Introduction to Generative Adversarial Networks (GANs)
In recent years, generational adversarial networks (GAN) have received considerable attention as a result of the pioneering work by Goodfellow et al. published in 2014. The attention that has been given to GANs has resulted in an explosion of new ideas, techniques, and applications that are being developed. For a better understanding of GANs, we need to understand the mathematical foundation of them.
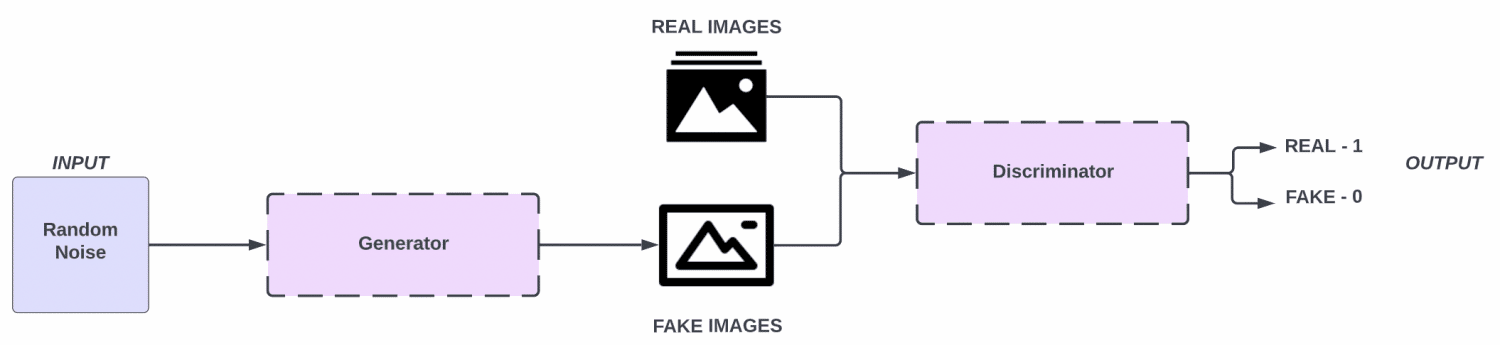
Generative Adversarial Networks (GANs) are a type of generative models, which observe many sample distributions and generate more samples of the same distribution. There are two major components of GAN architecture, the generator and discriminator. The role of the generator is to generate information (Example Images) from the data set that its fed information from and discriminator’s role is to differentiate fake from real images.
Table of contents
- Introduction to Generative Adversarial Networks (GANs)
- Understanding the Basics of Generative Adversarial Networks
- The GAN architecture
- Training GANs
- Challenges in Training GANs: Mode Collapse and Instability
- Evaluation metrics
- GAN variants
- Application of GAN’s
- Other GAN applications
- Future Perspectives: The Potential and Limitations of GANs
- Conclusion
- References
Understanding the Basics of Generative Adversarial Networks
Generative Adversarial Networks (GANs) are a class of artificial intelligence algorithms used in unsupervised machine learning, which were introduced by Ian Goodfellow and his colleagues in 2014. GANs are composed of two parts: a Generator and a Discriminator. Both components are neural networks that contest against each other in a zero-sum game, hence the term ‘adversarial’. The core objective of GANs is to generate new data from the same statistics as the training set.
The Generator component of a GAN works to create data. Its role can be thought of as a counterfeiter, fabricating fake data that appear as close as possible to the real data. The Generator doesn’t have access to the actual data distribution but learns it through feedback from the Discriminator. The Generator begins the data generation process from a random point in latent space using a vector of random numbers as input, which is then up-sampled to generate new data.
On the other hand, the Discriminator is like a detective, attempting to distinguish the real data from the fake data produced by the Generator. It is trained on both real data from the dataset and the fake data created by the Generator. The Discriminator is essentially a binary classifier that assigns a probability to each incoming sample of being real or fake. Through this adversarial process, the Generator learns to create data that the Discriminator can no longer distinguish from real data, leading to the production of increasingly accurate synthetic data.
The GAN architecture
In a basic GAN architecture there are two networks that exist: the generator network and the discriminator network. A GAN gets its name because it consists of two networks that are trained simultaneously and competing with each other, just as if they were playing in a zero-sum game such as chess.
