Introduction
Natural language processing allows computers to interpret and analyze human language. Before machines can understand text, however, the text must first be broken into smaller units that algorithms can process. This foundational step is known as tokenization.
Tokenization converts raw text into tokens, which represent smaller segments of language such as words, characters, or subwords. Machine learning models use these tokens as the basic input for language analysis tasks. Without tokenization, computers would struggle to interpret sentences because language contains complex grammatical structures and irregular spacing. Modern artificial intelligence systems rely heavily on tokenization when processing large volumes of text. From chatbots and search engines to translation tools and recommendation systems, tokenization allows algorithms to convert language into a structured format that machine learning models can analyze.
Readers who want to understand the broader foundations of artificial intelligence can explore Understanding Artificial Intelligence. The underlying machine learning concepts behind these systems are explained further in How Artificial Intelligence Works
Understanding tokenization helps reveal how computers transform human language into numerical data that machine learning algorithms can process. This article was last reviewed and updated in March 2026 to reflect how tokenization functions within large language models, modern transformer architectures, and current AI development tools.
What Is Tokenization in NLP
Tokenization in natural language processing is the process of splitting text into smaller units called tokens. These tokens may represent words, characters, or subwords that machine learning models analyze when interpreting language. Tokenization allows NLP systems to convert human language into structured data suitable for computational analysis.
Key Takeaways
- Tokenization breaks text into smaller units called tokens that machine learning models can analyze.
- Tokens may represent words, characters, or subword fragments depending on the algorithm used.
- Modern natural language processing systems rely heavily on tokenization before performing tasks such as translation or sentiment analysis.
- Tokenization plays a crucial role in large language models and transformer based architectures.
Table of contents
- Introduction
- What Is Tokenization in NLP
- Key Takeaways
- What Is Tokenization in Natural Language Processing
- Why Tokenization Is Important in NLP
- How Tokenization Works
- Types of Tokenization
- Tokenization in Transformer Models
- Tokenization Algorithms Used in NLP
- How Tokenization Affects Token Limits in Large Language Models
- Tokenization in Modern AI Systems: GPT, Claude, and Gemini
- Example of Tokenization Using Python
- Tokenization Comparison
- Frequently Asked Questions About Tokenization in NLP
- Conclusion
- References
What Is Tokenization in Natural Language Processing
Tokenization is the process of splitting text into smaller pieces known as tokens. These tokens form the basic units that natural language processing models analyze when interpreting language.
A token may represent a word, a phrase, or even a character depending on how the algorithm is designed. For example, a simple sentence can be separated into individual words so that each word becomes a token.
Consider the sentence:
Artificial intelligence is transforming healthcare.
A basic word tokenization process might produce the following tokens:
- Artificial
- intelligence
- is
- transforming
- healthcare
Each token becomes a discrete unit that machine learning models can analyze and convert into numerical representations.
Tokenization therefore acts as the first step in most natural language processing pipelines.
Source: YouTube | Tokenization.
Why Tokenization Is Important in NLP
Human language contains ambiguity, punctuation, and complex grammatical structures that computers cannot interpret directly. Tokenization helps simplify language by breaking sentences into manageable components. Machine learning models rely on tokens because algorithms process numerical representations rather than raw text. After tokenization occurs, each token is mapped to a numerical vector that represents its meaning within a dataset.
This conversion allows artificial intelligence systems to perform tasks such as:
- language translation
- sentiment analysis
- speech recognition
- text classification
- question answering
Many of these technologies influence everyday digital experiences described in Living with AI
Tokenization therefore plays a crucial role in enabling computers to understand and process human language effectively.
How Tokenization Works
Tokenization typically occurs early in the natural language processing pipeline. The process begins when raw text enters an NLP system. The algorithm analyzes the text and divides it into smaller segments according to predefined rules.
