Introduction to Long Short Term Memory (LSTM)
Sequence prediction in data science challenges usually involve the use of Long Short Term Memory (LSTM) networks. These types of recurrent Neural Networks can learn order dependence. During the current step of the RNN, the output of the previous step is used as the input to the current step. Hochreiter and Schmidhuber are responsible for creating the Long – Short Term Memory. It addressed the issue of “long-term reliance” on RNNs, where RNNs are unable to predict words stored in long-term memory but they can make more accurate predictions based on information in the current data. A rising gap length will not have a positive impact on RNN’s performance. LSTMs are known to hold information for a long time by default. This technique is used in the processing of time-series data, in prediction, as well as in classification of data.
Table of contents
What is LSTM
In the field of artificial intelligence (AI) and deep learning, LSTMs are long short-term memory networks that use artificial neural networks. These networks have feedback connections as opposed to standard feed-forward neural networks also known as recurrent neural network. LSTM is applicable to tasks such as unsegmented, connected handwriting recognition, speech recognition, machine translation, robot control, video games, and healthcare.
Recurrent neural networks can process not only individual data points (such as images), but also entire sequences of data (such as speech or video). With time series data, long – short term memory networks are well suited for classifying, processing, and making predictions based on data, as there may be lags of unknown duration between important events in a series. The LSTMs were developed in order to address the problem of vanishing gradients that is encountered when training traditional RNNs. It is the relative insensitivity of LSTMs to gap length, which makes them superior to RNNs, hidden Markov models and other sequence learning methods in many applications.
It is theoretically possible for classic RNNs to keep track of arbitrary long-term dependencies in the sequences of inputs. The problem with vanilla RNNs is that they do not apply for practical reasons. For instance, when training a vanilla RNN using back-propagation, the long-term gradients in the back-propagated networks tend to disappear (that is, reduce to zero) or explode (create infinite gradients), depending on the computations involved in the process, which employ a finite-precision number set. As long – short term memory units allow gradients to also flow unchanged, it is partially possible to resolve the vanishing gradient problem using RNNs using long – short term memory units. Despite this, it has been shown that long – short term memory networks are still subject to the exploding gradient problem.
Also Read: How to Use Linear Regression in Machine Learning.
Structure of LSTM
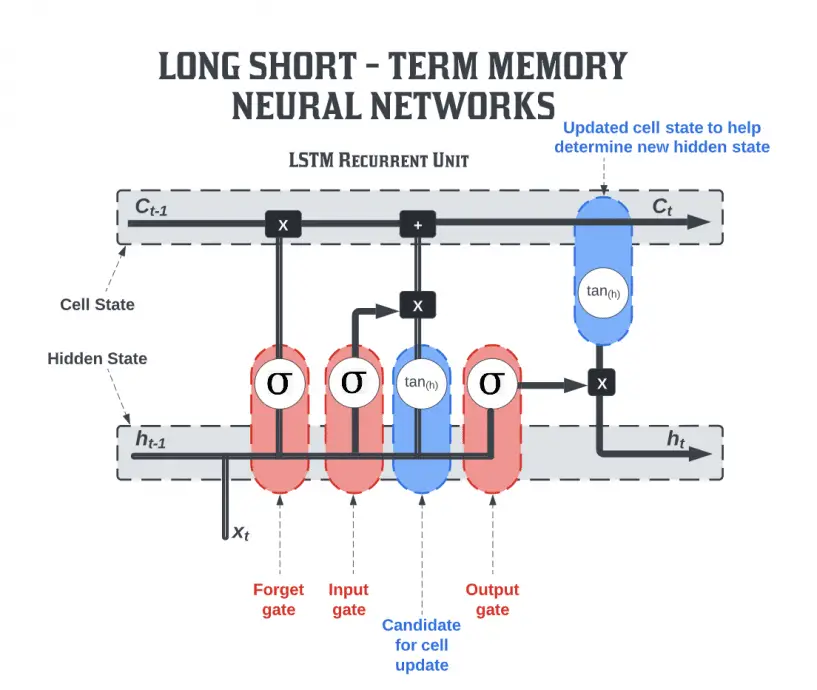
The long – short term memory is comprised of four neural networks and numerous memory blocks, or cells, that form a chain structure. There are four components in a conventional long – short term memory unit: a cell, an input gate, an output gate, and a forget gate. There are three gates that control the flow of information into and out of the cell, and the cell keeps track of values over an arbitrary period of time. There are many applications of long – short term memory algorithms in the analysis, categorization, and prediction of time series of uncertain duration.
