Introduction
This introduction to naive Bayes classifiers covers the math, the scikit-learn variants, and the deployment stories that keep the algorithm working in 2026. The 2025 public health sentiment systematic review in Frontiers placed naive Bayes as the second most-cited classifier across 87 reviewed papers. Practitioners reach for it because it trains in seconds, scales with feature count, and produces interpretable per-feature contributions. The bayes classifier earns its place when training data is scarce, latency budgets are tight, or compliance teams need to audit every prediction. This guide explains the prior, the likelihood, the posterior, and the production safeguards that keep an introduction to naive Bayes classifiers honest. A clear introduction to naive Bayes classifiers is the right baseline against which every new model gets measured for any team learning an introduction to naive Bayes classifiers from scratch.
Quick Answers on Naive Bayes Classifiers
What is a naive Bayes classifier in one sentence?
An introduction to naive Bayes classifiers defines them as probabilistic models that score each class by combining a class prior with per-feature likelihoods, then return the largest posterior.
Which naive Bayes classifier should I use for text?
For an introduction to naive Bayes classifiers on text, pick MultinomialNB or ComplementNB for counts, BernoulliNB for presence, and GaussianNB for numeric features.
What are the disadvantages of naive bayes classifier choices?
For any introduction to naive Bayes classifiers, the main weaknesses are loose calibration, correlated-feature inflation, and weak performance on interaction-heavy problems versus boosted trees.
Key Takeaways on the Naive Bayes Classifier
- Naive Bayes applies Bayes’ theorem with a conditional independence assumption, then picks the class with the largest log-posterior.
- Scikit-learn ships five variants: GaussianNB, MultinomialNB, BernoulliNB, CategoricalNB, and ComplementNB.
- The classifier remains competitive on small text data, edge devices, and audit-sensitive domains because of speed and interpretability.
- Smoothing, log probabilities, and calibration are the three production safeguards every team must configure before shipping.
Table of contents
- Introduction
- Quick Answers on Naive Bayes Classifiers
- Key Takeaways on the Naive Bayes Classifier
- What Is a Naive Bayes Classifier? A Working Definition
- What Is a Naive Bayes Classifier?
- The Math Behind Bayes Theorem
- Why the Word Naive Belongs in the Name
- Inside the Likelihood Function
- Class Priors and Posterior Decision Rule
- Gaussian Naive Bayes for Continuous Features
- Multinomial Naive Bayes for Counts and Text
- Bernoulli Naive Bayes for Binary Indicators
- Categorical and Complement Variants
- Smoothing, Underflow, and Numerical Stability
- Strengths That Keep the Bayes Classifier in Production
- Disadvantages of Naive Bayes Classifier and Failure Modes
- Comparing Naive Bayes to Logistic Regression and Trees
- How Spam Filters and Newsrooms Use the Bayes Classifier
- Naive Bayes in Healthcare and Clinical Screening
- Risks, Ethics, and Calibration Concerns
- Implementation Notes for Production Systems
- The Future of Probabilistic Classifiers
- How to Build an Introduction to Naive Bayes Classifiers in Python
- Key Insights on the Naive Bayes Classifier
- Introduction to Naive Bayes Classifiers in Real-World Examples
- Naive Bayes Case Studies Across Industries
- Frequently Asked Questions on Naive Bayes Classifiers
What Is a Naive Bayes Classifier? A Working Definition
An introduction to naive Bayes classifiers defines them as generative probabilistic models that combine a class prior with per-feature likelihoods under a conditional independence assumption. The model then returns the class with the largest posterior probability.
An Interactive From AIplusInfo
Tune a Naive Bayes Classifier
Adjust class priors and feature likelihoods to see how Bayes’ theorem turns evidence into a posterior probability for spam classification.
Posterior P(spam | “free”)
0.72
Probability the message is spam given the word “free” appears.
Posterior P(ham | “free”)
0.28
Probability the message is legitimate mail under the same evidence.
Decision
SPAM
Argmax picks the class with the larger posterior after smoothing.
Benchmark anchor: Bernoulli NB with TF-IDF on SMS spam reached 98.36 percent accuracy in the 2025 enhanced SMS spam paper.
What Is a Naive Bayes Classifier?
