
Introduction:
The XGBoost algorithm is a scalable, distributed gradient-boosted decision tree (GBDT) machine learning library. What it stands for is Extreme Gradient Boosting. There are many advantages to using this machine learning library, such as parallel tree-boosting and it is the leading machine learning library for regression, classification, and ranking.
Table of contents
- Introduction:
- What is XGBoost
- XGBoost Features
- Understanding the Fundamentals of XGBoost
- Key Features of XGBoost: Gradient Boosting and Regularization
- XGBoost’s Flexibility: Multiple Objective Functions and Customization Options
- Handling Missing Values and Outliers with XGBoost
- Tree Pruning and Parallel Processing in XGBoost
- Built-in Cross-Validation: Optimizing Predictive Accuracy in XGBoost
- Flexibility in XGBoost: Custom Optimization Objectives and Evaluation Criteria
- Distributed Computing with XGBoost: Managing Large Datasets
- Out-of-core Computing in XGBoost: Utilizing Secondary Storage Systems
- Continued Training in XGBoost: Incremental Learning and Model Improvement
- Heterogeneous Data Handling in XGBoost: Navigating Numerical and Categorical Data
- XGBoost Algorithm Features
- Why Use XGBoost?
- What Algorithm Does XGBoost Use?
- How XGBoost Runs Better With GPUs
- Code Example of XGBoost
- Conclusion
- References
What is XGBoost
A decision tree based ensemble Machine Learning algorithm, XGBoost uses a gradient boosting framework in order to accomplish ensemble Machine Learning. The XGBoost model makes use of advanced regularization techniques (L1 & L2), which improves the model’s generalization abilities. At its core XGBoost is performance driven which makes it popular for use in machine learning.
For a complete understanding of XGBoost, one must first grasp the machine learning concepts and algorithms that XGBoost relies upon: supervised machine learning, decision trees, ensemble learning, and gradient boosting.
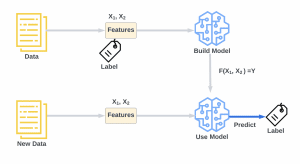
The supervised machine learning concept is where algorithms are used to create a machine learning model for finding patterns in a dataset with labels and features. The machine learning model is then used to predict labels on a new dataset’s features using the trained model.
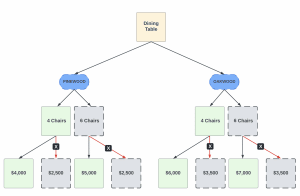
In decision trees, the likelihood of a correct decision is determined by evaluating a tree of if-then-else true/false feature questions, and estimating the minimum number of queries needed to calculate the likelihood of a correct decision. There are two types of decision trees: classification trees for predicting a category, and regression trees for predicting a numeric value. The example below represents the decision tree to determine the value of the dining table set.
Graduate Boosting Decision Trees (GBDT) are an ensemble learning algorithm for decision trees similar to the random forest, which can be used for both classification and regression. The idea of ensemble learning is to combine multiple learning algorithms in order to produce a better model.
The random forest algorithm and the GBDT algorithm build a model that consists of multiple decision trees. There are some differences in the way the decision trees are combined, and in how they are constructed.
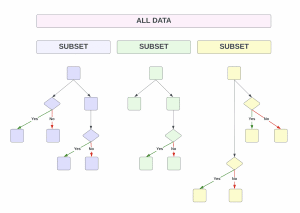
With random forest, you can build full decision trees in parallel from random bootstrap samples of the data set using a technique called ‘bagging.’ Ultimately, all prediction trees are averaged together.
The term “gradient boosting” derives from the fact that it is meant to improve or value-add a weak model by combining it with a number of other weak models in order to create a “collectively strong” one. An extension of boosting known as gradient boosting is a process that consists of additively generating weak models via a gradient descent algorithm connected to an objective function. In an effort to minimize errors, gradient boosting sets out targets for the next model to achieve. The targeted outcome in each case is determined by the gradient of the error (hence the name gradient boosting) in relation to the prediction.