Simple tokenization techniques split text based on whitespace and punctuation. More advanced tokenizers analyze linguistic patterns and statistical relationships within large datasets. Once tokens are created, the NLP system converts them into numerical representations known as embeddings. Machine learning models analyze these embeddings to identify patterns and relationships between words.
This process allows algorithms to recognize meaning, context, and relationships between language components. Understanding how these patterns emerge also connects to techniques used in machine learning systems discussed in How Do You Teach Machines to Recommend. Although recommendation systems analyze behavior rather than language, both technologies rely on similar pattern recognition methods.
How AI Breaks Text into Tokens
Tokenization is the first step in NLP. AI splits a sentence into smaller pieces called tokens.
Types of Tokenization
Different tokenization strategies exist depending on the requirements of the language model.
Word Tokenization
Word tokenization is the simplest form of tokenization. The algorithm splits sentences into individual words based on spaces and punctuation.
For example, the sentence:
Machine learning improves healthcare diagnostics
would become the following tokens:
- Machine
- learning
- improves
- healthcare
- diagnostics
Word tokenization works well for many languages but struggles when words contain multiple meanings or grammatical variations.
Character Tokenization
Character tokenization breaks text into individual characters instead of words. Each letter becomes a token.
For example:
AI improves medicine
becomes:
- A
- I
- i
- m
- p
- r
- o
- v
- e
- s
Character tokenization allows models to handle unusual words and spelling variations. However, it increases the number of tokens dramatically and may slow model training.
Subword Tokenization
Subword tokenization splits words into smaller fragments known as subwords. This approach balances the strengths of word and character tokenization.
For example, the word:
unbelievable
may be broken into tokens such as:
- un
- believe
- able
Subword tokenization allows models to understand unfamiliar words by combining known subword components.
Many modern NLP systems rely on subword tokenization techniques. According to Hugging Face’s NLP course, subword tokenization is now the dominant approach across virtually all production transformer models due to its balance between vocabulary size and coverage of rare words.
Tokenization in Transformer Models
Modern language models such as GPT and BERT rely heavily on advanced tokenization techniques. These models use subword tokenization methods such as Byte Pair Encoding and WordPiece tokenization. These algorithms identify frequently occurring character sequences within large text datasets. The tokenizer then builds a vocabulary of common subword units.
When the model encounters a word outside its vocabulary, the tokenizer breaks the word into smaller subword tokens that the model can understand. Transformer models analyze relationships between tokens rather than entire sentences. This approach allows models to capture contextual meaning and perform complex language tasks such as summarization, translation, and conversational dialogue.
Many of the broader developments shaping these technologies are discussed in AI in Current Trends and Future Predictions.
Transformer based models – the State of The Art (SOTA) Deep Learning architectures in NLP – process the raw text at the token level. Similarly, the most popular deep learning architectures for NLP like RNN, GRU, and LSTM also process the raw text at the token level.
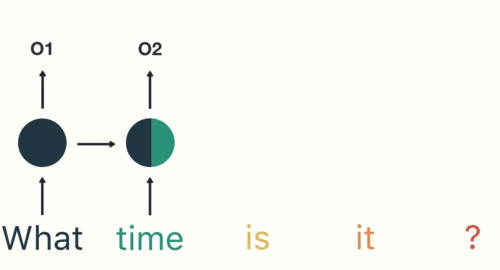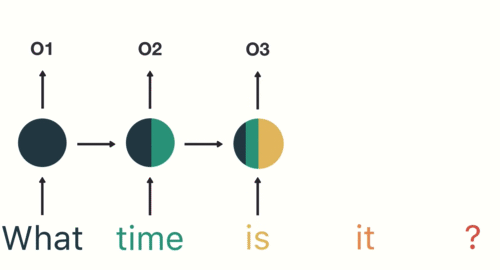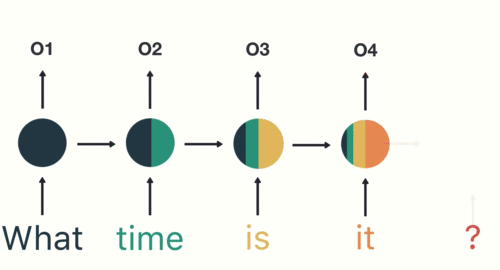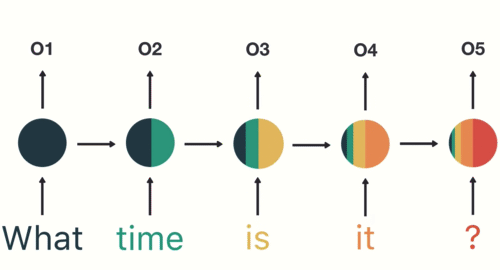
Hence, Tokenization is the foremost step while modeling text data. Tokenization is performed on the corpus to obtain tokens. The following tokens are then used to prepare a vocabulary. Vocabulary refers to the set of unique tokens in the corpus. Remember that vocabulary can be constructed by considering each unique token in the corpus or by considering the top K frequently occurring words.