In theory, the generator model can create an image from scratch. Basically, the purpose of the generator is to produce images that appear so real that the discriminator is fooled. As a rule of thumb, the input for the simplest GAN architecture for image synthesis is typically random noise, and its output is a generated image.
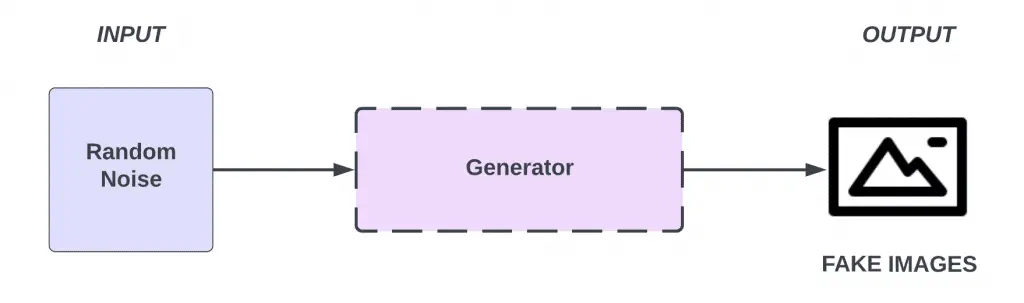
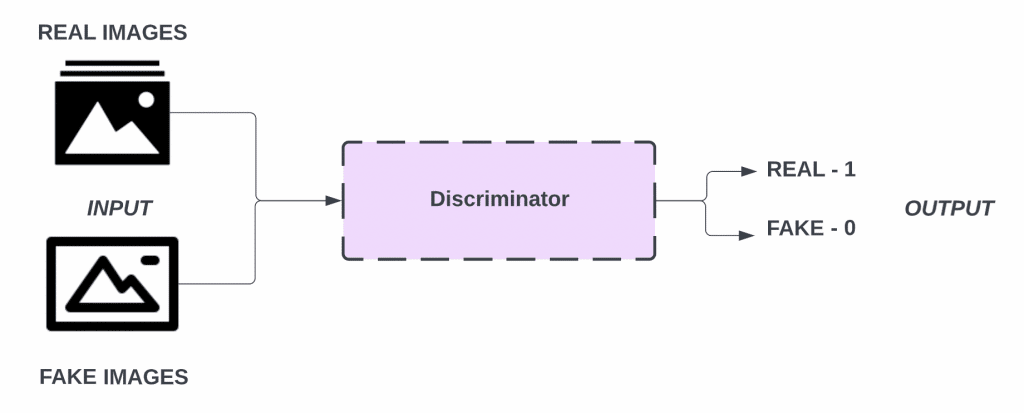
The discriminator is just a binary image classifier which you should be familiar with from working with binary images. The job of the discriminator is to determine whether an image is real or fake.
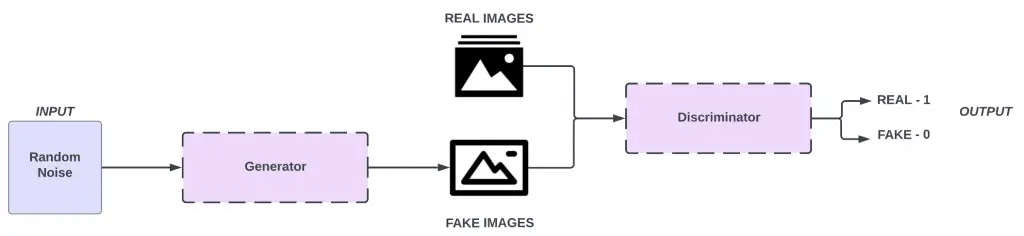
Let’s put it all together and see what a basic GAN architecture looks like: the generator makes fake images; the real images (training dataset) and the fake images are fed into the discriminator individually in separate batches. The discriminator then analyzes the image and tells whether it is real or fake.
Training GANs
The training process of Generative Adversarial Networks (GANs) is unique in that it involves a competition, or ‘game’, between two components: the Generator and the Discriminator. The training process is iterative, often likened to a two-player minimax game, where one player tries to maximize the outcome (the Generator), and the other tries to minimize it (the Discriminator).