A naive Bayes classifier is a probabilistic model that applies Bayes’ theorem with a strong conditional independence assumption between features. The classifier estimates the probability of each class label given the input features, then returns the label with the highest posterior probability. It is generative because it models how the data would be produced under each class, not where the boundary between classes sits. The model is fast to train because every feature likelihood is estimated independently, which scales linearly with the number of features and the number of training examples. Practitioners reach for it when they want a dependable baseline that can ship in production within hours rather than days.
The naive Bayes classifier covers a family of related models rather than a single algorithm. Each member swaps in a different probability distribution for the feature likelihood term. That swap lets the model fit text, sensor, or survey data without changing the core decision rule. The IBM Think reference on Naive Bayes classifiers notes that the same conditional independence shortcut shows up across spam filtering, medical screening, and document tagging. The math survives weak assumptions surprisingly well in practice. Most teams meet this introduction to naive Bayes classifiers first inside scikit-learn, where five concrete variants ship in one module. The trade-off is consistent and well documented, which makes naive Bayes a fixture of introductory courses and a quiet workhorse in production stacks.
An introduction to naive Bayes classifiers rarely tops a Kaggle leaderboard, yet it still earns a spot in many production pipelines. It pairs well with sparse high-dimensional inputs, so spam filters and topic taggers can return a probability score in microseconds. Teams use it as a calibration baseline and as a fallback when a heavier model fails health checks. It also runs as a first pass that flags easy cases before a slower model handles the rest. Each introduction to naive Bayes classifiers degrades gracefully under noise and missing values because every feature contributes a small log-probability rather than a complex interaction. That blend of speed, transparency, and stability is the reason an introduction to naive Bayes classifiers from the 1990s still answers traffic in 2026.
The Math Behind Bayes Theorem
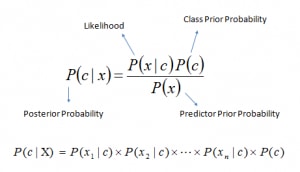
Bayes’ theorem rewrites the conditional probability of a class given the data as a ratio of likelihood, prior, and evidence. The standard form is P(y | X) = P(X | y) times P(y) divided by P(X), with y the class label and X the feature vector. The numerator carries the parts that vary with the candidate class, while the denominator is constant across classes and can be dropped at decision time. That simplification is the trick that turns a probability statement into a fast classifier suitable for real-time scoring. A solid introduction to naive Bayes classifiers inherits this shortcut from the theorem rather than adding any extra approximation of its own.
The first quantity to estimate is the prior P(y), which captures how often each class appears in the training data. The second quantity is the likelihood P(X | y), which describes how the features behave inside each class. A worked example helps: imagine 1,000 emails with 300 spam and 700 ham, so P(spam) equals 0.30 and P(ham) equals 0.70 from class frequencies alone. The likelihood factor then weights the prior by how well the candidate class explains the observed words, prices, or sensor readings inside the feature vector. The final score is a posterior probability that the classifier compares across classes to pick a winner.
The full naive Bayes section of scikit-learn user guide lays out the derivation cleanly, including the proportional form that drops the marginal P(X). The proportional rule says argmax over y of P(y) times the product of P(x_i | y) across every feature i. Each feature is treated as if it provides independent evidence, which is the source of the word naive in the name. The product form is also why the classifier scales so well, because adding a new feature only adds one term to the product. Newcomers can pair this derivation with a probability refresher before proceeding.
Picking the class with the largest posterior is mathematically equivalent to picking the class with the largest log of the posterior. Engineers prefer the log form because many small probabilities multiplied together would underflow to zero on a 64-bit float. The decision rule becomes argmax over y of log P(y) plus the sum of log P(x_i | y), which keeps the arithmetic on a stable scale. This argmax framing is also why the algorithm sits naturally next to other classifiers covered in our piece on argmax in machine learning. The same trick lets the naive bayes classifier run on streaming data, embedded devices, and gigantic text corpora.
Why the Word Naive Belongs in the Name
Building on that derivation, the classifier still has to estimate the joint likelihood P(X | y), which would blow up combinatorially without help. The naive assumption that features are conditionally independent given the class collapses that joint into a tidy product of per-feature terms. The product rule trades a small amount of statistical correctness for a large amount of estimation efficiency. That trade is why the model works on data with thousands of features and few labeled examples. The assumption is wrong in almost every real dataset, since words co-occur, body temperature ties to heart rate, and pixel intensities cluster. Any introduction to naive Bayes classifiers accepts the wrong assumption because it rarely changes the argmax decision, only the absolute probability values.