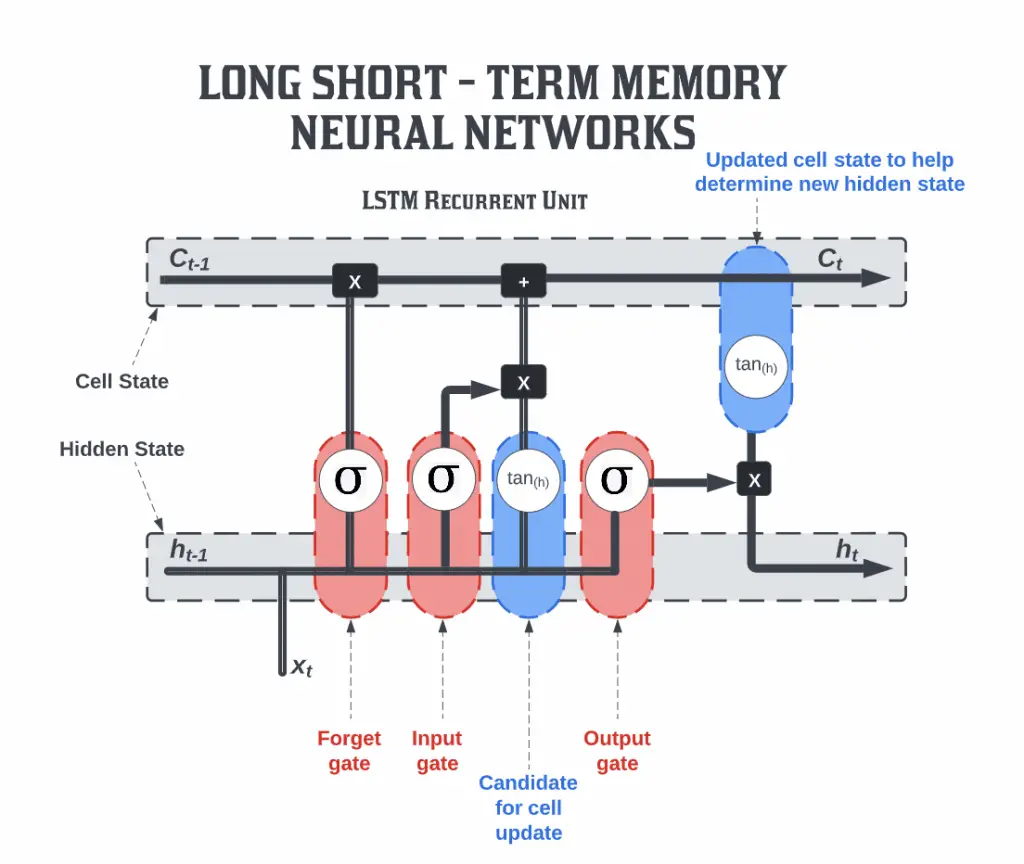
In general, a long – short term memory structure is comprised of a cell, an input gate, an output gate, and a forget gate. This cell retains values over arbitrary time intervals, and the three gates are responsible for controlling the flow of information into and out of the cell.
- Input Gates: These gates decide which of the values from the inputs is to be used to change the memory. The sigmoid function determines whether or not to allow 0 or 1 values through. In addition, using the tanh function, you can assign weights to the data, determining their importance on a scale of -1 to 1.
