Introduction
The purpose of this article is to demonstrate how supervised learning works, and how you can use it to build highly accurate machine learning models.
Table of contents
Supervised Learning
A supervised deep learning algorithm enables the system to learn by example through the use of an observer (that can correct the outputs) overseeing the whole process. The term “supervised” indicates that the algorithm is driven by observing and correcting errors during the entire process.
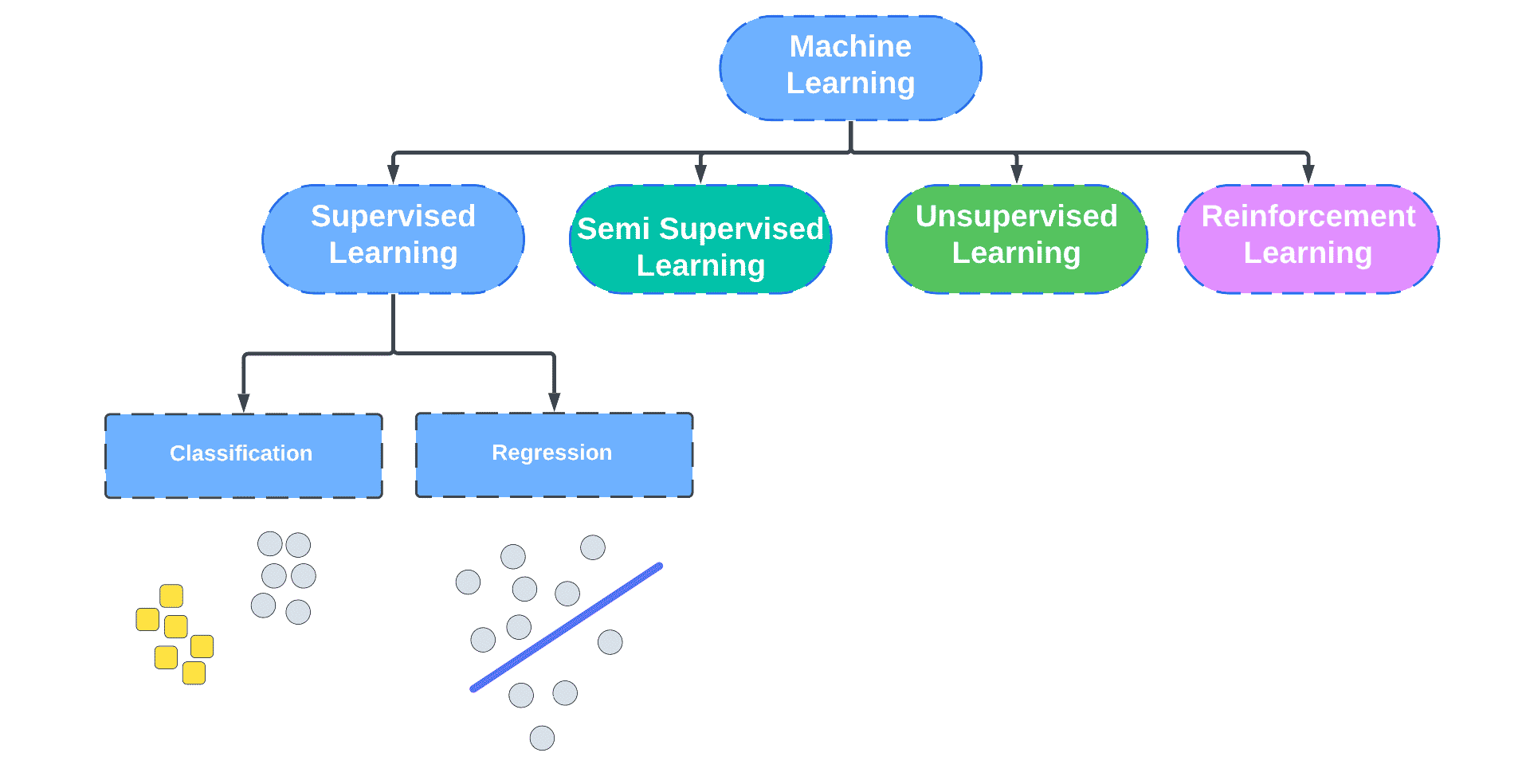
Supervised learning is one of the subcategories of machine learning and artificial intelligence, and it can also be referred to as supervised machine learning (SML).