Now, let’s understand the usage of the vocabulary in Traditional and Advanced Deep Learning-based NLP methods.
Traditional NLP approaches such as Count Vectorizer and TF-IDF use vocabulary as features. Each word in the vocabulary is treated as a unique feature:
In Advanced Deep Learning-based NLP architectures, vocabulary is used to create the tokenized input sentences. Finally, the tokens of these sentences are passed as inputs to the model.
Tokenization Algorithms Used in NLP
Modern natural language processing systems rely on specialized tokenization algorithms. These algorithms help models handle complex language patterns and large vocabularies.
Byte Pair Encoding BPE
Byte Pair Encoding is a widely used tokenization method. It splits words into frequently occurring character sequences.
BPE begins with characters as tokens. The algorithm repeatedly merges common character pairs.
For example, the word unbelievable may be split into subword tokens such as:
- un
- believe
- able
BPE reduces vocabulary size while preserving meaning. Many transformer based language models rely on BPE tokenizers.
WordPiece Tokenization
WordPiece tokenization is used in models such as BERT. It builds a vocabulary of common word fragments.
The algorithm selects subwords that maximize probability during training. Rare words are decomposed into familiar fragments.
For example, the word tokenization may be split into:
token
ization
This approach improves model accuracy when encountering unfamiliar words.
SentencePiece Tokenization
SentencePiece treats text as a continuous sequence of characters. It does not depend on whitespace boundaries.
This approach works well for languages that do not separate words with spaces, such as Chinese and Japanese.
SentencePiece supports algorithms such as:
- Byte Pair Encoding
- Unigram language model tokenization
Many multilingual NLP systems use SentencePiece tokenization.
How Tokenization Affects Token Limits in Large Language Models
Large language models process input using tokens instead of words. Each word or subword fragment becomes a token.
Language models have limits on how many tokens they can process in a single request.
| Model | Approximate Token Limit |
|---|---|
| GPT 3 | 4096 tokens |
| GPT 4 | 8000 to 32000 tokens |
| GPT 4 Turbo | Up to 128000 tokens |
Long documents require more tokens. Tokenization therefore determines how much text a model can analyze. A sentence with complex words may produce more tokens. This increases computational cost and processing time. Understanding tokenization helps developers optimize prompts and training datasets.
OpenAI’s tokenizer documentation provides a live tool that demonstrates how text is split into tokens, making it possible to test any sentence or document before sending it to the API.
Tokenization in Modern AI Systems: GPT, Claude, and Gemini
Tokenization strategies have become a critical engineering decision in the development of modern large language models. GPT-4 and subsequent OpenAI models use Byte Pair Encoding through the tiktoken library, which produces tokens averaging approximately 4 characters in English text. This means a standard page of text containing around 750 words generates roughly 1,000 tokens, a ratio developers must account for when designing prompts and managing context windows.