An ensemble of shallow decision trees can be trained iteratively with GBDTs, with each iteration using the residual error of the previous model in order to fit the next model. All tree predictions are weighted together to make a final prediction that is the weighted sum of all tree predictions. A random forest implementation with “bagging” minimizes variance and overfitting, while a GBDT implementation with “boosting” minimizes bias and underfitting.
There are many reasons to use XGBoost. It is a scalable and highly accurate implementation of gradient boosting that pushes the limits of computing power for boosting tree algorithms, and is largely intended to energizing the performance of machine learning models. With XGBoost, trees are created in parallel, rather than sequentially as they are with GBDT. In this approach, the gradient values are scanned across every possible split in the training set, and the partial sums are evaluated to see how good the splits are at every possible split.
Also Read: How to Use Linear Regression in Machine Learning.
XGBoost Features
One of the most important features of XGBoost is that at its core it is all about speed and performance. But it does offer a number of advanced features as well.
Understanding the Fundamentals of XGBoost
XGBoost, short for eXtreme Gradient Boosting, is a high-performance machine learning algorithm based on the gradient boosting framework. It’s specifically designed to maximize computational speed and model performance, thereby making it an excellent choice for many supervised learning problems. In its core, it builds an ensemble of weak prediction models, typically decision trees, in a stage-wise fashion. By successively adding new models, XGBoost aims to correct the mistakes of the existing ensemble, which results in highly accurate predictions.
This gradient boosting framework follows a decision tree-based model, where new models are created to predict the residuals or errors of prior models and then added together to make the final prediction. What sets XGBoost apart is its ability to calculate the second-order gradient, i.e., the derivative of the loss function, at each step. This makes the algorithm much more efficient and enables it to determine the optimal split points and optimal combinations of trees at each iteration.
Another fundamental aspect of XGBoost is its regularized learning objective that helps prevent overfitting. Overfitting is a common issue in machine learning where a model learns the training data too well and performs poorly on unseen data. XGBoost incorporates a regularization term in its objective function that controls the model’s complexity, penalizing complex models and thus, effectively combating overfitting. This combination of gradient boosting with regularization delivers a predictive model that is both accurate and robust, making XGBoost a leading tool in machine learning competitions and practical applications.
Key Features of XGBoost: Gradient Boosting and Regularization
The gradient boosting capability of XGBoost is one of its most vital features, making it a powerful tool for a wide range of regression and classification tasks. Gradient boosting is an ensemble technique that creates a strong predictive model by combining the predictions of multiple weak models, usually decision trees. Each tree in the ensemble attempts to correct the mistakes made by the previous one, making the overall model more accurate with each addition. XGBoost applies this principle but introduces a level of optimization that standard Gradient Boosting Machines (GBM) don’t possess. The model calculates second-order gradients, essentially a measure of the curvature of the loss function, which makes learning more accurate and faster.
XGBoost also introduces regularization as a key component of its framework. Regularization is a technique used in machine learning to prevent overfitting by adding a penalty term to the loss function, which increases as the complexity of the model increases. The more complex the model (i.e., the more it attempts to fit the noise in the training data), the larger the penalty. XGBoost’s regularization term includes both the number of leaves in the tree (L1 regularization) and the sum of the leaf scores (L2 regularization). This way, XGBoost balances the fit to data and complexity of the model, creating a highly accurate, robust model that generalizes well to unseen data.
Unlike traditional GBMs, XGBoost incorporates a unique approach to handle missing values, allowing the model to learn the optimal locations for missing values during the training process. It does this by adding a default direction in each tree node for the instances with missing values, leading to more robust and accurate models. This combination of gradient boosting and regularization, along with the advanced handling of missing values, contributes to the superior performance of XGBoost, making it a go-to algorithm for many data scientists in diverse applications.
XGBoost’s Flexibility: Multiple Objective Functions and Customization Options
XGBoost offers substantial flexibility by supporting multiple objective functions, also known as loss functions, which makes it applicable to a wide range of predictive modeling problems. In addition to common functions for regression (linear regression, logistic regression) and classification (binary classification, multi-class classification), XGBoost also supports ranking and user-defined objective functions. This versatility allows it to be tailored to very specific business problems, which may not always conform to standard regression or classification frameworks.