- The forget gate: finds all the details that should be removed from the block, and then removes them. These details are determined by a sigmoid function. For each number in the cell state Ct-1, it looks at the preceding state (ht-1) and the content input (Xt) and produces a number between 0 (Exclude) and 1 (Include).
- Output Gate: The output of the block is determined by the input and memory of the block. When the sigmoid function is used, it determines whether the 0 or 1 value should be allowed through. In addition, the tanh function determines which values are allowed to pass through 0, 1. As for the tanh function, it assigns weight to the provided values by evaluating their relevance on a scale of -1 to 1 and multiplying it with the sigmoid output.
The recurrent neural network uses long-short-term memory blocks to provide context for how inputs and outputs are handled in the software. This is mainly due to the fact the program uses a structure that is based on short-term memory processes in order to build a longer-term memory, so the unit is referred to as a long short-term memory block. There is an extensive use of these systems in natural language processing.
Unlike a recurrent neural network, where a single word or phoneme is evaluated in context of others in a string, where memories can assist in the filtering and categorization of certain types of data, a recurrent neural network utilizes a short-term memory block. Long – short term memory is a well-known and widely used idea in recurrent neural networks.
Also Read: 50 AI Terms You Should Know.
Long Short Term Memory (LSTM) Networks
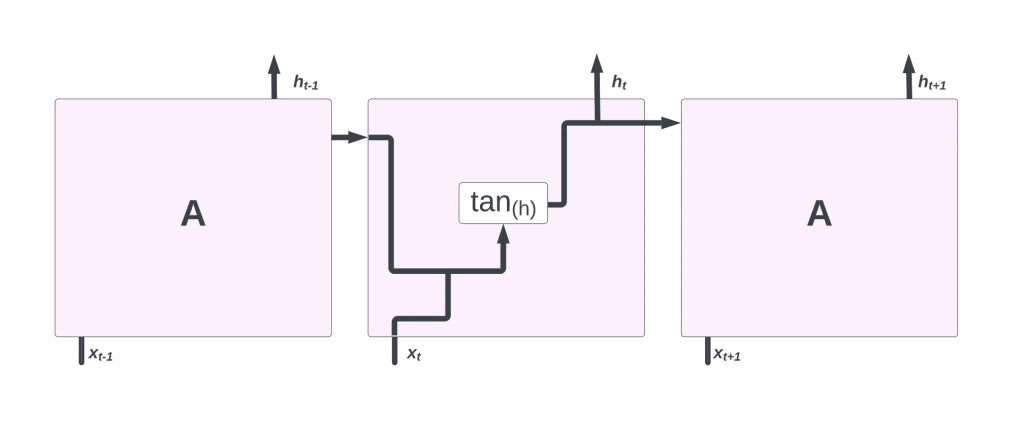
A recurrent neural network consists of a series of repeating modules. In traditional RNNs, this repeating module will have a simple structure such as a single tanh layer.
Recurrence occurs when the output of the current time step becomes the input for the next time step, which is referred to as Recurrent. During each step of the sequence, the model examines not just the current input, but also the previous inputs while comparing them to the current one.
A single layer exists in the repeating module of a conventional RNN:
In LSTMs, the repeating module is made up of four layers that interact with each other. In LSTMs, the memory cell state is represented by the horizontal line at the top of the diagram. Some aspects of the cell resemble those of a conveyor belt. There are only a few linear interactions along the entire chain. It’s easy for data to simply travel down it without being altered.
In the long – short term memory, information can be deleted or added to the cell state, which is carefully controlled by structures called gates. Gating allows information to pass through selectively. In addition to sigmoid neural nets, they feature point-wise multiplication.
Integers between 0 and 1 represent how much of each component can pass through the sigmoid layer. When the value is zero, “nothing” should be allowed through, while when the value is one, “everything” should be allowed through. An LSTM models contain three of these gates to protect and regulate the cell state.
Also Read: Smart Farming using AI and IoT.