Anthropic’s Claude models use a similar subword tokenization approach, calibrated for efficient context utilization across long documents and multi-turn conversations. Google’s Gemini family relies on SentencePiece-based tokenization, which handles multilingual inputs particularly well and allows a single tokenizer to work across dozens of languages without requiring language detection preprocessing.
The expansion of context windows across current-generation models has made tokenization efficiency increasingly important. A model processing 100,000 tokens in a single request must tokenize, embed, and attend over each of those units, meaning that tokenization design choices directly influence both inference cost and response latency. Developers working with retrieval-augmented generation pipelines, where long documents are chunked and retrieved for injection into prompts, must understand how their tokenizer handles chunk boundaries to avoid splitting meaningful semantic units across tokens.
One emerging pattern is tokenizer-aware chunking, in which document processing pipelines split text not at arbitrary character counts but at natural token boundaries. This ensures that language models receive semantically coherent input segments and produce more accurate retrievals and summaries. Tools such as LangChain and LlamaIndex have built tokenizer-aware chunking directly into their document processing pipelines, reflecting how central tokenization has become to production AI engineering. According to the Stanford HAI 2024 AI Index, the deployment of large language models across enterprise applications grew significantly in 2024, with tokenization and context management cited as core technical considerations by engineering teams.
Example of Tokenization Using Python
Developers often implement tokenization using Python libraries such as NLTK.
The following example demonstrates basic word tokenization.
from nltk.tokenize import word_tokenizetext = "Artificial intelligence is transforming healthcare."tokens = word_tokenize(text)print(tokens)Output:
['Artificial', 'intelligence', 'is', 'transforming', 'healthcare']Each token becomes an input element for machine learning models.
Developers also use libraries such as:
- spaCy
- Hugging Face Tokenizers
- TensorFlow Text
These tools support advanced tokenization methods for modern NLP systems.
Tokenization Comparison
Different tokenization strategies serve different natural language processing tasks.
| Tokenization Type | Example | Use Case |
|---|---|---|
| Word Tokenization | AI is powerful | Traditional NLP pipelines |
| Character Tokenization | A I i s | Spelling correction and noisy text |
| Subword Tokenization | un believe able | Large language models |
| Byte Pair Encoding | token ization | Transformer based models |
| WordPiece | play ing | BERT and similar architectures |
Subword tokenization now dominates modern NLP systems. It balances vocabulary size with contextual understanding.
Tokenization Challenges
Tokenization may appear straightforward, but real language introduces several challenges. Languages differ widely in structure and grammar. Some languages do not use spaces between words, making tokenization more complex. Chinese and Japanese text, for example, requires specialized segmentation algorithms.
Another challenge involves punctuation and contractions. Words such as “don’t” may be treated as one token or split into multiple tokens depending on the tokenizer. Named entities, abbreviations, and emojis also create difficulties for tokenization algorithms. Developers therefore design tokenization systems carefully to ensure that tokens preserve meaning while remaining computationally efficient.
Tokenization vs Stemming vs Lemmatization
Tokenization often appears alongside other text preprocessing techniques such as stemming and lemmatization. Although these processes work together in many NLP pipelines, they perform different tasks. Tokenization splits text into tokens. Stemming reduces words to their root form by removing suffixes. For example, “running” may become “run.”
Lemmatization performs a similar function but uses linguistic rules to determine the correct base form of a word. Together these techniques help prepare text for machine learning analysis.
Real World Applications of Tokenization
Tokenization enables a wide range of natural language processing applications. Search engines use tokenization to interpret user queries and match them with relevant documents. Chatbots rely on tokenization to interpret user input and generate responses. Machine translation systems analyze tokens when converting text from one language to another. Sentiment analysis systems evaluate tokens to determine whether text expresses positive or negative opinions. Recommendation platforms may also analyze text tokens when interpreting user reviews and feedback. These technologies influence digital experiences across many industries including healthcare, finance, education, and entertainment.