In the first step, the Generator creates a batch of synthetic data. This generated data is then mixed with an equivalent amount of real data. The Discriminator takes this combined data as input and tries to distinguish between the real and the fake data. The Discriminator is trained using backpropagation, where the error is calculated based on its ability to correctly classify the data. During this phase, the weights of the Generator are frozen, and the Discriminator learns to get better at distinguishing real data from fake.
Next, the Generator’s turn comes to improve. The Generator creates another batch of fake data and passes it to the Discriminator. However, this time, the Discriminator’s weights are held constant, and the error is propagated back through the Generator. The Generator’s weights are then updated to produce data that the Discriminator will have a harder time distinguishing from real data. The process continues iteratively until the Discriminator cannot differentiate between real and fake data, or until a specified number of iterations have been completed. This competitive interplay leads to the Generator learning to generate data that closely matches the real data distribution.
The Min-Max strategy: G vs. D
Deep learning algorithms (like image classification) are based on optimization: finding the lowest value of the cost function. The GANs are unique because each of the two networks, the generator and discriminator, has its own cost and has opposite objectives:
- The generator tries to trick the discriminator into believing that the fake images are real
- The discriminator tries to classify real and fake images accurately.
This adversarial dynamic during training can be illustrated using the Minimax Math Function.

The generator and discriminator both improve with time as the training proceeds. During the course of training, the generator gets better and better at generating images that resemble the training data, whereas the discriminator gets better and better at telling the real from the fake.
Training GANs is to find an equilibrium in the game when:
- Data from the generator looks very similar to the data from the training set.
- A discriminator can no longer distinguish between fake images and real ones.
Also Read: AI Art Generator
The generator vs. discriminator
GANs training is similar to that process. A generator might be viewed as an artist, and a discriminator might be viewed as a critic. The generator does not have any access or visibility at all to the masterpiece it is trying to copy. However, it relies solely on the discriminator’s feedback to improve the images that it generates.
Challenges in Training GANs: Mode Collapse and Instability
Training Generative Adversarial Networks (GANs) can be fraught with difficulties and pitfalls, two of which include mode collapse and instability. Mode collapse occurs when the Generator starts producing the same output (or minor variations of it) over and over again, regardless of the input noise vector. This scenario is an issue because it means that the GAN is not capturing the full complexity of the data distribution. It’s as if the Generator has found a loophole that can fool the Discriminator and exploit it, rather than learning to generate a variety of realistic data.
The issue of instability in GANs training stems from the conflicting goals of the Generator and Discriminator. Because the Generator is trying to fool the Discriminator while the Discriminator is simultaneously trying to get better at identifying the Generator’s tricks, this can result in an unstable dynamic where the network fails to converge, or worse, diverges. This instability can manifest in the form of wild oscillations in loss during training, or the generation of nonsensical outputs.
Several strategies and modified architectures have been proposed to combat these issues. For mode collapse, methods such as minibatch discrimination, unrolled GANs, and Wasserstein GANs have been used to encourage the Generator to produce a variety of outputs. For instability, techniques like gradient penalty, spectral normalization, and careful hyperparameter tuning have been employed. Despite these challenges, when GANs are trained successfully, they demonstrate an incredible capacity for generating highly realistic data, making them a powerful tool in the AI toolkit.
Evaluation metrics
In order to build a good GAN model, there are two key factors: good quality – images should not be blurry and should resemble the training image; and diversity – the images should be generated in such a way that approximates the distribution of the training dataset.
To evaluate the GAN model, you can visually inspect the generated images during training or by inference with the generator model.
There are two popular evaluation metrics for GANs:
- Inception Score, which tries to capture the quality as well as the diversity of the generated images.
- Frechet Inception Distance that compares real vs. fake images and does not just evaluate the generated images in isolation.
GAN variants
The original GANs paper by Goodfellow et al. in 2014 gave rise to many variants of GANs. A GANs architecture tends to build upon another, either to solve a particular training problem or to create a better image or a finer control over the GANs.
Listed here are a few of these variants presenting breakthroughs that provided the foundations for future GAN advances. The following list does not purport to be a complete list of all the GAN variants.