LSTM Cycle
A long – short term memory cycle is divided into four steps, a forget gate is used in one of the steps to identify information that needs to be forgotten from a prior time step. Input gate and Tanh are used to gather new information for updating the state of the cell. This information is used to update the cell’s state. The output gates in addition to the squashing operation be a valuable source of information.
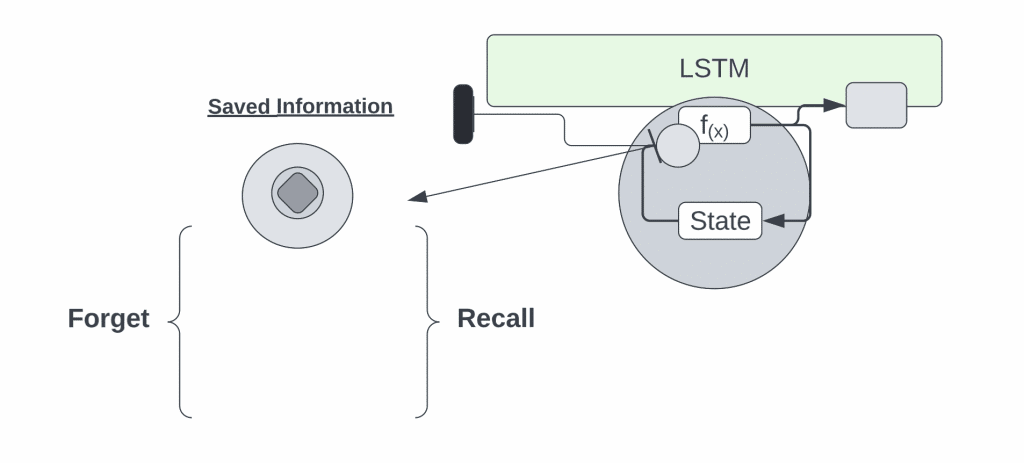
The output of an LSTM cell is received by a dense layer. In the output stage, a softmax activation function is applied after the dense layer.
Bidirectional LSTMs
Bidirectional LSTMs are an often discussed enhancement on LSTMs. A training sequence is presented forwards and backwards to two independent recurrent neural networks, both of which are coupled to a single output layer in Bidirectional Recurrent Neural Networks (BRNNs). As a result, BRNN is able to provide comprehensive, sequential knowledge about each of the points before and after each point in a particular sequence. Similarly, there is no need to specify a specific (task-dependent) time window or goal delay since the internet is free to use as much or as little of this context as it needs.
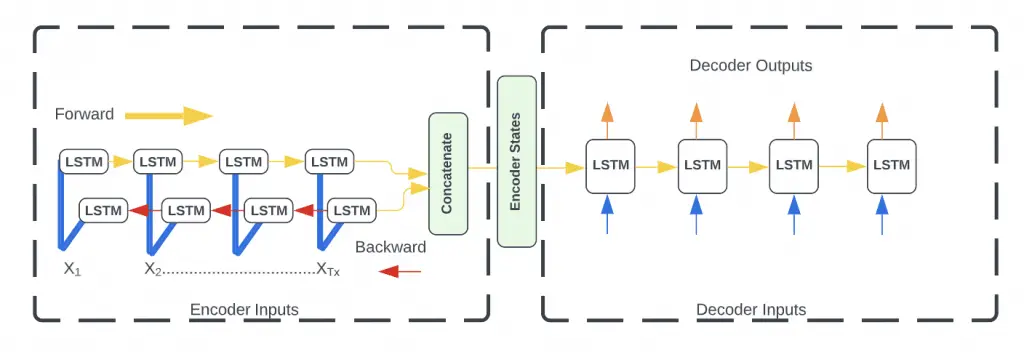
RNNs of the conventional type have the disadvantage of only being able to take advantage of the previous contexts. A bidirectional RNN (BRNN) accomplishes this by processing the data in both directions using two hidden layers that feed-forward information to the same output layer in both directions. By combining BRNN and LSTM, you get a bidirectional LSTM that allows you to access long-range context from both input directions.
