
Introduction
Computer vision allows machines to see beyond mere object detection and classification, enabling them to discern between individual objects of the same class.
Object detection and segmentation have been experiencing a surge in improvements, driven by innovative region proposal techniques, alongside the evolution of Region-based Convolutional Neural Networks (R-CNNs). The rapid evolution of these technologies has unleashed new possibilities in image analysis. From an image with multiple birds in the sky to a crowded city street, instance segmentation techniques like Mask R-CNN can identify and segment each bird, each car, and each pedestrian, opening up a world of granular detail.
In this article, we’ll trace the evolution of instance segmentation models, beginning with the foundational R-CNN series, and spotlight the power of Mask R-CNN in transforming our approach to object detection and segmentation tasks. The journey will cover the latest developments, taking you up to FastSAM, a 2023 model noted for its innovative approach and real-world applicability.
Table of contents
- Introduction
- What You Will Learn About Instance Segmentation
- Understanding the Four Pillars of Computer Vision
- What is Instance Segmentation?
- Techniques and Methodologies for Instance Segmentation
- Evolution of Instance Segmentation Models: From R-CNN to FastSAM
- Building on the Foundation of R-CNN
- Decoding Mask R-CNN: A Deep Dive into Instance Segmentation
- Instance Segmentation with PyTorch: A Hands-On Approach
- Instance Segmentation applications
- Future of Instance Segmentation
- Challenges of Instance Segmentation
- Conclusion
- References
What You Will Learn About Instance Segmentation
By the end of this article, you’ll have a comprehensive understanding of how Mask R-CNN builds on and surpasses its predecessors. You’ll grasp the architectural alterations, the significance of the new loss function, and the crucial impact of these changes on the model’s effectiveness.
We’ll also guide you through a hands-on approach to instance segmentation using PyTorch, one of the most widely used libraries for deep learning. By running a Python script with Mask R-CNN, you’ll get to apply your learnings and experience the model’s performance first-hand.
Understanding the Four Pillars of Computer Vision
To better comprehend the concept of instance segmentation, it’s crucial to grasp its placement within the broader landscape of computer vision. The four core tasks in this domain are object classification, object detection, semantic segmentation, and instance segmentation.
- Object Classification: This task involves identifying an object’s class by categorizing them from a range of input labels.
- Object Detection: This task is about recognizing the location of an object in an image and categorizing them as per predefined classes.
- Semantic Segmentation: This task involves labeling each pixel of an image according to the class of the object it represents. It does not differentiate between instances of the same class.
- Instance Segmentation: This task aims to delineate all instances of each class along with their precise location in the image.


What is Instance Segmentation?
The main difference between Instance and Semantic Image Segmentation lies in how they handle objects of the same class. Semantic Segmentation labels all instances of an object with the same class, without distinction between separate objects, while Instance Segmentation assigns unique identifiers to separate instances of the same class.
Imagine an image with several birds in the sky. Semantic Segmentation would label all birds as “bird,” making it one single instance. Instance Segmentation would distinguish each bird as a separate entity – Bird 1, Bird 2, Bird 3, etc.
Although extensive research has been conducted on instance segmentation, formidable challenges remain. These include segmenting smaller objects, handling image degradation, occlusions, inaccurate depth estimation, and dealing with aerial images.
Techniques and Methodologies for Instance Segmentation
Recently, deep learning methodologies using Convolutional Neural Networks (CNNs) have gained significant popularity in the realm of instance segmentation. Specifically, two key techniques have been used: proposal-based and proposal-free methods.
- Proposal-Based Methods: This approach heavily relies on the bounding box technique, which forms the foundation for predicting instance masks. These techniques can be time-consuming and challenging to train as they detect the object first before segmenting them.
- Proposal-Free Methods: These approaches aim to overcome the limitations of bounding box techniques. They generate a pixel-level segmentation map across the image and localize object instances. This method is simpler to train and highly efficient.
Reinforcement Learning (RL) has shown promising outcomes for solving complex tasks. Instance segmentation using RL remains an active research field presenting challenges such as the complexity of state and action space, large-scale segmentation, and occlusions.