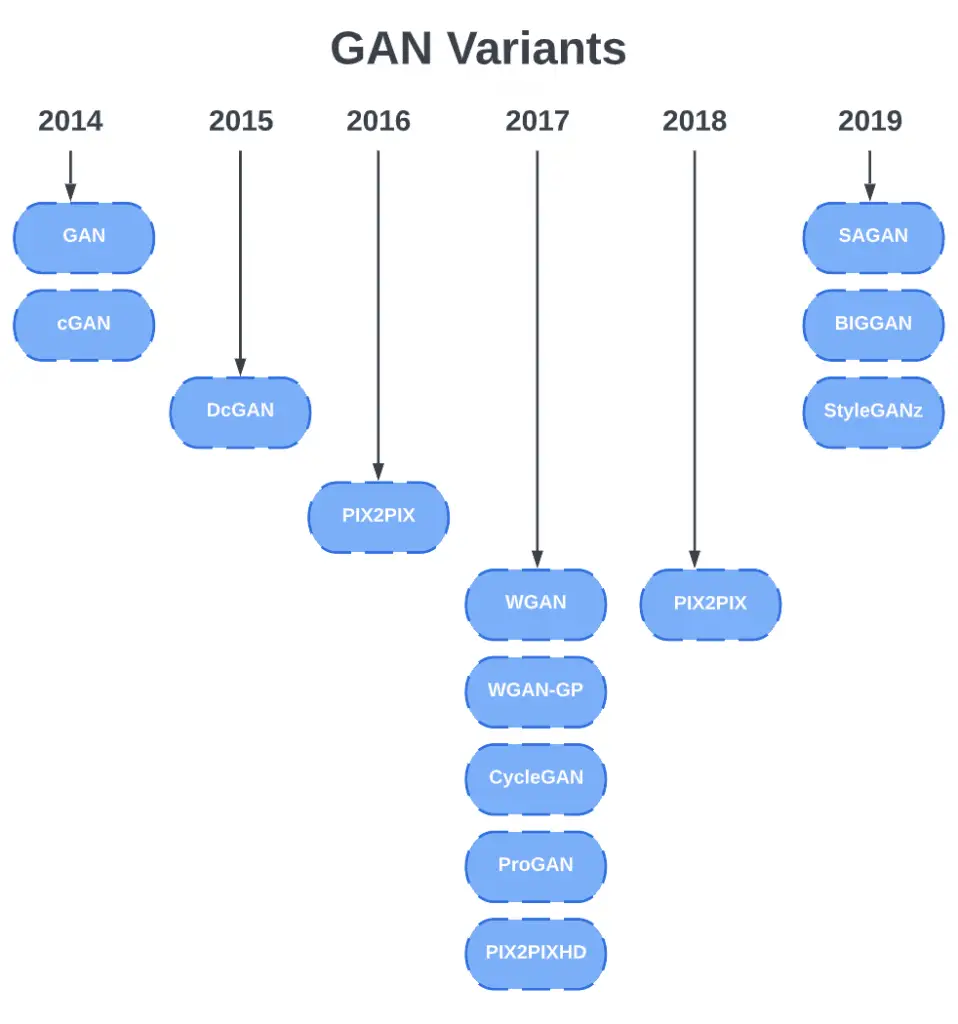
The Wasserstein GAN (WGAN) and the Wasserstein GAN-GP were designed to solve problems related to GAN training, such as mode collapse, where the generator repeats the same images or a small subset of them repeatedly. For training stability, WGAN-GP uses gradient penalty instead of weight clipping.
Pix2PixHD (High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs) disentangles the effects of multiple inputs on the resultant image, as demonstrated in the paper example: control colour, texture, and shape of the generated image for garment design. Aside from this, it can also generate high-resolution 2K images that are realistic.
DCGAN (Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks) was the first GAN proposal using Convolutional Neural Network (CNN) in its network architecture. Most of the GAN variations today are somewhat based on DCGAN. Thus, DCGAN is most likely your first GAN tutorial, the “Hello-World” of learning GANs.
cGAN (Conditional Generative Adversarial Nets) first introduced the concept of generating images based on a condition, which could be an image class label, image, or text, as in more complex GANs. Pix2Pix and CycleGAN are both conditional GANs, using images as conditions for image-to-image translation.
SAGAN (Self-Attention Generative Adversarial Networks) improves image synthesis quality: generating details using cues from all feature locations by applying the self-attention module (a concept from the NLP models) to CNNs. Google DeepMind scaled up SAGAN to make BigGAN.