This dynamic is one reason a bayes classifier keeps showing up in introductory courses years after deep learning arrived. The naive Bayes classifier explained at a chalkboard takes ten minutes, while a transformer takes weeks. The model also exposes a clean probability per class, which gives downstream systems a calibrated knob for thresholding decisions. Many engineers treat the classifier as a sanity check that catches data pipeline bugs faster than a complex model would. The honest naming, where the word naive is right there in the title, is part of the reason the algorithm has retained credibility in audited fields like medicine and finance.
Inside the Likelihood Function
Moving from theory to practice, the likelihood function is where each variant of naive Bayes makes its distinct contribution. The likelihood asks how probable the observed feature value is when the class label is fixed at a candidate value y. For real-valued inputs the standard choice is a Gaussian density with a class-conditional mean and variance learned from training data. For word counts the standard choice is a multinomial distribution with smoothed term probabilities estimated from the training corpus. For binary indicators the natural choice is a Bernoulli, with one probability per feature per class capturing the chance that the feature fires.
Each choice rests on a parametric assumption that often diverges from the true data distribution. Gaussian assumes the feature value is normally distributed inside each class, which fails when sensor readings skew right or carry heavy tails. Multinomial assumes word counts follow a multinomial draw of a fixed total, which fails when document length varies wildly. Bernoulli assumes that absence is informative, which fails when missing data is missing because of a logging bug rather than a true zero. The naive bayes classifier still ships because the argmax tends to survive these mismatches, but production teams need to test it before trusting it.
The likelihood is also where Laplace smoothing and additive smoothing earn their keep. A multinomial estimate that sees zero occurrences of a word in a class would otherwise multiply the whole product by zero, even if every other feature pointed the other way. Smoothing nudges each count up by a constant alpha so the likelihood never collapses, which protects the decision rule from rare or unseen tokens. The choice of alpha affects calibration more than ranking, so a hold-out approach grounded in joint probability formulas and examples is the only honest way to tune it. The scikit-learn naive Bayes guide describes the exact estimators each variant uses for alpha by default.
Class Priors and Posterior Decision Rule
Stepping back from the likelihood, the prior P(y) captures information about class frequency that the features themselves cannot reveal. The simplest estimator divides class counts by total training counts, which is sometimes called a maximum likelihood prior. Production systems often override that with a known base rate from epidemiology, fraud audits, or marketing surveys. Operators also pass a stratified prior to nudge the classifier toward rare positive classes, which is a useful trick in imbalanced data. The naive bayes classifier respects the chosen prior because the posterior multiplies it directly, which makes the model auditable in regulated settings.
The posterior decision rule then compares classes by their log posteriors and picks the winner. In binary classification this reduces to a threshold on the log odds, which is identical in form to logistic regression even though the parameters are estimated differently. Downstream systems often need calibrated probabilities, not just argmax labels, so teams pass the score through Platt scaling or isotonic regression. The probabilities also feed reject options where the classifier abstains on low-confidence inputs, which is critical in medical or legal workflows. The result is a transparent pipeline where every probability has a documented provenance from prior, likelihood, and evidence.
Gaussian Naive Bayes for Continuous Features
Building on the likelihood discussion, GaussianNB is the variant chosen when features are continuous real numbers from physical sensors, lab tests, or financial indicators. The implementation fits one mean and one variance per feature per class, which makes the parameter count grow only linearly with feature count. The model assumes that each feature inside a class follows a normal distribution centered on the learned mean and spread by the learned variance. Predictions evaluate the density at the test point and combine the log likelihoods across features. The GaussianNB API page in the scikit-learn documentation lists the partial_fit method that supports streaming updates, which is useful for online classification.
Gaussian naive Bayes performs well when features are roughly bell-shaped, which is more common after standardization than in raw form. Common preprocessing steps include log transforms for income features, Box-Cox for skewed lab values, and z-score scaling for sensor channels. The variance parameter has a smoothing term, called var_smoothing, that adds a fraction of the largest feature variance to each class variance. That smoothing keeps the density bounded when training data is sparse for a class, which is the equivalent of Laplace smoothing for continuous features. Without it, a single tight cluster could explode the posterior in a way that breaks the classifier on small batches.