Another noteworthy research area in computer vision is the use of Transformers, which have demonstrated remarkable success in natural language processing (NLP). Researchers have recently started exploring the potential of transformers in addressing computer vision problems, and initial results are promising.
In this article, we will concentrate mainly on exploring Mask R-CNN, a powerful model extensively used for instance segmentation tasks.
Evolution of Instance Segmentation Models: From R-CNN to FastSAM

2014 – R-CNN: Regions with CNN features (R-CNN), combines the power of selective search, used to extract potential object bounding boxes, with Convolutional Networks used to classify these regions. While an innovative first step, R-CNN’s operation was slow due to the separate handling of each region proposal, leading to the duplication of computation across overlapping regions.
2015 – Fast R-CNN: A year later came the advent of Fast R-CNN, which significantly improved upon its predecessor’s limitations. Rather than applying a CNN to each region proposal, Fast R-CNN applied the CNN just once per image, extracting feature maps from which region proposals were drawn. This not only sped up the process but also brought about a higher detection quality.
2017 – Mask R-CNN: This model extended Fast R-CNN by adding a branch for predicting an object mask in parallel with the existing branch for bounding box recognition. The beauty of Mask R-CNN lay in its simplicity, demonstrating impressive results without the need for complex alterations to the network.
2019 – Mask Scoring R-CNN & YOLACT: In 2019, Mask Scoring R-CNN improved the quality of instance segmentation by adding a mask IoU (Intersection over Union) branch to predict the quality of the predicted instance masks. This refinement greatly enhanced the accuracy of instance segmentation tasks. The same year, YOLACT (You Only Look At CoefficienTs) was introduced, offering real-time instance segmentation by breaking the complex problem into simpler, parallel sub-tasks.
2020 – TensorMask: This method proposed a geometrically inspired approach, formulating the task of instance segmentation as predicting an object-density tensor for each pixel.
2022 BoundaryFormer: It was introduced as a model that predicts polygonal boundaries for each object instance. The model uses instance mask segmentations as ground-truth supervision for computing the loss. It’s a Transformer-based architecture that matches or surpasses the Mask R-CNN method in terms of instance segmentation quality on both the COCO and Cityscapes datasets, demonstrating better transferability across datasets.
2023 FastSAM: This model innovatively divided the instance segmentation task into two parts: all-instance segmentation and prompt-guided selection. FastSAM uses a Convolutional Neural Network (CNN) detector, allowing it to process the “segment anything” task in real-time. It has been noted for its applicability to commercial applications like road obstacle identification, video instance tracking, and picture editing. FastSAM’s efficiency has been highlighted, particularly its ability to match the performance of earlier models while being significantly faster.
Building on the Foundation of R-CNN
Region-based Convolutional Neural Networks (R-CNNs) revolutionized object detection, where the goal was to not only classify an image but also to identify distinct objects within it, drawing bounding boxes around these objects. Starting from the original R-CNN model, the architecture underwent several iterations to improve performance and efficiency.
R-CNN essentially applied a search method to find a manageable number of bounding-box object proposals. These proposed regions were then run through a CNN followed by a Support Vector Machine (SVM) to classify the objects.
The region proposals were generated by an algorithm called “Selective Search,” which greedily merges superpixels based on color, texture, size, and shape compatibility. This approach had two significant limitations. First, it was computationally expensive and slow, primarily because the feature extraction step was applied to each region proposal independently. Second, the pipeline consisted of several stages, including the region proposals, CNN features extraction, and SVM classification, which was trained separately, not end-to-end.
Fast R-CNN was proposed to address these shortcomings. It introduced a method called “RoI (Region of Interest) Pooling,” which allowed the entire image to be run through a CNN just once to create a convolutional feature map. From this map, features corresponding to each region proposal were extracted and fed into a classifier. This advancement significantly improved computational efficiency.
Decoding Mask R-CNN: A Deep Dive into Instance Segmentation
Mask R-CNN is an advanced model that not only categorizes individual objects and places a bounding box around each (object detection), but it also classifies each pixel into a set category without differentiating object instances (semantic segmentation). Despite the complexity of the task, Mask R-CNN exhibits simplicity, flexibility, and speed, surpassing previous state-of-the-art instance segmentation results.