Frequently Asked Questions About Tokenization in NLP
Tokenization is the process of dividing text into smaller components called tokens for machine learning analysis. For example, the sentence ‘Artificial intelligence improves healthcare’ becomes four tokens: artificial, intelligence, improves, and healthcare. Modern systems use subword tokenization, which can split unfamiliar words like ‘tokenization’ into fragments such as ‘token’ and ‘ization’ that the model already understands.
Tokenization is essential because machine learning algorithms cannot process raw text directly. Language must first be converted into structured units that algorithms can analyze. Tokens allow models to map language into numerical vectors that represent semantic meaning. This step enables NLP systems to perform tasks such as translation, sentiment analysis, and text classification.
The most common types of tokenization include word tokenization, character tokenization, and subword tokenization. Word tokenization divides sentences into words. Character tokenization splits text into individual characters. Subword tokenization divides words into smaller fragments that help models interpret unfamiliar vocabulary.
Subword tokenization breaks words into smaller units that capture meaningful fragments of language. Instead of treating every word as a unique token, the algorithm learns common subword patterns from large datasets. This approach allows models to interpret rare or unfamiliar words by combining known subword components.
Large language models such as GPT-4, Claude, and Gemini rely on tokenization to convert text into numerical inputs before processing. Tokenizers transform sentences into sequences of tokens using algorithms such as Byte Pair Encoding or SentencePiece. Each token is mapped to a numerical embedding representing semantic meaning. Most English text produces roughly one token per four characters, meaning a 750-word document generates approximately 1,000 tokens.
Tokenization splits text into tokens, while stemming reduces words to their root forms. Tokenization prepares text for machine learning analysis, whereas stemming simplifies vocabulary by removing suffixes. These processes often work together during text preprocessing in NLP systems.
Tokenization faces challenges when processing languages without clear word boundaries such as Chinese, Japanese, or Thai, which require specialized segmentation. Other challenges include handling contractions such as ‘don’t,’ named entities, emojis, code, and mathematical expressions. Tokenizers must also balance vocabulary size against coverage — too small a vocabulary creates many unknown tokens, while too large a vocabulary increases memory requirements and slows training.
Tokenization supports technologies across many industries including search engines, chatbots, healthcare analytics, finance, and social media analysis. Any system that processes large volumes of text data relies on tokenization as part of the natural language processing pipeline.
In NLP, tokenization refers to splitting text into smaller units called tokens that machine learning models can analyze. In cybersecurity and payments, tokenization refers to replacing sensitive data such as credit card numbers with randomly generated substitutes called tokens that have no exploitable value. The two uses of the term are entirely unrelated and come from different fields.
AI API providers such as OpenAI charge based on the number of tokens processed per request, covering both input and output. A longer prompt with more context produces more tokens and costs more. Developers optimize cost by shortening prompts, summarizing context, and using tokenizer tools to estimate token counts before sending requests. Understanding tokenization directly affects AI application budgeting and architecture.
Conclusion
Tokenization is a fundamental step in Natural Language Processing (NLP) that influences the performance of high-level tasks such as sentiment analysis, language translation, and topic extraction. It is the process of breaking down text into smaller units, or tokens, such as words or phrases. Tokenization not only simplifies the subsequent processes in the NLP pipeline but also enables the model to understand the context and semantic relationships between words.
Despite its apparent simplicity, tokenization can handle complex linguistic nuances and cater to different languages and text structures. Its importance in NLP can’t be overstated as the quality of tokenization directly impacts the effectiveness of the overall NLP system. As advancements in AI and machine learning continue, more sophisticated tokenization techniques are expected to emerge, enhancing the performance of NLP systems further.
References
Artificial Intelligence Basics: A Non-Technical Introduction
Artificial Intelligence: A Guide for Thinking Humans
Life 3.0: Being Human in the Age of Artificial Intelligence
Artificial Intelligence: Foundations of Computational Agents