In order to train algorithms that are able to classify data or predict outcomes accurately, this method depends on labeled datasets that can be used to train algorithms.
As data is fed into the model, the weights are adjusted constantly until the model has an appropriate fit, which is part of the process of cross-validation which is performed during and after the model has been fed with data.
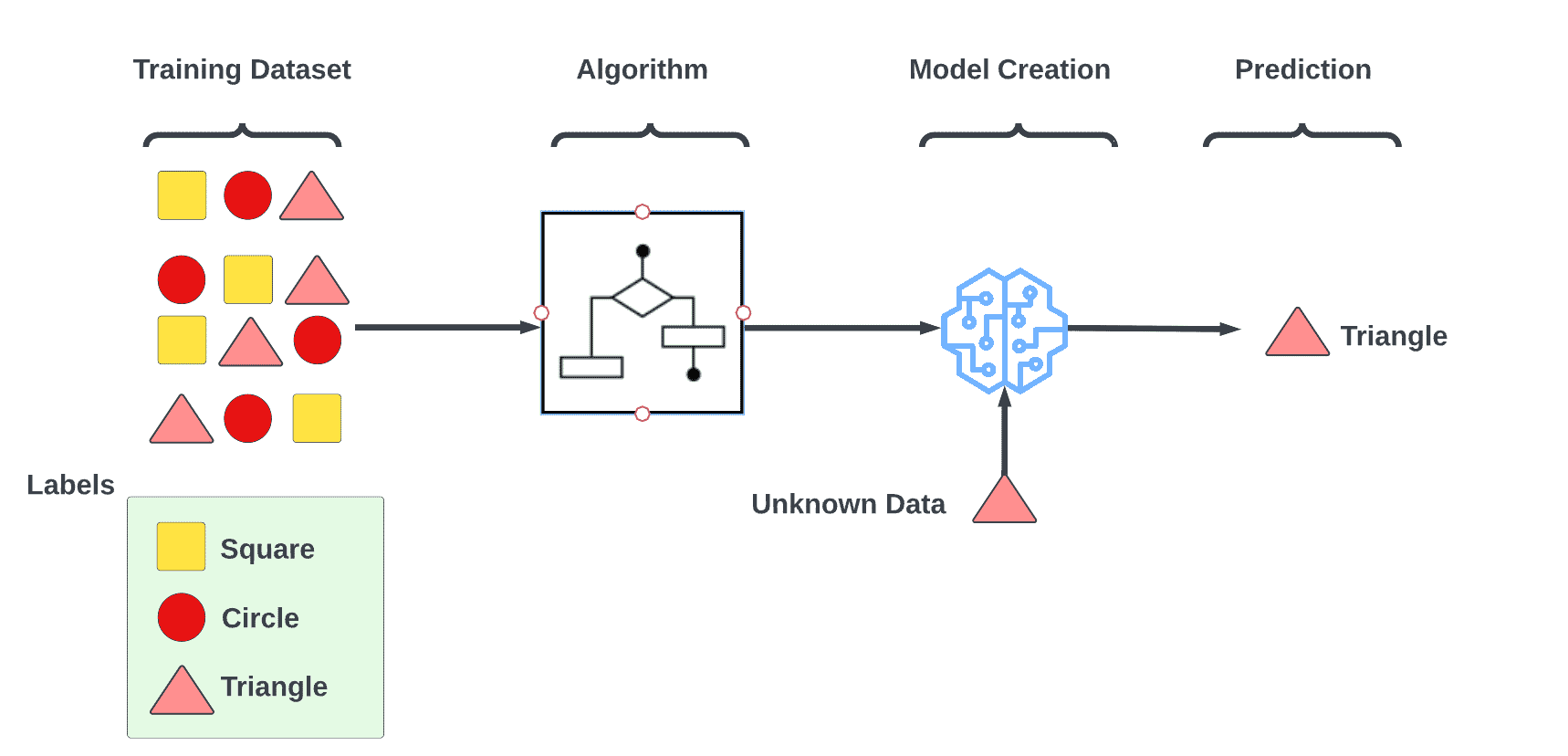
Supervised learning process involves identifying or mapping input data with the output data provided, in essence supervising the outcome. Supervised learning algorithms work to find a mapping function between an input variable (x) and an output variable (y) based on the datasets it’s been trained on.