BigGAN (Large Scale GAN Training for High Fidelity Natural Image Synthesis) can create high-resolution and high-fidelity images.
ProGAN (Progressive Growing of GANs for Improved Quality, Stability, and Variation) grows the network progressively.
StyleGAN (A Style-Based Generator Architecture for Generative Adversarial Networks), introduced by NVIDIA Research, uses the progress growing ProGAN plus image style transfer with adaptive instance normalization (AdaIN) and was able to have control over the style of generated images.
StyleGAN2 (Analyzing and Improving the Image Quality of StyleGAN) improves upon the original StyleGAN by making several improvements in areas such as normalization, progressively growing and regularization techniques, etc.
ProGAN, StyleGAN, and StyleGAN2, are all capable of creating high resolution images.
Application of GAN’s
Image synthesis
The creation of images through image synthesis can be fun and can also have practical applications, such as providing image augmentation for machine learning (ML) training or to create artwork or design resources.
An artificial neural network (GAN) can be used to generate images that have, so far, never existed, and this is perhaps what GANs are best known for. They can generate unseen images and artwork of cats, new faces, and many more.
They can generate entirely new images that resemble real ones, modify existing images by adding or removing elements, or even convert an image from one domain to another, as in the case of CycleGANs. In image synthesis, GANs have been used to generate high-quality, realistic images of faces, objects, and scenes. The utility of GANs in image manipulation is vast, ranging from enhancing image resolution (super-resolution) to altering facial attributes in images, such as aging or de-aging a face.
Also Read: Artificial Intelligence and Architecture
Image-to-image translation
In computer vision, image-to-image translation refers to the process of translating an input image into another domain (e.g., color or style) while maintaining the original image content. In terms of the use of GANs in art and design, this may be one of the most important tasks.
Pix2Pix (Image-to-Image Translation with Conditional Adversarial Networks) is a conditional GAN that was perhaps the most famous image-to-image translation GAN. One drawback of Pix2Pix is that it requires paired training image datasets.
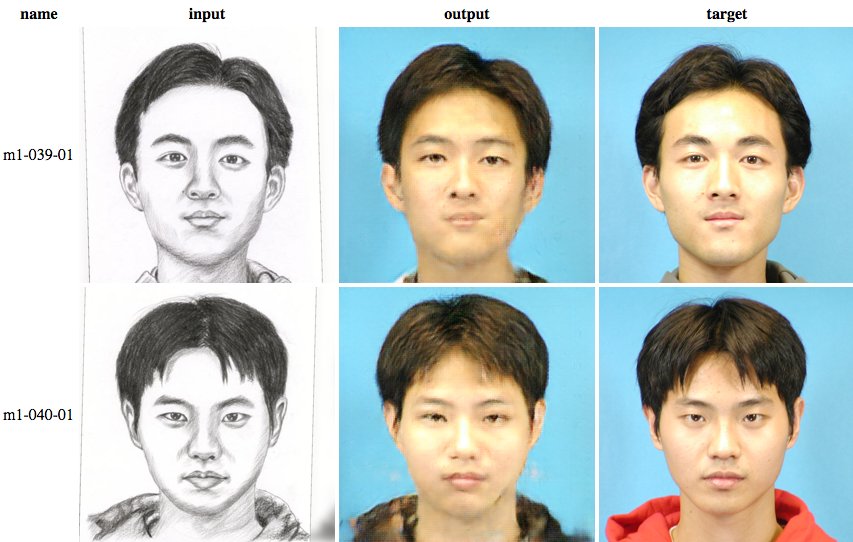
Source: Twitter.com
CycleGAN uses Pix2Pix and only needs unpaired images, which are easier to obtain in the real world. This program can change an image of an apple into an orange, or a sunset into a sunrise, or a horse into a zebra, for example. I agree that these might not be real-world use cases at all, but there have been so many other image-to-image GANs developed since then for art and design, that they may not be suitable for this purpose.

Source: CycleGAN converts a horse to a zebra (image source: CycleGAN Project Page).
It is now possible to translate your selfie into comics, paintings, cartoons, or any other style you can imagine. White-box CartoonGAN can be used to turn our pictures into a cartoonized version.

