
Introduction:
One of the most difficult things for humans is to program or develop a learning process for computers to think creatively or help them understand style norms. Human or real, or contemporary artists have been generating art for centuries with different painting styles and human intelligence. There is no doubt that computers are extremely good at doing exactly what we ask them to do, and they are able to accomplish the task quickly, but creativity is an abstract concept, and teaching it to machines has been a challenging machine learning task. To overcome this challenge, a group of students from Rutgers University in a research paper introduced the concept of CAN’s (Creative Adversarial Networks).
CAN’s that run on deep learning, neural networks, and artificial intelligence enables the machines to think creatively, which means this is not a cheap imitation of any artwork that already exists.
Let us learn and understand what CAN’s are and how they work.
Table of contents
A CAN is a GAN with a Creative Process
In order to understand CANs, you first need to understand Generative Adversarial Networks (GANs), which were created by Ian Goodfellow and his coworkers a few years ago. A good understanding of GANs will allow you to fully understand CANs.
A Generic Adversarial Network (GAN) is a type of generative model that observes a number of sample distributions and generates more samples of the same distribution. It is comprised of two main components, namely the generator and the discriminator. In the generator model, information (Example Images) is generated based on the data set that it is fed from, while the discriminator model determines whether or not the image is real or fake.
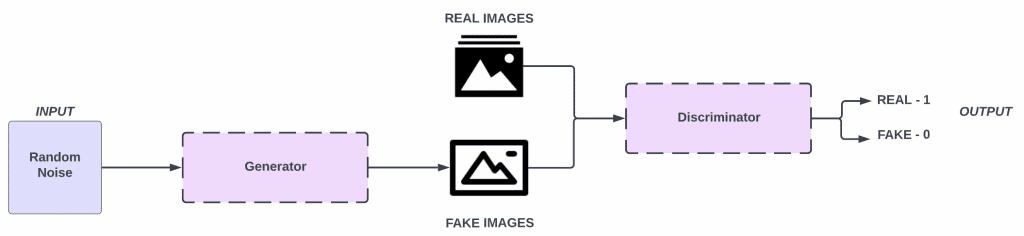
When fed fake images generated by the generator and real images, the discriminator can classify each image as real or fake based on its ability to recognize patterns. It is also helpful for the generator to get feedback as to which images are tricking the discriminator the best and how they can make their strategy even better in order to trick the discriminator even more effectively.
When a discriminator and a generator are competing to be the best at what they do, both become better at what they do, and when the generator has been properly trained, the results that the generator produces can be surprisingly realistic when the GANs have been properly trained.
CAN’s follow the same architecture except for one small change in the GAN’s architecture.
It is still necessary for discriminators to learn how to classify images as being real or fake, but go an extra mile so they also learn how to classify them according to different styles (e.g. cubism, abstract, renaissance, realism, etc.).
Also Read: Introduction to Generative Adversarial Networks (GANs)
How do Creative Adversarial Network’s work?
It should be noted that in the Creative Adversarial Network (CAN) the generator receives two signals from the discriminator and treats them as two opposing forces in order to accomplish three points:
Generate Novel Works.
As per the Wundt curve, the work should not be far-fetched so that it activates the aversion system and moves it into the negative hedonic range.
The generated work should increase the stylistic ambiguity.
There are two adversarial networks that are used in the proposed network of CAN’s, a discriminator and a generator, This is similar to the Generative Adversary Networks (GAN) architecture but with a twist. The discriminator has access to a large set of art associated with style labels (Renaissance, Baroque, Impressionism, Expressionism, etc.) and uses them to learn to discriminate between styles. The generator does not have access to any art. In contrast to GAN, CAN’s generate art based on random input, but receives two signals from the discriminator for each output: the first signal specifies whether the output is art or not.
Traditionally, this signal allows the generator to change its weights to generate images that are more likely to deceive the discriminator as to whether they are coming from the same distribution of images, as in traditional GANs. In our case, since the discriminator is trained on art, this signal will indicate whether the discriminator thinks that the generated art is from the same distribution as the actual art it knows about. Thus, it can be said that this signal indicates to the discriminator whether it considers the image presented to it to be “art” or not.