Applications of LSTM
LSTM in Natural Language Processing and Text Generation
Long Short-Term Memory (LSTM) networks have had a significant impact in the field of Natural Language Processing (NLP) and Text Generation. LSTMs are a type of recurrent neural network (RNN) that can learn and remember over long sequences, effectively capturing the temporal dynamics of sequences and the context in text data. They excel in tasks that involve sequential data with long-term dependencies, like translation of a piece of text from one language to another or generating a sentence that follows the grammatical and semantic rules of a language.
A key characteristic of LSTMs that make them suited for these tasks is their unique cell state structure, which can maintain information in memory for extended periods. This structure mitigates the vanishing gradient problem, a challenge in traditional RNNs, where the network struggles to backpropagate errors through time and layers, particularly over many time steps. For example, when processing a lengthy sentence, traditional RNNs might lose the context of the initial words by the time they reach the end, but LSTMs maintain this information, proving crucial for understanding the semantic meaning of the sentence as a whole.
In Text Generation, LSTMs can be trained on a large corpus of text where they learn the probability distribution of the next character or word based on a sequence of previous characters or words. Once trained, they can generate new text that is stylistically and syntactically similar to the input text. This ability of LSTMs has been used in a wide range of applications, including automated story generation, chatbots, and even for scripting entire movie scripts. The impressive performance of LSTM models in these domains is a testament to their prowess in handling natural language and text generation tasks.
Applying LSTM for Time Series Prediction
Long Short-Term Memory (LSTM) networks are increasingly being used in the field of time series prediction, owing to their ability to learn long-term dependencies, which is a common characteristic of time series data. Time series prediction involves forecasting future values of a sequence, such as stock prices or weather conditions, based on historical data. LSTMs, with their unique memory cell structure, are well-equipped to maintain temporal dependencies in such data, effectively understanding patterns over time.
The LSTM network structure, with its unique gating mechanisms – the forget, input, and output gates – allows the model to selectively remember or forget information. When applied to time series prediction, this allows the network to give more weight to recent events while discarding irrelevant historical data. This selective memory makes LSTMs particularly effective in contexts where there is a significant amount of noise, or when the important events are sparsely distributed in time. For instance, in stock market prediction, LSTMs could focus on recent market trends and ignore older, less relevant data.
LSTMs also have an edge over traditional time series models such as ARIMA or exponential smoothing, as they can model complex nonlinear relationships and automatically learn temporal dependencies from the data. In addition, they can process multiple parallel time series (multivariate time series), a common occurrence in real-world data. The ability to handle such complexity has led to widespread application of LSTMs in financial forecasting, demand prediction in supply chain management, and even in predicting the spread of diseases in epidemiology. In each of these fields, the power of LSTM models to make accurate, reliable forecasts from complex time series data is being harnessed.
LSTM in Voice Recognition Systems
Long Short-Term Memory (LSTM) networks have brought about significant advancements in voice recognition systems, primarily due to their proficiency in processing sequential data and handling long-term dependencies. Voice recognition involves transforming spoken language into written text, which inherently requires the understanding of sequences – in this case, the sequence of spoken words. LSTM’s unique ability to remember past information for extended periods makes it particularly suited for such tasks, contributing to improved accuracy and reliability in voice recognition systems.
The LSTM model uses a series of gates to control the flow of information in and out of each cell, which makes it possible to maintain important context while filtering out noise or irrelevant details. This is crucial for voice recognition tasks where the context or meaning of words is often reliant on previous words or phrases spoken. For instance, in a voice-activated digital assistant, LSTM’s ability to retain long-term dependencies can help accurately capture user commands, even when they’re spoken in long, complex sentences.
