Introduction
Machine learning algorithms can be broadly categorized as supervised, semi-supervised, unsupervised and reinforcement learning algorithms.
This article talks about unsupervised machine learning algorithms and how it works.
Table of contents
Also Read: Is deep learning supervised or unsupervised?
What is Unsupervised Learning?
Unsupervised learning is a technique where models are not trained on datasets. The data encountered in this case is neither classified nor labeled.
Supervised learning is used in scenarios where we have label datasets (training set) and a desired output. A couple examples of supervised learning are:
- Logistic regression can work when we have a data set which can give an output of ‘yes’ or ‘no’ which cannot be the case with unsupervised learning.
- Decision Trees are another example where the data is continuously split according to a certain parameter
Unlike supervised learning, there is no training set in unsupervised learning, meaning that there is no correct answer or desired ouput as such. The algorithm is expected to develop an understanding of the structure of the data, figure out the similarities or any hidden patterns, and represent it in a compressed form.
You can imagine this to be very similar to how the human brain works by figuring out different categories of data.
Common unsupervised learning approaches
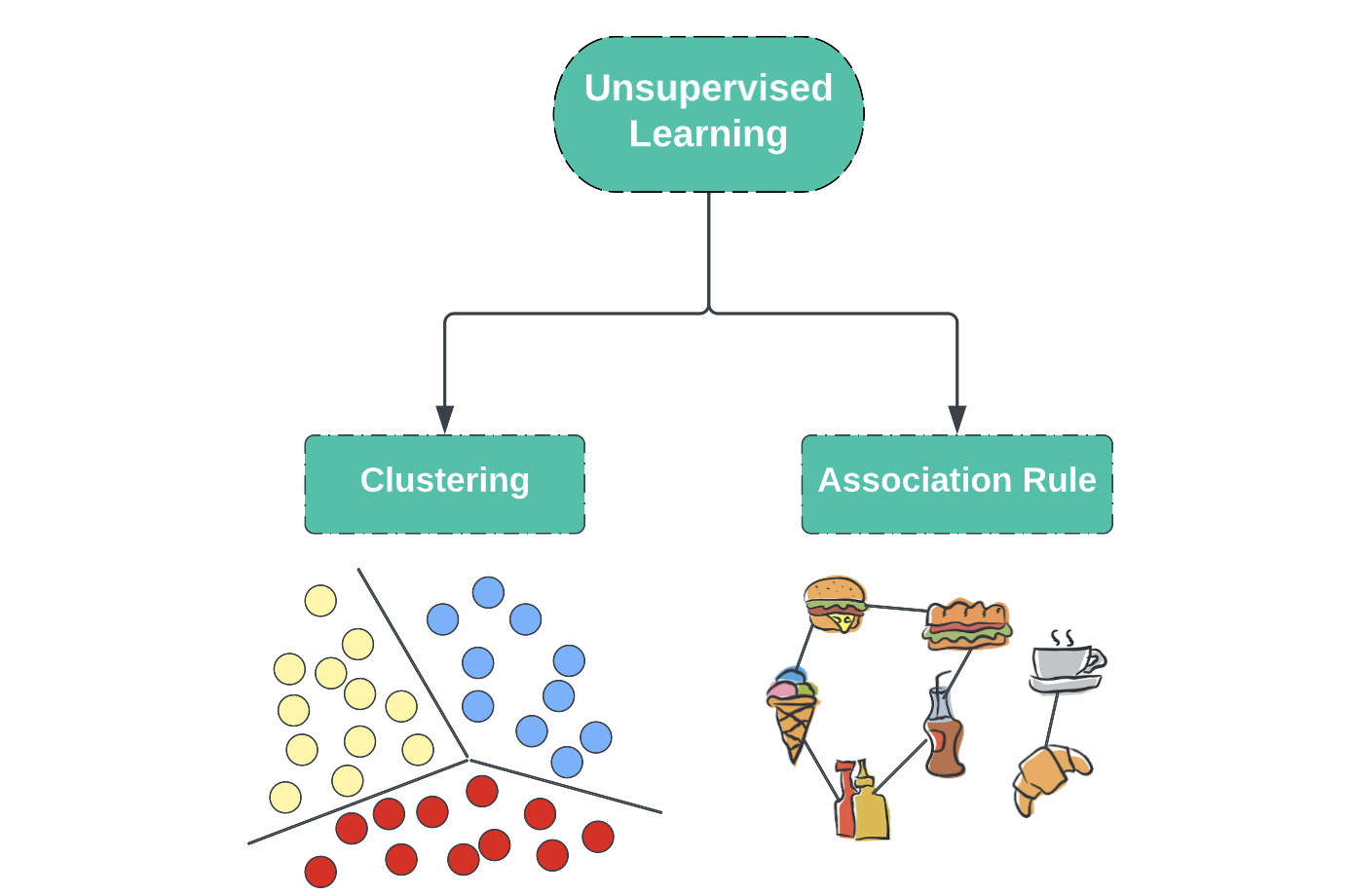
There are 2 types of unsupervised learning:
1. Clustering
2. Association rule
We shall talk about each type in detail in the coming section.