The customization options of XGBoost further enhance its flexibility. Users can specify various parameters to influence the model’s performance and behavior, including the number of boosting rounds, tree depth, learning rate, and regularization parameters. These can be fine-tuned to optimize model performance according to the specific requirements of the problem at hand. In addition to built-in hyperparameters, XGBoost provides a function to create custom optimization objectives and evaluation criteria, allowing for an even higher degree of model tuning.
These customization capabilities, combined with support for different objective functions, make XGBoost an incredibly versatile machine learning algorithm. Whether it’s fine-tuning a model for a specific task, adjusting to particular data characteristics, or creating a completely custom optimization goal, XGBoost provides the tools necessary for data scientists and machine learning practitioners to create highly accurate, bespoke models for an extensive variety of predictive modeling tasks.
Handling Missing Values and Outliers with XGBoost
XGBoost provides a powerful approach to handle missing values, which are common in real-world datasets. Instead of requiring a pre-processing step to impute missing data, XGBoost incorporates a mechanism to deal with missing values internally. When a value is missing in a certain feature, XGBoost algorithm finds the best direction to handle the missing values, either to the left or right child node in the decision tree. This direction is determined based on the path that optimizes the loss function. This automated, intelligent handling of missing data reduces the need for manual intervention and can result in more robust models.
In addition to its robust handling of missing values, XGBoost is also resistant to outliers. This is primarily due to the fact that it’s a tree-based algorithm. In general, decision trees split on a feature based on a certain condition, such as whether a feature is less than or greater than a certain value, rather than the exact value of a feature. As a result, extreme values or outliers have less impact on the decision-making process of the tree, and subsequently, on the overall model.
These inherent capabilities of XGBoost to handle missing values and outliers make it an excellent choice for various real-world data science tasks. In practical applications where data is often incomplete or contains outliers, XGBoost can provide superior performance with less pre-processing compared to other machine learning algorithms. These features help to simplify the machine learning pipeline, making model development more efficient and robust.
Tree Pruning and Parallel Processing in XGBoost
One of the defining features of XGBoost is its ability to perform tree pruning. Unlike traditional gradient boosting where trees are grown to their maximum depth before being pruned back, XGBoost uses a strategy known as ‘early stopping’. This involves halting the addition of new splits to a tree when the addition of new nodes fails to bring about a significant reduction in the loss function. By including a regularization term in its objective function that controls the model’s complexity, XGBoost penalizes more complex models through both L1 (lasso) and L2 (ridge) regularization. This prevents overfitting and helps create an optimal balance between model bias and variance.
Parallel processing is another hallmark feature of XGBoost that contributes to its efficiency. Although decision tree construction is inherently sequential, XGBoost achieves parallelization by creating histograms of the feature columns. These histograms enable the algorithm to independently propose the optimal split points for each column. Once these are proposed, the best split across all columns is chosen, and the process repeats until the tree is fully grown. This parallel processing of columns significantly speeds up the training process and is a core reason why XGBoost often outperforms other gradient boosting algorithms.
Both the tree pruning mechanism and the parallel processing ability give XGBoost a competitive edge over other machine learning models. By enabling the creation of more efficient and accurate models, XGBoost offers a powerful and flexible tool for a wide variety of prediction tasks. Whether it’s predicting house prices, identifying customers likely to churn, or classifying emails into spam and non-spam, XGBoost’s unique features make it an important asset in a data scientist’s toolkit.
Built-in Cross-Validation: Optimizing Predictive Accuracy in XGBoost
XGBoost possesses a significant feature known as built-in cross-validation at each iteration of the boosting process. This property is vital to model tuning and enhancing the predictive power of the model. During the training phase, XGBoost allows a user to run a cross-validation at each boosting iteration, which provides a set of results that can be leveraged to determine the optimal number of boosting iterations for a given dataset. This procedure reduces the risk of overfitting, as it stops the model’s complexity from escalating through excessive iterations that could make the model fit the training data too closely.