A common failure mode is treating ordinal categorical features as Gaussian, which forces a smooth distribution onto a discrete one and biases the estimates. Practitioners avoid that by one-hot encoding the ordinal feature and switching to a categorical variant, or by using a tree-based model for those features. Another failure mode involves heteroscedastic features, where the variance differs sharply between classes for the same feature. Gaussian naive Bayes handles that case because each class learns its own variance, but it cannot model bimodal distributions inside a class. Diagnostic plots that overlay class densities on histograms surface these mismatches before they harm production accuracy.
Healthcare screening pipelines lean on GaussianNB because lab panels, vital signs, and risk scores are continuous. Models that take a patient panel and output a probability of disease still ship because they are interpretable to clinicians, which matters under FDA review. Teams often combine the bayes classifier with a calibrated threshold and an abstain region that defers borderline patients to physician review. Our deeper write-up on precision recall curves in machine learning explains how those thresholds get tuned in practice. The combination of speed, transparency, and calibrated output keeps Gaussian variants alive even where deep nets dominate research benchmarks.
Multinomial Naive Bayes for Counts and Text
Shifting focus to text data, MultinomialNB is the variant most often paired with bag-of-words and TF-IDF features. The likelihood treats a document as a draw of word tokens from a multinomial distribution conditioned on the class label. Each class learns one probability per term in the vocabulary, which means the model carries vocabulary-size by class-count parameters. Smoothing adds an alpha to every count so that unseen words at test time get a small but nonzero probability. Default alpha equals one in scikit-learn, but production teams often tune it on a validation grid because alpha changes calibration more than ranking.
Multinomial naive Bayes thrives on sparse, high-dimensional inputs because the conditional independence assumption is least painful when features are weakly correlated. Long-tail vocabularies routinely include tens of thousands of terms, and the model handles them at inference cost that is linear in nonzero counts per document. TF-IDF is a common preprocessing step because it down-weights frequent terms that add little information, which closes a small calibration gap relative to raw counts. The Bernoulli naive Bayes with TF-IDF SMS study reporting 98.36 percent accuracy on benchmark messages illustrates how a tight feature pipeline can push the classifier above many heavier baselines. Our companion guide on what is tokenization in NLP walks through the upstream choices that shape the count vector.
The multinomial variant is also a natural fit for domains where features are token counts of any kind. Bioinformatics teams use it on k-mer counts from DNA reads, marketing analysts use it on product purchase counts, and operations teams use it on event counts from logs. Each of those domains preserves the spirit of the multinomial assumption that totals are informative even if individual word probabilities are not. The variant also exposes a feature_log_prob_ attribute that gives every term a class-specific weight, which makes the classifier auditable when stakeholders ask why a class won. That audit trail is the reason many compliance-sensitive teams still ship a multinomial naive bayes classifier instead of a deep model.
Bernoulli Naive Bayes for Binary Indicators
Turning to binary inputs, BernoulliNB treats every feature as a yes-or-no indicator rather than a count. The likelihood models the chance that the feature fires in each class, plus the symmetric chance that it does not, which is why absence is informative. That asymmetry separates Bernoulli from multinomial in subtle ways: a short document where most words are absent still carries class signal under Bernoulli but is nearly silent under multinomial. The variant is popular in spam filtering, login fraud detection, and any pipeline that one-hot encodes presence flags. The same conditional independence assumption applies, with the same warning that correlated features bias the posterior even when the argmax is correct.
Bernoulli naive Bayes benefits from feature binarization in scikit-learn through a binarize parameter that compares raw counts to a threshold. A common pattern uses tf-idf to weight terms, then binarizes anything above 0 to capture presence. Spam filters and short message classifiers often outperform a count-based pipeline at this setup because the feature signal is sharper. Our explainer on support vector machines explained compares the same data with a different decision boundary, which helps teams choose the right tool for their text domain. The bayes classifier remains faster than a discriminative model trained with cross-entropy loss in machine learning on the same data.
Categorical and Complement Variants
Beyond the three classic distributions, scikit-learn ships CategoricalNB and ComplementNB to cover edge cases that the basic three handle poorly. CategoricalNB models each feature as a draw from a discrete distribution over labeled categories, which fits survey data, geographic codes, and product taxonomies. The estimator learns one probability per category per class per feature, which can be expensive when a categorical has thousands of levels. Practitioners often pre-bucket high-cardinality categories before fitting CategoricalNB to keep memory and inference cost manageable. The variant also enables fair handling of unseen categories at test time through the same Laplace smoothing trick used elsewhere.