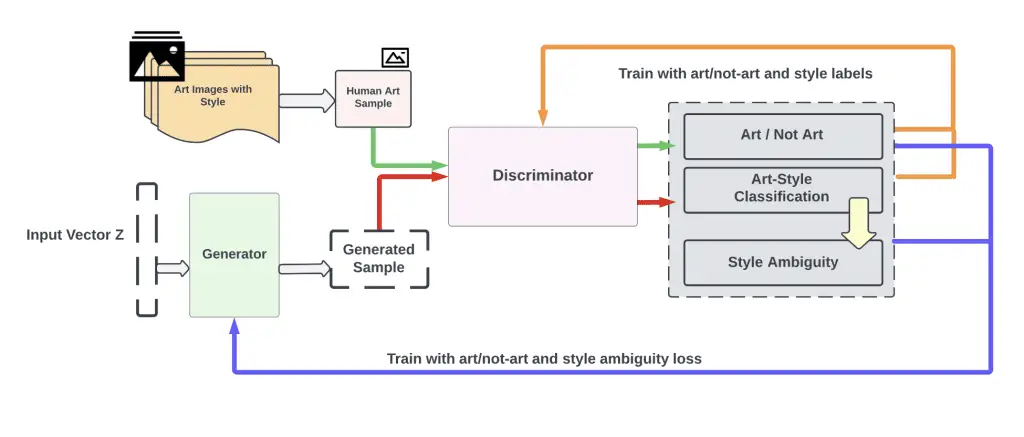
There are two signals that the generator receives. The first signal is about if the discriminator is capable of identifying whether or not the generated art or digitized images can be classified into established styles. The second signal that the generator receives shows how well it can classify the generated art into the established styles.
If the generator generates images that the discriminator thinks are art and also can easily classify them into one of the established styles, it will fool discriminator into believing that it generated actual art that fits within the existing styles of that category. The creative generator will, on one hand, create art that is likely to confuse the discriminator. It attempts to fool the discriminator into thinking it is “art” on the one hand.
First, the generator is driven to generate works that the discriminator accepts as “art,” but if it achieves success within established styles, it will also be able to classify its work. Due to the fact that the second signal pushes the generator to generate style-ambiguous works, it will penalize the generator heavily for doing that. As a result, these two signals should together push the generator to explore creative spaces near the distribution of art (in order to maximize the first objective), while at the same time maximizing the ambiguity of the generated art with respect to how it fits within the standard art style genre.
Why do Creative Adversarial Network’s Work?
To understand why added classification of images into styles of art is able to enable the generator to think creatively, it is important to come up with a concrete definition, process, and structure of creativity that a machine can mimic. Something similar to an advance version of decision trees.
As the researchers at Rutgers described in their paper, viewers are more likely to perceive creativity when the artwork is both unique and not too out there.
Using this method, the discriminator is rewarded for producing images that can’t be easily classified into a particular artistic style by the generator, thus forcing the generator to produce images that are truly unique (creative). It is also important to point out that the generator still needs to fool the discriminator into believing that the images are real, so it cannot generate images that are too out of the norm and that are obviously different.
As a result of this architecture, CANs are able to simulate what we see as creativity in art based on this definition
It generates art by optimizing a criterion that maximizes stylistic ambiguity while remaining within the distribution of art images from the 15th century to the 21st century. Human subject experiments confirmed that the generated art was frequently confused with human art, and that the generated art was sometimes rated higher on high-level scales than human art.
Also Read: Redefining Art with Generative AI
What creative characteristics do CAN’s have?
Three criteria that a creative system should have:
Imagination
Skill
Assessment capabilities.
Since the interaction between two signals that derive the generation process is designed to force the system to explore creative space, CAN’s can produce novel artifacts because the system is forced to deviate from established styles but remain within the boundaries of art to be recognized.
The interaction also provides the system with an opportunity to self-evaluate the products it produces. According to the human subject experiments, it was not only found that subjects believed that these artifacts were created by artists, but that they also rated these artifacts higher on some scales than human art as well.
Creative Adversarial Network’s possess a number of key characteristics, among which is that it learns about the history of art during the process of creating art. Despite this, it does not have a semantic understanding of art behind the concept of style. It has no understanding of subject matter, nor does it possess any explicit understanding of elements or principles.
As such, the system is capable of continuously learning from new art as well as concepts of styles. The system has the ability to adapt its generation based on what it learns. This is because it is merely exposed to art and concepts of styles. Despite the fact that the CAN art is ranked higher than the Art Basel samples in various aspects, we leave open the question of how to interpret the users’ responses.
Conclusion
Creative Adversarial Networks (CANs) represent a breakthrough in the field of AI-generated art, marking a significant step forward in the ability of AI to not just mimic, but also generate original creative outputs. By leveraging the adversarial process, CANs go beyond mere replication of existing styles, to generate novel and diverse artistic creations that deviate from known art distributions, yet remain thematically coherent.
The key feature of CANs is the disentanglement of the content and style of an image, allowing the AI to generate novel artistic styles while maintaining a certain thematic coherence. This advancement opens up exciting possibilities, potentially sparking a paradigm shift in the creative world. The interplay between AI and human creativity offered by CANs could shape the future of art, providing artists with a powerful tool to push the boundaries of their creativity. The evolution of AI in art raises critical questions about creativity, originality, and the role of human artists, leading us into new uncharted territories of exploration and discovery in the intersection of technology and art.
References
Reas, Casey. Casey Reas: Making Pictures with Generative Adversarial Networks. 2019.
Sautoy, Marcus Du. The Creativity Code: Art and Innovation in the Age of AI. Harvard University Press, 2020.
Ziska, Fields. Multidisciplinary Approaches in AI, Creativity, Innovation, and Green Collaboration. IGI Global, 2023.