Further, XGBoost’s built-in cross-validation employs a technique called k-fold cross-validation, wherein the data is divided into ‘k’ subsets or ‘folds’. The model is then trained on ‘k-1’ folds while the remaining fold is used as the validation set. This process is repeated ‘k’ times, each time with a different fold used as the validation set. This practice ensures that all data points are used for both training and validation, enhancing the model’s generalizability. The ability to perform such an exhaustive cross-validation procedure built into the algorithm significantly enhances XGBoost’s robustness and predictive accuracy, making it an invaluable tool for machine learning tasks.
Flexibility in XGBoost: Custom Optimization Objectives and Evaluation Criteria
One of the key model features of XGBoost is its ability to allow users to define custom optimization objectives and evaluation criteria. This flexibility is crucial, especially in complex tasks where generic objectives might not be sufficient or optimal. For example, while XGBoost provides built-in objectives for regression, binary classification, and multiclass classification, users might need to introduce their specific loss functions tailored to their problem domain. The provision to customize the optimization objective function enables this, thereby increasing the range of problems that XGBoost can address.
In addition to custom objectives, XGBoost also allows for the specification of custom evaluation criteria. This feature becomes particularly useful when standard metrics such as accuracy or area under the ROC curve do not completely capture the performance characteristics important for a specific task. For instance, in situations with highly imbalanced classes, customized evaluation metrics like the F1 score or area under the precision-recall curve might be more appropriate. By enabling the user to specify both the optimization objective and evaluation metric, XGBoost stands out for its adaptability to a wide array of machine learning problems, enhancing its versatility and performance in diverse application scenarios.
Distributed Computing with XGBoost: Managing Large Datasets
XGBoost stands out for its capabilities in distributed computing, which enable it to handle large datasets efficiently. Traditional machine learning algorithms often struggle with big data due to memory constraints and lengthy computation times. However, XGBoost was designed with an emphasis on computational speed and model performance, and it can be parallelized across multiple cores or distributed across several machines, thereby considerably reducing the computational burden. It does this using a block structure to manage data and an efficient algorithm called “Column Block” to support distributed computing for both gradient boosting and tree learning.
The architecture of XGBoost is designed such that it can leverage all the available resources to speed up the training process. It supports various distributed computing environments, including Hadoop, MPI (Message Passing Interface), and Sun Grid Engine, making it scalable for handling enormous datasets. By using a column block structure for data storage, XGBoost can more efficiently calculate splits and gains in the dataset while consuming less memory. This design decision makes XGBoost not only capable of dealing with larger datasets but also speeds up the model training and prediction times, providing users with an efficient tool for their big data tasks.
Out-of-core Computing in XGBoost: Utilizing Secondary Storage Systems
XGBoost is equipped with an out-of-core computing feature that is designed to tackle data that cannot fit into the memory. This feature allows XGBoost to utilize secondary storage systems, like hard disks, to handle larger datasets. It is achieved by strategically dividing the data into multiple blocks and then loading each block into memory one at a time for processing. The block structure and the columnar storage format of XGBoost makes it capable of dealing with larger-than-memory data on a single machine.
Out-of-core computing in XGBoost also benefits from its innovative algorithmic enhancements. The “Block Structure” used by XGBoost allows the dataset to be split into multiple blocks that can be stored in the secondary storage system. It uses a combination of multi-threading and disk-based storage to efficiently process data blocks, making it possible to compute the optimal splits of the tree across large datasets. With this feature, XGBoost can handle vast datasets that would be impossible to process using traditional in-memory processing techniques, thus bridging the gap between data size and processing capacity.
Continued Training in XGBoost: Incremental Learning and Model Improvement
One of the notable features of XGBoost is its capability for continued training, also known as incremental learning. This allows XGBoost models to be further improved by training on new data without having to retrain from scratch. This feature is particularly useful for applications where new data continuously arrives and needs to be incorporated into the existing model. By training the model incrementally, XGBoost can update the model to accommodate the new data, thus ensuring that the model stays updated and continues to make accurate predictions.
With incremental learning, XGBoost takes the existing model and then applies further rounds of training using the new data. This process improves the performance of the model by refining its predictions based on the additional data. By training the model in this manner, XGBoost also ensures efficient use of computational resources as it doesn’t require a complete retraining process each time new data is available. This feature makes XGBoost particularly suitable for environments where data availability is not static, but dynamically changing over time.