Clustering
Clustering also known as cluster analysis, is the method of grouping objects into groups. The goal of doing this is to analyze commonalities between data points and group them based upon the presence and absence of those commonalities. These individual groupings are known as clusters.
While using clustering algorithms, the input data has no labels, and for each data point we try to find similarity with surrounding data points.
When nothing is known about the input data, clustering is a great way to begin and gain some insights. Clustering algorithms are of different types based upon the way these data points are analyzed and the number of clusters a particular data point can belong to.
Distance-based clustering while forming clusters, we group points together such that the internal distance is small and external distance is large. The distance can be considered to be the Euclidean Distance between points. Internal distance is the distance between any 2 points in a cluster (showing similarity). External distance is the distance between any 2 points in different clusters (showing dissimilarity).
There are a number of unsupervised clustering algorithms in machine learning. They are also referred to as clustering types. Here are a few of them:
- Exclusive and overlapping clustering
- Hierarchical clustering (Agglomerative clustering and divisive clustering)
- Probabilistic
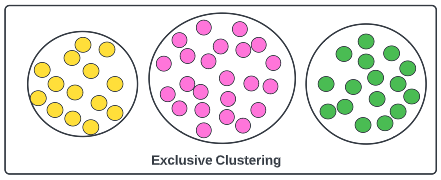
Exclusive Clustering
Exclusive clustering means that while creating the clusters, a single observation shall exist in just a single cluster. There shall be no overlapping of clusters complete exclusivity shall be maintained
Let’s look at an example of exclusive clustering: K-means clustering algorithm aims to partition n observations into k clusters.
The term centroid is used to refer to the center of a cluster. The algorithm uses an iterative process to arrive at the most optimal value for k. Each data point is assigned to the closest centroid, and this forms a cluster. The above diagram can be considered an example of k-means clustering, and the value of k here is 3.
Overlapping Clustering
Overlapping clustering also known as non-exclusive clustering means that the point can exist in multiple clusters with a different degree of membership. This can happen when there is a single random point existing between 2 clusters, it is better to make it likely to occur in both of them rather than creating a new cluster for it. The degree of membership provides us a value indicating the degree to which a points belongs to a particular cluster.
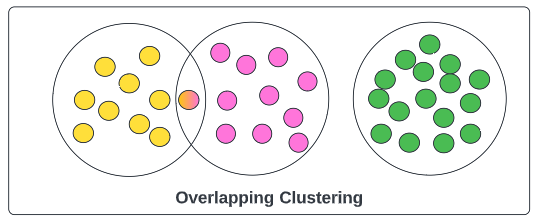
Example: An person can be classified as a living thing and male at the same time by the clustering algorithm.
Fuzzy K-means clustering This is exactly the same as K-means clustering we discussed above, but in case of the fuzzy k-means algorithm the points can exist in two or more of clusters at the same time. Hence, we classify it as overlapping clustering. Its not necessary that the point is a member of both clusters with equal weightage, it can have different degrees of membership with different clusters.
Hierarchical Clustering
Hierarchical clustering also referred to as hierarchical clustering analysis (HCA). In this type of clustering we develop a hierarchy of clusters in the form of a tree. The HCA process is divided depending upon the way in which the hierarchy is created.
- Agglomerative clustering This algorithm follows the bottom up approach. Each data point is initially considered a cluster, and then we start combining the closest pair of clusters. We continue to do this process till we have a single cluster.The clusters are combined based upong similarities and there are 4 methods used to measure this similarity:
- Complete (or maximum) linkage: Using maximum distance between two points in each cluster.
- Single (or minimum) linkage: Using the minimum distance between two points in each cluster.
- Average linkage: Using mean distance between two points in each cluster.
- Ward’s linkage: Unlike the above methods where direct distance is used, we use variance in case of wards linkage. If we have 2 clusters A and B, the distance between them is the how much the sum of squares shall increase if we merge them.
- Divisive clustering This algorithm follows the top-down approach. The complete data is considered as a single cluster, and then we continue to split the cluster down into smaller clusters. This process is rarely done in practice.
When we keep track of the merges or splits, it shall form a tree like structure which is referred to as dendogram.
Probabilistic clustering
When clustering is done based upon the data points belonging to a particular distribution it is known as probabilistic clustering. A probabilistic model helps us solve soft clustering and density estimation problems.
An example of this is Gaussian Mixture Model (GMM). We use the term mixture here, as they are made up of an unspecified number of probability distribution functions. It is leveraged to figure out which Gaussian or normal probability distribution, a data point might belong to.
