadvantage compared to competitors that have adopted AI-assisted pipelines. The winners in this evolving landscape will be the platforms and service providers that deliver the highest annotation quality at the lowest cost per label while meeting increasingly stringent regulatory and ethical standards.
| Dimension | Traditional Manual Annotation | AI-Assisted Annotation |
|---|---|---|
| Transparency | Limited visibility into annotator decisions and rationale | Full audit trails with confidence scores and automated logging |
| Participation | Small teams of specialized annotators working sequentially | Distributed global workforce with AI co-pilots reviewing pre-labels |
| Trust | Quality depends entirely on annotator skill and diligence | Quality backed by quantitative metrics, automated checks, and human review |
| Decision Making | Annotators make all labeling decisions independently | AI handles routine decisions, humans focus on edge cases and complex judgments |
| Misinformation Risk | Human errors propagate silently through large datasets | Automated anomaly detection flags inconsistencies before they reach training |
| Service Delivery | Throughput limited by human labeling speed (50-200 images per annotator per day) | Pre-labeling accelerates throughput by 50-70%, enabling faster project delivery |
| Accountability | Difficult to trace errors back to individual annotation decisions | Version-controlled labels with annotator attribution and revision history |
How Organizations Use Image Annotation in Practice
Waymo’s Autonomous Vehicle Perception Pipeline
Waymo, Alphabet’s self-driving technology subsidiary, operates one of the most extensive image annotation programs in the autonomous vehicle industry. The company annotates millions of sensor frames captured by its fleet of test vehicles across diverse urban and suburban environments, applying bounding boxes, 3D cuboids, and semantic segmentation masks to objects including vehicles, pedestrians, cyclists, and road infrastructure. According to Waymo’s published research, its perception models process data from cameras, LiDAR, and radar sensors that are fused into a unified representation of the driving environment. The annotation pipeline achieves sub-pixel accuracy on critical object classes through a multi-stage review process involving both automated validation and expert human review. One limitation critics have noted is that Waymo’s training data, while vast, is concentrated in the relatively small number of U.S. cities where its fleet operates, potentially limiting the model’s generalization to driving environments with fundamentally different road infrastructure, traffic patterns, and regulatory contexts.
iMerit’s Medical Imaging Annotation Services
iMerit, a data labeling company with operations in India, Bhutan, and the United States, has built a specialized practice around medical image annotation for AI-driven diagnostic tools. The company employs annotators with clinical training who label pathological features in radiology images, histopathology slides, and ophthalmic scans at the pixel level to train diagnostic algorithms developed by healthcare technology companies. According to iMerit’s case study publications, their annotation teams have processed datasets for applications including tumor detection in mammography, lesion identification in dermatology, and organ segmentation in CT scans, with documented accuracy rates exceeding 97% on validated benchmarks. The measurable outcome is that AI models trained on iMerit-annotated data have achieved diagnostic accuracy comparable to board-certified radiologists in multiple peer-reviewed studies. A noted limitation is the scalability challenge: training clinical annotators requires months of domain-specific education, and the supply of qualified medical image annotators remains significantly below the growing demand from healthcare AI developers.
Scale AI’s Enterprise Data Labeling Platform
Scale AI has grown into one of the largest commercial data annotation platforms by combining AI-assisted pre-labeling with a distributed workforce of human annotators to deliver labeled datasets at enterprise scale. The company serves major autonomous vehicle manufacturers, defense contractors, and technology companies, providing annotation services across image, video, text, LiDAR, and satellite data modalities. According to Scale AI’s reported contracts, the company processes hundreds of millions of annotations annually and has secured over $1.2 billion in autonomous vehicle-related contracts alone. Scale AI’s platform uses active learning to route images to human annotators based on model uncertainty, concentrating expensive human effort on the most informative samples while handling routine labeling automatically. A persistent critique of Scale AI’s model is its reliance on a globally distributed gig workforce, which raises questions about annotator compensation equity, data security across international boundaries, and the consistency of quality standards applied by workers with varying levels of training and domain expertise.