This technique extends Faster R-CNN by introducing an additional branch that predicts segmentation masks on each Region of Interest (RoI), along with the existing branch for classification and bounding box regression. The mask branch acts as a small FCN applied to each RoI, predicting a segmentation mask pixel-by-pixel. Although this may seem like a minor modification to Faster R-CNN, it critically impacts the effectiveness of the model.
One important aspect of Mask R-CNN is the addition of a new loss function called the binary cross-entropy loss, used for the mask branch. This is in addition to the existing losses: the softmax loss for class labels and smooth L1 loss for bounding box coordinates. The final loss function becomes the sum of all these individual losses.
Equations-wise, the final loss function L of the Mask R-CNN model can be represented as follows:
L = L_cls + L_box + L_mask
where L_cls is the log loss over two classes (object vs. not object), L_box is the smooth L1 loss for the bounding box regression, and L_mask is the average binary cross-entropy loss.
In essence, Mask R-CNN has three outputs for each candidate object: a class label, a bounding-box offset, and an object mask. This additional mask output is distinct from the class and box outputs and requires extraction of a much finer spatial layout of an object.
Instance Segmentation with PyTorch: A Hands-On Approach
With this Python script, we will be using the PyTorch library to apply the Mask R-CNN model for object detection and instance segmentation on our images.
PyTorch offers two variants of the Mask R-CNN model, each with optional pre-trained weights: maskrcnn_resnet50_fpn and maskrcnn_resnet50_fpn_v2. Both models utilize a ResNet-50-FPN backbone, meaning they leverage the powerful ResNet-50 model for feature extraction and a Feature Pyramid Network (FPN) for detecting objects at different scales.
The first version, maskrcnn_resnet50_fpn, adheres strictly to the architecture detailed in the original Mask R-CNN paper. The second version, maskrcnn_resnet50_fpn_v2, integrates improvements inspired by the “Benchmarking Detection Transfer Learning with Vision Transformers” paper, potentially providing enhanced performance.
Each model variant offers different trade-offs in terms of Box and Mask Mean Average Precision (MAP), model size (Params), and computational complexity (GFLOPs). For instance, the v2 model demonstrates a superior Box MAP of 47.4 and Mask MAP of 41.8, but demands more parameters and computational power, compared to its predecessor.
Python Environment Setup
First, we need to import the necessary libraries and modules. This includes numpy, for mathematical operations, torchvision for image-related functions, matplotlib for visualization, and torch for deep learning functionalities.
Establishing a new Python environment is a good practice, providing an isolated space where you can freely install, upgrade or remove packages without disrupting your other projects. Tools such as virtualenv for Python or conda environments if you are using Anaconda can be used to create these separate environments.
!pip install torch torchvision torchaudio numpy matplotlibOnce you’ve set up a new environment, it’s time to bring in PyTorch. You can install PyTorch along with its vision and audio libraries using pip, Python’s package installer. Run the following command in your Python Notebook:
import numpy as np
from pathlib import Path
from torchvision.io import read_image
from torchvision.utils import make_grid
import torchvision.transforms as transforms
from matplotlib import pyplot as plt
import torchvision.transforms.functional as TF
import torchDefining Display Function
For ease of visualization, we define a function display_images that allows us to display a list of images in a grid format.
# Function to display a list of images
def display_images(image_list):
if not isinstance(image_list, list):
image_list = [image_list]
fig, axes = plt.subplots(ncols=len(image_list), squeeze=False, figsize=(15, 15))
for i, img in enumerate(image_list):
img = img.detach()
img = TF.to_pil_image(img)
axes[0, i].imshow(np.asarray(img), cmap='gray')
axes[0, i].set(xticklabels=[], yticklabels=[], xticks=[], yticks=[])
plt.subplots_adjust(wspace=0.05)
plt.show()Reading and Preprocessing the Images
We then specify the paths for our images, read them using read_image, and resize them using transforms.resize from torch vision’s transforms module.
img_path_1 = str(Path(r'C:\Users\...')) # add path of your image here
img_path_2 = str(Path(r'C:\Users\...')) # add path of your image here
img1 = read_image(img_path_1)
img2 = read_image(img_path_2)
resize = transforms.Resize(size=(800, 600))
resized_images = [resize(img1), resize(img2)]
While performing image instance segmentation, it is essential to consider the aspect ratios of the objects to be segmented, ensuring the accuracy of the segmentation head in detecting and isolating different instances of objects. The original image is often subjected to transformations such as bilinear interpolation to maintain the continuity and smoothness of the pixel mask before being passed through the convolutional layers of the object detector.