LSTMs are less prone to the vanishing gradient problem compared to traditional Recurrent Neural Networks (RNNs), allowing them to learn from more extended sequences of data, which is often the case in speech. As a result, LSTMs have been extensively used in major speech recognition systems, such as Apple’s Siri, Google Assistant, and Amazon Alexa. By leveraging the unique capabilities of LSTM, these systems can process natural language more effectively, resulting in more accurate transcription and improved user experiences.
Use of LSTM in Music Composition and Generation
Long Short-Term Memory (LSTM) networks have revolutionized the field of music composition and generation by providing the capability to generate original, creative musical pieces. Music, fundamentally, is sequential data, with each note or chord bearing relevance to its predecessors and successors. The inherent property of LSTMs to maintain and manipulate sequential data makes them a fitting choice for music generation tasks. They can effectively capture and reproduce the structure of music, taking into account not just the notes, but also their timing, duration, and intensity.
When trained on a dataset of music, an LSTM network can learn the patterns and dependencies that define the musical style of that dataset. For instance, when trained on a set of classical piano pieces, the network could learn the characteristic harmonies, chord progressions, and melodies of that style. It can then generate new compositions that follow similar patterns, essentially “composing” new music in the style of the training data. The LSTM’s ability to capture long-term dependencies ensures that the generated music pieces maintain coherence and musicality over a long duration.
LSTMs are also used in interactive music systems, allowing users to create music collaboratively with the AI. They can generate continuations of a musical piece given by the user, or even adapt the generated music based on user feedback. LSTMs’ use in music generation not only opens up new avenues for creativity but also provides a valuable tool for studying and understanding music theory and composition.
LSTM for Video Processing and Activity Recognition
Long Short-Term Memory (LSTM) networks have proven to be highly effective in video processing and activity recognition tasks. Video data is inherently sequential and temporal, with each frame of a video being related to the frames before and after it. This property aligns with LSTM’s capability to handle sequences and remember past information, making them ideal for these tasks. LSTMs can learn to identify and predict patterns in sequential data over time, making them highly useful for recognizing activities within videos where temporal dependencies and sequence order are crucial.
In video processing tasks, LSTM networks are typically combined with convolutional neural networks (CNNs). CNNs are used to extract spatial features from each frame, while LSTMs handle the temporal dimension, learning the sequence of actions over time. For example, in an activity recognition task, the CNN could extract features like shapes and textures from individual frames, while the LSTM would learn the sequence and timing of these features to identify a specific activity, such as a person running or a car driving. This combined CNN-LSTM approach is very effective for video processing tasks, allowing for accurate recognition of complex activities that involve a series of actions over time.
LSTM has a number of other well-known applications as well, including:
- Robot control
- Time series prediction
- Speech recognition
- Rhythm learning
- Music composition
- Handwriting recognition
- Human action recognition
- Sign language translation
- Time series anomaly detection
- Several prediction tasks in the area of business process management
- Prediction in medical care pathways
- Semantic parsing
- Object co-segmentation
- Airport passenger management
- Short-term traffic forecast
- Drug design
- Market Prediction
Conclusion
Long Short Term Memory (LSTM) networks are a type of recurrent neural network capable of learning order dependence in sequence prediction problems. A behavior required in complex problem domains like machine translation, speech recognition, and more. LSTMs are a viable answer for problems involving sequences and time series. Problems in data science can be resolved using LSTM models.
Even simple models require a lot of time and system resources to train due to the difficulty of training them. The hardware limitations are the only thing holding this back. In the traditional RNN, the problem is that they are only able to use the contexts of the past. These BRNNs (Bidirectional RNNs) are able to do this by processing data in both directions at the same time.

References
Brownlee, Jason. Long Short-Term Memory Networks With Python: Develop Sequence Prediction Models with Deep Learning. Machine Learning Mastery, 2017.
Mangla, Monika, et al. Handbook of Research on Machine Learning: Foundations and Applications. CRC Press, 2022.
partheepan, Ravinthiran. Toxic Comment Classification Using LSTM, GRU and Neural Network. RAVINTHIRAN PARTHEEPAN, 2021.