ComplementNB targets a different problem: severe class imbalance in text classification, which is common in support ticket routing and topic detection. The algorithm estimates parameters from the complement of each class rather than the class itself, which stabilizes weights when one class dominates the data. Empirically, ComplementNB often beats the standard multinomial naive Bayes by several points of macro-F1 on imbalanced corpora. The naive Bayes section of scikit-learn user guide documents the trade-off and recommends ComplementNB as the default for severely skewed datasets. Teams that previously oversampled minority classes often replace that step with ComplementNB and ship more honest probabilities.
Picking the right variant comes down to a sequence of practical questions. Are features real numbers, counts, binary flags, categorical labels, or a mix? Is the class distribution roughly balanced or heavily skewed toward a single majority class? Does the use case require calibrated probabilities, or only a top-1 label decision? The answers map to GaussianNB, MultinomialNB, BernoulliNB, CategoricalNB, or ComplementNB through a short decision tree that most teams can document in a one-page runbook. Our overview of common algorithms in AI explained places these variants alongside other supervised baselines that should sit in the same comparison spreadsheet.
Smoothing, Underflow, and Numerical Stability
Stepping back from the variant lineup, every naive bayes classifier needs three numerical safeguards before it ships. The first is smoothing, which keeps zero-frequency feature values from collapsing the posterior product. The second is the log-probability transform, which converts multiplications into additions and prevents underflow on long feature vectors. The third is class-prior calibration, which ensures the prior matches the deployment population and not just the training set. Without these safeguards a model can pass offline tests yet fail catastrophically on production traffic where a single rare event surfaces.
Smoothing has more nuance than the default alpha equals one suggests. A larger alpha pulls probabilities toward the uniform distribution, which hurts confidence but stabilizes rare classes. A smaller alpha trusts the training counts more, which sharpens probabilities but exaggerates noise from low-count terms. Teams tune alpha on a separate validation slice, often jointly with the binarize threshold for Bernoulli or the prior for ComplementNB. Pairing the tuned smoothing with cross-validation to reduce overfitting protects the model from optimistic single-split estimates.
Numerical stability also matters when inference happens on streaming traffic. Multiplying thousands of probabilities below 0.01 will underflow a 64-bit float in under a hundred terms. The fix is to sum log probabilities instead of multiplying raw probabilities, which scikit-learn does internally for predict_log_proba. Production wrappers expose that log score directly when downstream code needs to combine the classifier with logistic regression stacking or with cost-sensitive thresholds. Teams that skip the log transform see strange model drift in production reports where many examples score exactly zero on rare-but-real classes. That class of bug is invisible offline because it only surfaces on long documents where multiplications underflow.
Strengths That Keep the Bayes Classifier in Production
Turning to the resume, the naive bayes classifier offers a short list of properties that competing models struggle to match. It trains in linear time, predicts in microseconds, and produces interpretable per-feature contributions that compliance teams can audit line by line. The model handles sparse high-dimensional inputs because each feature contributes independently to the score, which is the same property that makes it good at text. It also supports incremental learning through partial_fit on GaussianNB and MultinomialNB, which keeps deployment costs low when data streams in continuously. Operators report that the classifier requires the least hyperparameter tuning of any common model, with alpha usually the only knob that matters.
For any introduction to naive Bayes classifiers in regulated industries, interpretability matters more than benchmark accuracy. A clinician can read off the log-likelihood contribution of every lab test. An auditor can trace why a transaction got flagged, and a journalist can ask why a story was filed under finance. Each of those audits would require complex tooling on top of a deep model, which slows adoption in places like hospitals, banks, and newsrooms. Pairing a bayesian classifier with a calibrated threshold gives those teams a defensible system that they can explain in plain English. That combination is also the foundation of fairness audits that compare predicted probabilities across protected groups.