Colorization can be applied to both black and white and color photos, as well as artworks and design assets. Generally, when we are making artwork or designing UI/UX, we start by drawing outlines or contours and then coloring them after that. The automated colorization could help provide artists and designers with inspiration.
Text-to-Image
There have been a lot of examples of GANs translating images to images so far. There is also the possibility of using words as the condition to generate images, which is much more flexible and intuitive than using class labels as the condition.
Here are some examples: StyleCLIP and Taming Transformers for High-Resolution Image Synthesis.
Beyond images
GANs can be used for not only images but also music and video. For example, GANSynth from the Magenta project can make music.
Climate change
Here is an example of how GANs can be used for climate change. Earth Intelligent Engine, an FDL (Frontier Development Lab) 2020 project, uses Pix2PixHD to simulate what an area would look like after flooding.
Also Read: Tools to Make AI Generated Art
Other GAN applications
Here are a few other GAN applications:
- Image inpainting: replace the missing portion of the image.
- Image uncropping or extension: this could be useful in simulating camera parameters in virtual reality.
- Super-resolution (SRGAN & ESRGAN): enhance an image from lower-resolution to high resolution. This could be very helpful in photo editing or medical image enhancements.
It has been demonstrated in papers as well as research laboratories. As well as in open source projects. In the last few years, we are starting to see real-world commercial applications using GANs. It is common for designers to use icons8 assets when designing. As GANs advance there may be more use for them in the real world, to fight climate change, to analyze historical images that are lost… etc.
Future Perspectives: The Potential and Limitations of GANs
Looking towards the future, the potential applications of GANs are extensive, spanning fields from art and entertainment to medicine and security. However, despite their promising potential, GANs also present several limitations. The adversarial training process is difficult to optimize, and can be unstable, leading to issues like mode collapse. The black-box nature of GANs can lead to unpredictable outputs and makes them difficult to control precisely. On the brighter side, research continues to evolve in this space, addressing these limitations and expanding the potential applications of GANs. As our understanding of GANs deepens, they will undoubtedly become an even more integral part of the artificial intelligence ecosystem.
Conclusion
Generative Adversarial Networks (GANs) have revolutionized the field of machine learning by providing an innovative framework to generate new data that matches the distribution of the training set. The foundational concept behind GANs, that of pitting two neural networks – a generator and a discriminator – against each other in a zero-sum game, has enabled unprecedented advancements in fields such as image synthesis, semantic image editing, and style transfer. It’s a testament to the profound impact of GANs that their architecture and techniques continue to be fine-tuned and improved upon, driving innovation and progress in the broader realm of artificial intelligence.
A distinguishing feature of GANs is their ability to learn and generate complex, high-dimensional distributions. Through the interplay of the generator and discriminator, GANs continually refine their performance, making the generation of synthetic data more realistic and indistinguishable from real-world data. This has unlocked significant potential in industries such as entertainment, healthcare, and e-commerce, where GANs are now commonly used for image generation, anomaly detection, data augmentation, and other tasks that require the creation of synthetic yet realistic data.
GANs have been instrumental in overcoming some of the key challenges faced in deep learning, particularly the issue of lacking ample labeled data. By generating synthetic data, GANs can augment existing datasets, thereby assisting in more effective model training and validation. The use of GANs extends beyond simple data generation; they can also be used in semi-supervised learning scenarios, as well as for tasks like image-to-image translation and super-resolution, among others.
The advent of GANs has opened up a plethora of possibilities in the realm of artificial intelligence and machine learning. The powerful paradigm of adversarial training they introduced has made it possible to generate complex, high-quality data in a variety of formats. Despite the challenges that remain, such as mode collapse and training instability, the potential and versatility of GANs continue to drive research and development. As we refine these models and develop more stable and scalable versions, the impact of GANs is set to become even more significant, profoundly influencing our ability to create, innovate, and understand complex data distributions.

References
Brownlee, Jason. Generative Adversarial Networks with Python: Deep Learning Generative Models for Image Synthesis and Image Translation. Machine Learning Mastery, 2019.
Razavi-Far, Roozbeh, et al. Generative Adversarial Learning: Architectures and Applications. Springer Nature, 2022.
Valle, Rafael. Hands-On Generative Adversarial Networks with Keras: Your Guide to Implementing next-Generation Generative Adversarial Networks. Packt Publishing Ltd, 2019.