Lessons From Large-Scale Image Annotation Deployments
Case Study: Tesla’s Auto-Labeling Infrastructure
Tesla faced the challenge of annotating the petabytes of camera data collected by its global fleet of vehicles equipped with eight cameras each, generating far more visual data than any human annotation workforce could process manually. The company developed an auto-labeling system that uses its own neural networks to generate draft annotations on raw fleet data, creating a self-reinforcing loop where the driving model’s predictions serve as initial labels that human reviewers then validate and correct. Tesla’s approach reduced the cost per annotated frame dramatically compared to traditional manual annotation methods, enabling the company to scale its training dataset to billions of annotated images that would have been economically impossible to label through conventional means. According to Tesla’s AI Day presentations, the auto-labeling pipeline enabled a 10x increase in annotation throughput while maintaining accuracy standards that met the company’s internal benchmarks for safety-critical perception. Critics argue that Tesla’s reliance on its own model’s predictions for label generation introduces circular reasoning risks, where systematic errors in the model’s perception could become self-reinforcing through the annotation feedback loop.
Case Study: Google’s Open Images Dataset Initiative
Google undertook the challenge of creating one of the world’s largest publicly available annotated image datasets to accelerate computer vision research and democratize access to high-quality training data. The Open Images dataset contains over 9 million images annotated with image-level labels, object bounding boxes, visual relationships, instance segmentations, and localized narratives contributed by a combination of automated systems and human annotators. Google used a machine-learning-assisted annotation pipeline that generated candidate labels automatically and then routed them to human verifiers who confirmed or corrected each prediction, achieving a throughput that would have been impossible with purely manual methods. The dataset’s impact on the research community has been substantial, with thousands of published papers citing Open Images as their primary training or evaluation resource. One limitation of the Open Images approach is the inherent bias introduced by the automated label generation step, which tends to favor objects that the pre-trained model already recognizes well while underrepresenting rare or culturally specific object categories that the model handles poorly.
Case Study: Appen’s Crowd-Sourced Annotation at Global Scale
Appen, a publicly listed data annotation company, built its business model around coordinating a global crowd of over one million annotators distributed across more than 170 countries to label datasets at massive scale for enterprise AI customers. The company’s distributed workforce model enables rapid scaling of annotation capacity to meet client demand spikes, with projects that would take months for an in-house team completed in weeks through parallelized crowd annotation. According to Appen’s public filings, the company has delivered annotated datasets for applications spanning autonomous driving, natural language understanding, content moderation, and agricultural computer vision. The global distribution of Appen’s workforce provides a natural advantage for projects requiring cultural and linguistic diversity in annotation, as annotators from different regions bring local knowledge that improves the accuracy of labels for region-specific content. The primary controversy surrounding Appen’s model involves annotator compensation, with critics pointing out that pay rates vary significantly by country and that crowd workers lack the employment protections, benefits, and career development opportunities available to full-time annotation staff.
Frequently Asked Questions About Image Annotation for Machine Learning
Image annotation is the process of adding labels, bounding boxes, segmentation masks, or keypoints to digital images so that supervised machine learning models can learn to recognize and classify visual content. Annotated images serve as the ground truth that models use to compare their predictions against during training. The quality and consistency of these annotations directly determine the accuracy ceiling of the resulting model.
The most common types are bounding boxes for object detection, polygons for irregular shape outlining, semantic segmentation for pixel-level classification, instance segmentation for individual object identification, and keypoint annotation for marking landmark positions. Each type offers a different trade-off between labeling speed, spatial precision, and cost per image. The choice depends on the specific computer vision task the model will perform.
Costs vary widely based on annotation type, image complexity, and the provider’s location, ranging from $0.02 to $0.10 per image for bounding boxes to $1.00 to $10.00 or more per image for detailed semantic segmentation. AI-assisted pre-labeling can reduce costs by 40% to 60% compared to fully manual methods. Enterprise annotation platforms typically offer volume-based pricing that decreases the per-image cost as project scale increases.
Leading tools include CVAT and Label Studio among open-source options, and SuperAnnotate, Encord, Labelbox, and Scale AI among enterprise platforms. The best choice depends on your annotation types, team size, compliance requirements, and budget. Open-source tools offer flexibility and zero licensing cost, while enterprise platforms provide managed infrastructure and built-in quality assurance.