Heterogeneous Data Handling in XGBoost: Navigating Numerical and Categorical Data
XGBoost stands out in its ability to efficiently handle heterogeneous data, meaning it can seamlessly work with a combination of numerical and categorical data. In many practical applications, datasets often contain a mix of these two types of data. Numerical data are represented as numbers and can be manipulated with mathematical operations. In contrast, categorical data are typically presented as distinct categories or groups. XGBoost can incorporate both these data types in its model, making it versatile for a wide range of machine learning problems.
One of the methods XGBoost employs to deal with categorical data is through encoding techniques. For example, one-hot encoding can be used to transform categorical data into a format that can be understood by the model. On the other hand, numerical data can be directly fed into the model. XGBoost handles missing data by employing a unique splitting algorithm. Instead of discarding missing values or filling them with a mean or median value, XGBoost learns the best direction to handle missing values during the training process. This robust heterogeneous data handling capability of XGBoost makes it a versatile tool in the field of machine learning, capable of dealing with a wide range of data formats.
XGBoost Algorithm Features
XGBoost, an abbreviation for “Extreme Gradient Boosting,” incorporates a number of sophisticated algorithm features, making it a high-performance model for both regression and classification tasks. It’s designed to be a scalable tree boosting system, which uses gradient statistics and an internal buffer for optimized speed and performance. One of the key features of XGBoost is its usage of a gradient boosting framework. This means that at its core, XGBoost is an ensemble method that creates a strong prediction model by combining multiple weak models, referred to as base learners. In the case of XGBoost, the base learner is a simple decision tree.
The construction of these base learners involves a sequential process that focuses on the errors of the previous tree to improve the subsequent one. This method, known as the step of tree boosting, reduces the contribution of random guessing and enhances the model’s predictive accuracy. Every individual tree is built upon the learnings from the preceding trees and influences the construction of future trees. The final prediction is then made by summing up the predictions of all the individual trees, thereby creating a strong tree ensemble model. Each of these trees consists of several leaf nodes which can handle varying forms of gradient boosting to handle both linear and non-linear relationships in the training dataset.
XGBoost also boasts a feature known as parallelization of tree construction, making the most of CPU cores during training and applying machine learning on large-scale tasks. By using a distributed weighted quantile sketch method, it efficiently utilizes CPU cores and can be run on a cluster of machines without sacrificing speed or performance. This feature allows XGBoost to manage large datasets that don’t fit into memory, making it scalable and efficient. The algorithm carefully manages resources, such as memory and CPU, during the model training process, further highlighting the efficiency and adaptability of XGBoost in applied machine learning contexts.
Implementing the algorithm was designed to allow the most efficient use of compute time and memory resources. For the training of the model, one design goal consisted of making the most of the available resources.
Key features of the algorithm implementation include the following:
Sparse Aware: A sparse-aware implementation that takes into account missing data values.
Block Structure: A block structure to support the parallelization of the tree construction process.
Continuous Training: It is essential that you continue to train so that you can further enhance a model that has been fitted to new data.
Why Use XGBoost?
The XGBoost package has been integrated with a wide range of other tools and packages, such as scikit-learn for Python enthusiasts and caret for R enthusiasts. Also, XGBoost is integrated with a number of distributed processing frameworks such as Apache Spark and Dask.
XGBoost refers to a version of Gradient Boosting that is more regularized. The XGBoost model makes use of advanced regularization techniques (L1 & L2), which improves the model’s generalization abilities. Comparing XGBoost with Gradient Boosting, XGBoost delivers high performance compared to Gradient Boosting. The training process is fast and can be parallelized across multiple clusters.
What Algorithm Does XGBoost Use?
XGBoost is a library that implements a gradient boosting decision tree algorithm.
There are lots of different names given to this algorithm, such as gradient boosting, multiple additive regression trees, stochastic gradient boosting, and gradient boosting machines.
Boosting is a technique in which new models are added to fix errors made by existing ones. In this technique, new models are added sequentially until there is no more improvement to be made. The AdaBoost algorithm is a popular example of how the algorithm weights data points that are hard to predict.