Utilizing the Mask R-CNN Model
Next, we instantiate the Mask R-CNN model using the pretrained maskrcnn_resnet50_fpn model from torchvision’s models.detection module. We also apply the necessary transformations for our images using the model’s default weights.
from torchvision.models.detection import maskrcnn_resnet50_fpn, MaskRCNN_ResNet50_FPN_Weights
from torchvision.utils import draw_bounding_boxes, draw_segmentation_masks
model_weights = MaskRCNN_ResNet50_FPN_Weights.DEFAULT
detection_model = maskrcnn_resnet50_fpn(weights=model_weights, progress=False).to(device)
detection_model = detection_model.eval()
image_transforms = model_weights.transforms()
processed_images = [image_transforms(image).to(device) for image in image_list]Refining and Visualizing Model Outputs
Now that we’ve processed our images and set up the model, we can use the model to get our desired outputs. We also define two functions refine_model_outputs and obtain_masked_outputs to clean and process these outputs based on a defined confidence threshold. Finally, we apply the draw_segmentation_masks function to visualize the segmentation masks on our original images.
model_outputs = detection_model(processed_images) # list of dict
confidence_threshold = .7
model_outputs = refine_model_outputs(outputs=model_outputs, threshold=confidence_threshold)
model_outputs = obtain_masked_outputs(model_outputs)
visualize([
draw_segmentation_masks(image, result.get('masks'), alpha=0.9)
for idx, (image, result) in enumerate(zip(image_list, model_outputs))
])

In our first case, we set the confidence threshold to 0.7. This means that the model will only segment instances in the image if it’s 70% sure that the instance belongs to a certain class. At this level, the Mask R-CNN model returned several segmentation masks. It has successfully identified and segmented various objects in the street images, such as cars, pedestrians, and buildings. Some of the masks were overlapping, and there were instances where the model segmented objects that were not clearly discernible to the human eye. This is expected as we have set a relatively lower confidence threshold, which might lead to some false positives.
In the second case, we raised the confidence threshold to 0.85. This higher threshold implies that the model must be 85% sure of an instance’s class before segmenting it. As a result, we noticed a decrease in the number of segmentation masks. The model became more conservative in its instance identification, reducing the number of segmented objects. It focused on the most distinct and clear objects, such as large buildings and vehicles, while ignoring less obvious objects or ones that were partially hidden or overlapped by other objects. By increasing the confidence threshold, we have reduced false positives but potentially increased false negatives.
Instance Segmentation applications
Instance segmentation models like SOLOv2 enable businesses to decode customer behavior within retail environments. They facilitate the segmentation and tracking of individual customers within video footage from stores, which can yield essential insights into popular products, effective store layouts, and impactful marketing strategies. By offering a lens into customer preferences and traffic patterns, these models are becoming instrumental in optimizing sales and enhancing customer satisfaction.
Industrial sectors like manufacturing and warehouse management are reaping the benefits of automated object detection, tracking, and quality control processes. These models can help give quick and accurate segmentation capabilities that empower businesses to monitor production lines, detect defects, and track inventory, which significantly boosts productivity and slashes operational costs.
Instance segmentation models, particularly Mask RCNN, have been instrumental in revolutionizing medical imaging analysis. With the ability to process complex medical images like MRIs and CT scans, this model aids in the identification and segmentation of intricate anatomical structures. These capabilities are critical in delivering precise diagnoses and facilitating effective treatment planning. Mask R-CNN approach capabilities are finding utility in robot-assisted surgery, where they provide guidance for precision-oriented tasks and ensure patient safety.
Autonomous vehicles are becoming increasingly reliant on robust object detection and instance segmentation models, such as YOLOv8, to navigate complex and dynamic environments safely. Rather than simply detecting objects, these models help segment each object individually, aiding in comprehensive scene understanding. This granular understanding of the environment, including the detection of pedestrians, other vehicles, and road obstacles, allows for safer navigation and more accurate path planning, paving the way for truly autonomous transportation systems.