Quality assurance requires a combination of clear annotation guidelines, inter-annotator agreement measurement using metrics like IoU, regular calibration exercises, reviewer sampling of completed batches, and automated validation scripts. Tracking quality metrics over time helps identify annotation drift before it affects model performance. Implementing a formal review and feedback loop between annotators and quality reviewers is essential for maintaining standards at scale.
Semantic segmentation assigns a class label to every pixel but does not distinguish between individual objects of the same class, while instance segmentation identifies and separates each individual object with a unique mask. For example, semantic segmentation labels all pedestrians in one color, while instance segmentation gives each pedestrian a different identifier. Instance segmentation is necessary for tasks that require counting or tracking individual objects.
AI-assisted annotation uses pre-trained machine learning models to generate draft labels on incoming images, which human annotators then review, correct, and approve. This approach reduces manual labeling time by 50% to 70% and allows annotators to focus on correcting errors rather than creating labels from scratch. Active learning algorithms further improve efficiency by prioritizing the most uncertain images for human review.
Annotation bias occurs when labeling decisions reflect the subjective perspectives of annotators rather than objective ground truth, causing the trained model to reproduce those biases in its predictions. Biased annotations can lead to models that perform well on majority groups but poorly on underrepresented populations, creating discriminatory outcomes. Mitigating bias requires diverse annotator teams, structured guidelines, regular calibration, and quantitative auditing of model performance across demographic subgroups.
Inter-annotator agreement (IAA) measures the consistency between multiple annotators labeling the same images and indicates how well the annotation guidelines are understood and applied. High IAA scores suggest clear, unambiguous guidelines, while low scores reveal problems that need immediate attention. Common IAA metrics include Cohen’s Kappa, Krippendorff’s Alpha, and Intersection over Union for spatial annotations.
Autonomous vehicles, healthcare, retail, agriculture, manufacturing, and security are the largest consumers of image annotation services. The autonomous vehicle sector alone is projected to spend over $5 billion annually on annotation services by 2030. Each industry has unique annotation requirements, from 3D cuboids in autonomous driving to pixel-level segmentation in medical imaging.
The EU AI Act mandates that organizations using AI systems classified as high-risk must demonstrate that their training data is relevant, representative, and free from errors as far as possible. These requirements are increasing demand for annotation providers that can deliver documented data governance, traceability, and bias assessment capabilities. Organizations serving the European market must now embed compliance into their annotation workflows from the outset.
The field is moving toward hybrid human-AI workflows where foundation models generate increasingly accurate pre-labels and human annotators serve as quality reviewers rather than primary labelers. Synthetic data generation, multimodal annotation through natural language instructions, and regulatory compliance automation are all reshaping how organizations create training data. The annotation market is projected to grow at over 20% annually through 2035, driven by the expanding demand for labeled visual data across industries.
Full automation remains elusive for most real-world annotation tasks because edge cases, ambiguous visual content, and domain-specific judgment calls still require human expertise. AI-assisted tools have dramatically reduced the proportion of images requiring full manual annotation, but human oversight remains essential for maintaining quality standards. The most effective approach is a human-in-the-loop model where automation handles routine labeling and humans focus on complex decisions.
The most common formats include COCO JSON (supporting bounding boxes, segmentation masks, and keypoints), Pascal VOC XML (primarily for bounding boxes), and YOLO text files (optimized for real-time detection pipelines). Choosing the correct export format before beginning annotation ensures compatibility with the target training framework. Most modern annotation platforms support multiple export formats, allowing teams to switch between frameworks without re-annotating.
Dataset size depends on the complexity of the task, the number of classes, and the model architecture, but a rough guideline is 1,000 to 5,000 annotated images per class for object detection and 500 to 2,000 per class for segmentation with transfer learning. Active learning and data augmentation techniques can significantly reduce the number of manually annotated images needed. Starting with a smaller pilot dataset and expanding based on model performance metrics is a cost-effective strategy for right-sizing the annotation effort.