Association Rules
Association rule learning as the name suggests tries to figure out association between data points. The goal is to figure out relationships in the data.
The most common example of this comes in market basket analysis. Looking at the items in the purchaser’s basket, the goal is to figure out which items are most likely to be brought together. This allows the retailer to place those items together or in case of an online company like Amazon recommends which items are brought together. It also helps with the creation of combo offers, which helps boost sales and makes it easier for the customer to buy things together.
Apriori algorithm
Apriori algorithm also referred to as frequent pattern mining is generally used for operating on databases that consist of a huge number of transactions. The best example for it is the market analysis problem that has been explained above. It is also used in the medical field to help understand the allergies a person might have too.
Dimensionality reduction
Dimensionality is the number of variables, characteristics, or features present in the dataset. These dimensions are represented as columns, and the goal is to reduce their number.
In most cases where there are last data sets, the columns could contain redundant information. This redundant information leads to the increase in dataset’s noise. It also leads to a negative impact on the training model and performance. Hence, we can reduce the model’s complexity and avoid overfitting.
The next section discusses a few types of Dimensionality reduction algorithms.
Principal component analysis
Principal Component Analysis(PCA) is a type of dimensionality reduction. It uses orthogonal transformation to convert a set of observations of correlated features into a set of linearly uncorrelated features. These new transformed features are called the principal components. It is one of the popular tools that is used for exploratory data analysis and predictive modeling. Some real-world applications of PCA are image processing, movie recommendation system, optimizing the power allocation in various communication channels.
Singular value decomposition
Singular value decomposition (SVD) is one of the most popular unsupervised learning algorithms. It is widely used in recommendation systems, this is core to companies like Google, Netflix, Facebook etc.
SVD requires us to decompose a matrix in 3 matrices. Which looks something as shown below.
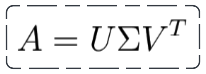
Autoencoders
Autoencoders are an example of ANN (artificial neural network). While applying it to dimensionality reduction, the aim is to encode the data into lower dimensions and then decode this data to get back the original input.
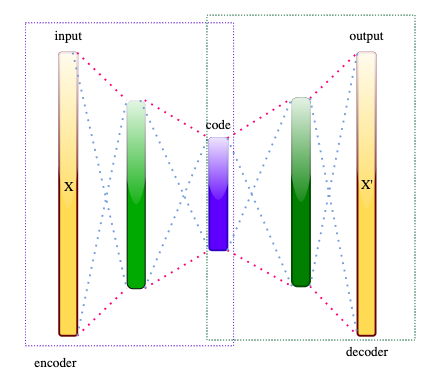
- Encoder: Compress the data
- Decoder: Reconstructs back the data.
Applications of unsupervised learning
- Splitting of data into groups based upon their similarity measure. Clustering methods are used to study cancer gene expression data and predict cancer at early stages.
- Neural Networks The principle that neurons that fire together wire together. In Hebbian Learningthe connection is reinforced irrespective of an error, but is exclusively a function of the coincidence between action potentials between the two neurons. [source]
- Deteccting of unusual data points in a data set. Example:
- Detect any sort of outliers in data from transportation and logistics companies, where anomaly detection is used to identify logistical obstacles or expose defective mechanical parts.
- Detect faulty equipment or breaches in security.
- Fraud detection in transactions
- Object recognition: In the field of computer vision, it is utilized for visual perception tasks. It comes in really handy in image recognition.
- Dimensionality Reduction allows us to lower the number of features in a dataset prevent overfitting. It also reduces the computational complexity of algorithms.
- Utilizing the association rule to build recommender systems such as those of online and offline retail stores. It is used to develop cross-selling strategies, hence facilitating the add-on recommendations during checkout process.
- Medical Imaging devices are required to do image detection, classification, and segmentation. Unsupervised learning is leveraged to make this feasible.
- Building of a customer persona. Understanding the common traits and business client purchasing habits helps identify the customer persona, hence aligning the product goals a lot better.
Also Read: Introduction to Machine Learning Algorithms
Challenges of unsupervised learning
- Presence of unlabeled makes unsupervised learning far more difficult than supervised learning.
- The result of unsupervised learning can be in-accurate because of the absence of corresponding outputs.
- There needs to be a higher level of human interference to handle the data and the output variable.
- There is high possibility of models being incorrectly trained.
Extension
A greate way to proceed further would be to
- learn about the implemetations of the unsupervised learning algorithms we talked about above.
- Understand the different distributions that come into play while clustering data using probabilisitc clustering.
- Exploring semi-supervised learning which as the name says is a combination of supervised and unsupervised learning.
Checkout the resources below to find the implementation of various supervised learning algorithms.
- Introduction to clustering methods – scikit learn docs
- Unsupervised learning – scikit learn docs