Future of Instance Segmentation
Instance segmentation, an essential technique in computer vision and artificial intelligence, has seen substantial development in recent years. This process involves identifying and delineating every individual object of interest within an image. By integrating the capabilities of semantic image segmentation, which recognizes the contents of an image, and object detection, which situates these identified items, instance segmentation creates binary masks to mark exact pixels within the boxes around objects. This level of precision even accommodates the segmentation of overlapping objects.
Advances in instance segmentation have paved the way for Panoptic Segmentation. This innovative approach merges semantic segmentation and instance segmentation into a single, consistent task. By assigning a unique label to every semantic class, including the instances of objects within an image, panoptic segmentation deepens our understanding of image content. This is particularly valuable in fields like satellite imagery analysis where the ability to identify specific objects among various aspect ratios is crucial. Generating precise segmentation with traditional algorithms, such as bilinear interpolation, can often be challenging due to the complexities of handling different scales and aspect ratios of objects.
To address these complexities, architectures like Mask R-CNN and U-Net have emerged, significantly enhancing the performance of instance segmentation tasks. The Mask R-CNN architecture introduces an additional branch for mask prediction alongside the existing branches for classification and bounding box regression. This allows the network to generate binary masks for each object instance within an image in a single, unified framework. Conversely, U-Net is a convolutional network architecture designed for fast and accurate segmentation of biomedical images. This architecture contains contracting (encoder) and expanding (decoder) blocks that first reduce the image to a compact representation and then restore it to its original size, creating a label mask of the same dimensions.
Crucial to these architectures are the loss functions employed to improve segmentation accuracy. The Mask R-CNN model utilizes a multi-task loss, a linear combination of the classification loss, box regression loss, and segmentation loss. The segmentation loss is calculated as the average binary cross-entropy loss. Meanwhile, U-Net employs either a dice coefficient loss or binary cross-entropy loss. Another challenge is handling the imbalance between background and actual detections, an issue that can be addressed using non-max suppression and other techniques.
As we continue to advance, instance segmentation is set to evolve even further, incorporating more sophisticated machine learning techniques. For example, self-driving algorithms, which require detailed detection and understanding of all objects within a scene, stand to benefit greatly from enhancements in instance segmentation methods. Upsampling algorithms for satellite imagery and biomedical image segmentation will need to adapt to manage the increasing complexity and detail of images. Given the appropriate training dataset and algorithm frameworks, the potential of instance segmentation is vast, from enhancing detection performance to improving the accuracy of object recognition in artificial intelligence applications. This progress will be a significant factor in the ongoing evolution of machine learning and computer vision technologies.
Also Read: 30 Exciting Computer Visions Applications in 2023
Challenges of Instance Segmentation
In the field of computer vision, instance segmentation is a technique that brings with it a host of challenges. A primary hurdle lies in handling pixel and integer values. Distinguishing instances of objects within an image by allocating unique pixel values to each object instance can be a demanding task, especially when binary classifications are necessary and in complex images with overlapping objects.
Managing inputs from multiple channels adds another layer of complexity. Instance segmentation algorithms are designed to process inputs from numerous channels, each representing a different feature or aspect of the image. Merging these diverse inputs into a single one while preserving critical information about the spatial location of each pixel within the image can be quite a challenge. Thus, strategizing effective methods to integrate multi-channel inputs is a significant concern in instance segmentation.
Placing multiple bounding boxes around objects, or using ‘boxes per location’, also brings its own set of challenges. Ideally, these boxes, known as anchor boxes, should outline each object instance accurately. Due to variations in object sizes, shapes, and orientations, it can be tricky to define anchor box generation parameters that suit every object. This calls for a delicate balance in adjusting these parameters. Overdoing it could lead to unnecessary computations, while being overly cautious might miss potential objects.
Instance segmentation also involves issues stemming from the architectures used, like the backbone architecture and decoder blocks. These architectures, which are pivotal in learning feature representations and recovering spatial data, involve a substantial number of trainable parameters. As these parameters increase, the risk of overfitting also escalates, making it more challenging to generalize the model to unseen data. Batch normalization used to stabilize the learning process could sometimes lead to bad target values, especially when used with small batch sizes.