Y = f(X)
The mapping function should be approximated so well that, when new inputs are introduced into the model (x), the output values (Y) can be predicted.
During the process of learning, we know the correct answers, the algorithm makes predictions based on the training data, and then the teacher corrects the algorithm as it moves forward. Once the algorithm achieves a level of performance that we approve of, learning ends.
Supervised learning helps us solve real world problems like Risk Assessment, Image classification, Fraud Detection, and spam filtering.
Supervised learning steps
The first step is to identify the type of training dataset to be used based on the outcome desired.
Next step is to collect labelled training data which will help us train the algorithm.
Build a training dataset, a test dataset, and a validation dataset from the training data collected.
Input features of the training set must be determined in order for the model to accurately classify the output.
A good modeling technique should be chosen according to an appropriate algorithm, such as a SVM, a DecisionTree, etc.
Execute the algorithm on the training dataset. Validation sets, which are subsets of training data, can sometimes be used as control parameters in the experiments to adjust weights till you get the desired results.
Evaluate the accuracy of the model by providing the test set. If the model predicts the correct output, which means our model is closer to being working as expected as you are seeing the desired outcome. This may need multiple adjustments.
How supervised learning works
To teach a model to produce the desired output, supervised learning uses a training set with labelled data to processed unlabelled data to predict the outcome. It includes inputs and correct outputs that allow it to learn over time. In order to improve prediction, the algorithm adjusts weights based on the loss function and assesses accuracy.
Supervised learning can be separated into two types of problems when data mining—classification and regression:
Classification uses an algorithm to assign test data into specific categories.Using a classification algorithm, test data can be categorized into various categories. The algorithm recognizes specific entities within the dataset and attempts to determine how those entities should be classified. In the following sections, we will discuss linear classifiers, support vector machines (SVM), decision trees, k-nearest neighbors, and random forests in greater detail.
Regression analysis helps us examine the relationship between dependent and independent variables. It is commonly used to make projections, such as for sales revenue for a given business. Linear regression, logistical regression, and polynomial regression are popular regression algorithms.
Supervised learning algorithms
Various algorithms and computation techniques are used in supervised machine learning processes. Below are brief explanations of some of the most commonly used learning methods, typically calculated through use of programs like R or Python:Neural networks
By mimicking the interconnectedness of the human brain through layers of nodes, neural networks process training data. The nodes in a network are made up of inputs, weights, biases (or thresholds), and outputs. Nodes activate or fire when the output value exceeds a certain threshold, and data is passed along to subsequent layers. Gradient descent allows neural networks to adjust based on the loss function. By learning the mapping function supervised learning, we can be confident that the model is accurate if the loss function is near zero.
Naive Bayes
According to the Bayes Theorem, naive Bayes is a classification approach that emphasizes the conditional independence of classes. Each predictor has a similar effect on an outcome, so the presence of one feature does not influence the presence of another. Systems that identify spam, classify texts, and recommendation systems use this technique.Nave Bayes classifiers come in three types: Multinomial Nave Bayes, Bernoulli Nave Bayes, and Gaussian Nave Bayes.
Linear regression
Typically, linear regression is used to predict future outcomes by determining the relationship between a dependent variable and one or more independent variables. The regression is called simple linear regression when there is only one independent variable and one dependent variable. It is called multiple linear regression when there are more independent variables.For each type of linear regression, it seeks to plot a line of best fit, which is calculated through the method of least squares.