Gradient boosting uses new models to predict the residuals or errors of previous models, which are then added together to produce the final prediction. Gradient boosting refers to the process of adding new models in a way that minimizes the loss by using a gradient descent algorithm. Gradient-boosting can be applied to both regression and classification predictive modeling problems.
Also Read: The Role Of Artificial Intelligence in Boosting Automation.
How XGBoost Runs Better With GPUs
With XGBoost, machine learning tasks powered by the CPU can take literally hours to complete. That’s because the creation of highly accurate, state-of-the-art predictions requires the construction of thousands of decision trees and the testing of many parameter combinations in the process. The graphics processing units, or GPUs, with their massively parallel architecture made up of thousands of small, efficient cores, are able to launch thousands of parallel threads simultaneously in order to handle compute-intensive tasks more efficiently.
Code Example of XGBoost
Please note that you might need to install the XGBoost library if you haven’t already. You can do this using pip:
pip install xgboostHere’s a simple example of how you can use XGBoost for classification tasks using Python. This example uses the Iris dataset, a popular dataset in machine learning, available in the sklearn library.
import xgboost as xgb
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Load the iris dataset
iris = datasets.load_iris()
X = iris.data
y = iris.target
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Define the XGBoost classifier
model = xgb.XGBClassifier(use_label_encoder=False)
# Train the model
model.fit(X_train, y_train)
# Make predictions
y_pred = model.predict(X_test)
# Evaluate accuracy
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy: %.2f%%" % (accuracy * 100.0))What have we done with the code so far –
We first import necessary libraries and modules.
We load the Iris dataset and split it into training and test sets using the train_test_split function.
We then create an instance of the XGBClassifier, which we call model.
The model.fit function is used to train the model using our training data.
Once the model is trained, we use it to predict the labels of our test data.
Finally, we calculate the accuracy of our model by comparing the predicted labels to the true labels.
Conclusion
XGBoost is a library which can be used to develop fast and high performance gradient boosting tree models. It is proven that XGBoost provides the best performance on a wide range of difficult machine learning tasks.
The XGBoost library can be used from the command line, Python, and R. We have a large and growing list of data scientists around the world who are actively contributing to the open source development of XGBoost.
XGBoost can be used on on a wide range of applications, including solving problems in regression, classification, ranking, and user-defined prediction challenges. XGBoost has cloud integration that supports AWS, Azure, GCP, and Yarn clusters. It is being used in various industries and different functional areas. It’s biggest advantage is its performance and ability to give results almost in real time.
XGBoost has established itself as a powerful algorithm in the field of machine learning, thanks to its unique features and capabilities. It encapsulates the principles of machine learning, including handling overfitting and missing values, managing computation limits, and efficiently dealing with large datasets on classification and regression predictive tasks.
The algorithm is structured around the idea of gradient boosting, where weak classifiers are sequentially trained to generate a strong classifier. XGBoost’s specific implementation of Gradient Boost is designed to optimize the training time and computational efficiency, making it an algorithm of choice for many data scientists.
The algorithm leverages a differentiable loss function and the principle of boosting to create an ensemble of weak classifiers, which together form a single model with high predictive accuracy. XGBoost also gives deep considerations to the limits of machines and features such as the cost of sorting and the subsample ratio, all of which contribute to its performance and speed. The algorithm effectively reduces the need for extensive feature engineering, and instead can leverage the original dataset to produce valuable insights.
Hyperparameter tuning also plays a significant role in enhancing the model’s performance by influencing the construction of each terminal node and consequently the entire model’s structure. Thus, XGBoost stands as one of the most reliable, efficient, and powerful algorithms, streamlining the process of predictive modeling while delivering superior results.

References
Brownlee, Jason. XGBoost With Python: Gradient Boosted Trees with XGBoost and Scikit-Learn. Machine Learning Mastery, 2016.
Quinto, Butch. Next-Generation Machine Learning with Spark: Covers XGBoost, LightGBM, Spark NLP, Distributed Deep Learning with Keras, and More. Apress, 2020.
Wade, Corey. Hands-On Gradient Boosting with XGBoost and Scikit-Learn: Perform Accessible Machine Learning and Extreme Gradient Boosting with Python. Packt Publishing Ltd, 2020.