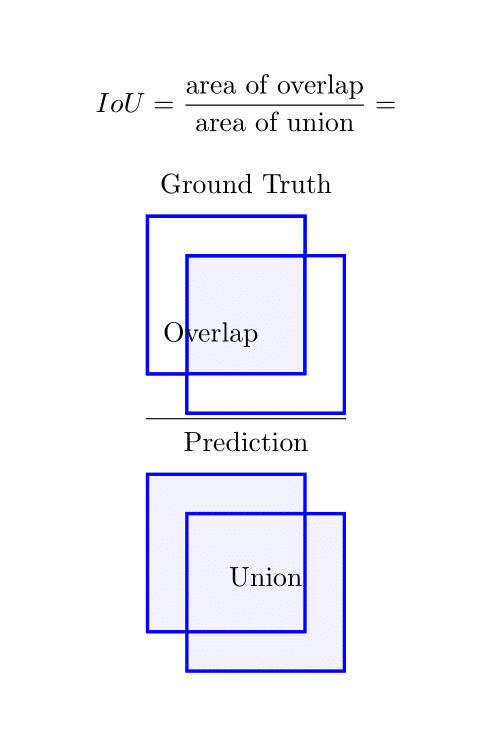
Another challenge is the calculation of the confidence score of each detected instance. This score, indicating the model’s certainty in its detection, is typically computed by multiplying the classification score of an object by the Intersection over Union (IoU) between the predicted box and the ground truth box. Deriving an accurate IoU can be tough in cases where instances of objects overlap considerably, potentially leading to lower confidence scores for some objects. Nonetheless, ongoing advancements and research continue to augment the capabilities of instance segmentation, solidifying its position as a potent tool in computer vision and AI.
Also Read: What is UNet? How Does it Relate to Deep Learning?
Conclusion
Instance segmentation as a field has seen significant advancements and innovations, with techniques like panoptic segmentation offering groundbreaking ways to understand and interpret input images. These developments have been critical in applications ranging from autonomous driving to satellite imagery, painting an increasingly dynamic and expansive picture of the impact of AI and computer vision.
Instance segmentation, enabled by Mask R-CNN, allows for a detailed understanding of images at a pixel level. This shift from bounding-box level object detection to pixel-wise instance segmentation opens up myriad applications, including self-driving cars, medical imaging, and video surveillance.
The utilization of segmentation datasets has been pivotal in training these models. These datasets provide diverse examples of images, promoting a more comprehensive understanding and thereby improving the overall performance of the model. Despite the success, it is crucial to carefully apply techniques such as batch normalization to ensure a stable learning process and avoid potential pitfalls like overfitting.
The role of ground truth boxes in evaluating the performance of these models is vital. Comparing the predicted instances against the ground truth enables us to gauge the accuracy of our model in identifying and differentiating objects within an image, further driving improvements in these art models.
Despite the evolution of object detection and segmentation models, they still face challenges such as dealing with a large number of classes, detecting small objects, and handling occlusion. Yet, with the consistent advancements in deep learning and computational capabilities, we can expect further improvements in the years to come.
Ultimately, as we continue to refine and expand our image segmentation methods, the potential applications will only grow. From detecting objects for autonomous vehicles to analyzing satellite imagery for environmental studies, instance segmentation holds the key to unlocking new avenues and innovations. Despite its challenges, its future is bright and holds exciting potential for further breakthroughs.

References
Akash, and Laseena. Pixel Level Instance Segmentation Using Single Shot Detectors and Semantic Segmentation Networks. 2019.
Ferrari, Vittorio, et al. Computer Vision – ECCV 2018: 15th European Conference, Munich, Germany, September 8-14, 2018, Proceedings, Part X. Springer, 2018.
Pham, Van Vung. Hands-On Computer Vision with Detectron2: Develop Object Detection and Segmentation Models with a Code and Visualization Approach. Packt Publishing Ltd, 2023.
Vedaldi, Andrea, et al. Computer Vision – ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part I. Springer Nature, 2020.