Logistic regression
While linear regression is leveraged when dependent variables are continuous, logistical regression is selected when the dependent variable is categorical, meaning they have binary outputs, such as “true” and “false” or “yes” and “no.” While both regression models seek to understand relationships between data inputs, logistic regression is mainly used to solve binary classification problems, such as spam identification.
Support vector machine (SVM)
The support vector machine, developed by Vladimir Vapnik, is an effective supervised learning model for both data classification and regression. As a result, it is typically used to solve classification problems, by establishing a hyperplane where the greatest distance exists between two classes of data points. In the decision boundary, data points are separated on either side.
K-nearest neighbor
Based on the proximity of data points to one another and their association with other data, the K-Nearest Neighbor algorithm is a non-parametric classification technique. Thus, similar data points are assumed to be close to one another in this algorithm. This is accomplished by calculating the distance between data points, typically using Euclidean distance, and assigning a category or average based on that distance. It’s easy to use and requires little computation, making it a favorite algorithm among data scientists. However, as test datasets grow, KNN becomes less useful for classification tasks.
Random forest
In addition to classification and regression, the random forest algorithm is another flexible supervised machine learning algorithm. To create more accurate data predictions, the “forest” refers to a collection of uncorrelated decision trees that are merged together in an effort to reduce variance and improve prediction.
Supervised learning examples
Supervised learning models can be used to build and advance a number of business applications, including the following:
Image- and object-recognition: Supervised learning algorithms can be used to locate, isolate, and categorize objects out of videos or images, making them useful when applied to various computer vision techniques and imagery analysis.
Predictive analytics: Supervised learning models have been widely applied to develop predictive analytic systems. Business leaders can use these models to justify decision making or predict future outcomes.
Customer sentiment analysis: Using supervised machine learning algorithms, organizations can extract and classify important pieces of information from large volumes of data—including context, emotion, and intent—with very little human intervention. This can be incredibly useful when gaining a better understanding of customer interactions and can be used to improve brand engagement efforts.
Spam detection: Another example of a supervised learning algorithm is email filtering. Training a set of rules to identify spams allows organizations to block them from reaching their intended recipients.
Challenges of supervised learning
The development of sustainable supervised learning models can present some challenges for businesses, despite its advantages, including deep data insights and improved automation. The following are some of these challenges:
Structured learning models can require a certain level of expertise and knowledge to maintain.
Training supervised learning models can be very time intensive.
It is possible that algorithms can learn incorrectly when datasets are prone to human error or bias.
It is not possible to luster or classify data automatically.
Conclusion
Supervised learning, as a dominant paradigm in machine learning, plays a critical role in the development of intelligent systems capable of making predictions or decisions based on historical data. Through the use of labeled training data, supervised learning algorithms are adept at discerning patterns and relationships within datasets, which they can later apply to unseen data. Its applications are diverse and vast, ranging from image recognition and natural language processing to financial forecasting and healthcare diagnostics. As technology progresses, it is expected that supervised learning will continue to evolve, becoming more efficient and accurate. However, it is imperative to address challenges such as overfitting, data quality, and ethical considerations to ensure that supervised learning continues to be a reliable and beneficial tool in the broader spectrum of artificial intelligence.
References
C, Gnana Lakshmi T., and Madeleine Shang. Hands-on Supervised Learning with Python: Learn How to Solve Machine Learning Problems with Supervised Learning Algorithms Using Python (English Edition). BPB Publications, 2021.
Jo, Taeho. Machine Learning Foundations: Supervised, Unsupervised, and Advanced Learning. Springer Nature, 2021.
Johnston, Benjamin, and Ishita Mathur. Applied Supervised Learning with Python: Use Scikit-Learn to Build Predictive Models from Real-World Datasets and Prepare Yourself for the Future of Machine Learning. Packt Publishing Ltd, 2019.
Smith, Taylor. Supervised Machine Learning with Python: Develop Rich Python Coding Practices While Exploring Supervised Machine Learning. Packt Publishing Ltd, 2019.