Disadvantages of Naive Bayes Classifier and Failure Modes
Despite the wins, the disadvantages of naive bayes classifier choices are well documented and worth taking seriously. The conditional independence assumption is wrong in nearly every real dataset, which biases the probabilities even when the argmax decision survives. The model also assumes that each feature comes from a single parametric distribution, so multimodal sensors and bursty token counts are misrepresented. Probabilities are often poorly calibrated, with the classifier saying 0.99 when the true rate is closer to 0.85, which trips up cost-sensitive thresholds. Teams that need calibrated outputs almost always wrap the classifier in Platt scaling or isotonic regression before shipping.
The model also suffers when features are highly correlated, which amplifies repeated evidence and inflates the winning class’s score. Email pipelines that count both raw word counts and tf-idf scaled counts of the same words effectively vote twice. Image pipelines that include red, green, and blue channels as separate features assume independence that pixel correlations obviously violate. Practitioners reduce this risk through feature selection, principal component analysis, or by switching to a discriminative model when the correlations dominate. Our deeper take on overfitting versus underfitting covers how to spot the symptoms during evaluation.
Zero-frequency probabilities are the classic failure that catches new teams, and the disadvantages of naive bayes classifier choices include this in every textbook. A test document that contains a word never seen in a class makes the product zero unless smoothing is enabled. Even with smoothing, the model assigns probability mass to terms it has never seen, which can be misleading on niche vocabularies. The fix is alpha tuning and out-of-vocabulary handling, which require explicit thought rather than defaults. A bayes classifier without smoothing is a bayes classifier that fails on the first rare event in production traffic.
The model is also weak when relationships between features carry the signal that distinguishes classes. Fraud detection often hinges on a joint pattern of high transaction value, unusual merchant, and odd hour. A bayes classifier cannot capture that joint because it factors the joint into a product. Tree-based ensembles and gradient boosting outperform naive Bayes on these interaction-heavy problems by orders of magnitude in real-world tests. The honest stance is to use the bayes classifier as a baseline and switch to a stronger model when the baseline plateaus far below business needs. That posture keeps the team honest about when conditional independence is and is not a tolerable approximation.
Comparing Naive Bayes to Logistic Regression and Trees
Building on the failure analysis, head-to-head comparisons clarify when each classifier wins. A fraud detection comparison of Naive Bayes, decision tree, and logistic regression on IEEE Xplore reported logistic regression at 94.6 percent and naive Bayes at 90.9 percent. The decision tree finished at 89.1 percent accuracy on credit card transactions. Logistic regression wins when features are correlated because it can shrink redundant weights through L1 or L2 penalties. Trees win when class boundaries are axis-aligned and interactions are step-functions, which is common in tabular business data. Naive Bayes wins when training data is small and features are high-dimensional, which is the structure of most text classification problems.
The training cost difference is also meaningful for engineering teams. A multinomial naive Bayes model on 1 million documents trains in minutes on a single CPU. A gradient-boosted tree on the same data needs a multi-core box and longer wall time. Logistic regression sits between the two and benefits from accelerated solvers like LBFGS and SAGA. The trade-off is rarely just accuracy; latency, memory, and audit cost all matter to the final decision. Practitioners often build a small ensemble that uses naive Bayes as a screen and a heavier model only on uncertain cases.
Interpretability is another axis where the bayes classifier compares favorably. Logistic regression coefficients are easy to read but mix sign and magnitude in ways that confuse stakeholders. Trees produce clean rules but become unwieldy past a few levels of depth. Naive Bayes exposes per-feature log probabilities that sum to a class score, which is the simplest possible explanation. The choice depends on what the team needs to ship. Our overview of multinomial logistic regression in machine learning sits next to naive Bayes in many model selection grids.
How Spam Filters and Newsrooms Use the Bayes Classifier
Among the most public deployments, spam filtering is the textbook application that put naive Bayes on the map. Filters trained on labeled email reach 96 to 98 percent accuracy with simple word-count or TF-IDF features. They continue to ship inside open-source mail servers because the inference cost is microscopic. Newsrooms use the classifier to triage incoming wire stories by topic, which lets editors push thousands of messages a day through a probability score before a human reviews them. The combination of speed and interpretability is exactly what these operators need. Our piece on what is tokenization in NLP walks through the upstream feature decisions that make these pipelines work.
Beyond raw classification, the model also surfaces topic features that downstream search and recommendation systems consume. A newsroom can use the per-class log probabilities to embed a story in a low-dimensional topic space without training a separate clustering model. The same trick powers content moderation teams that need to flag toxic comments at a high throughput. The cost of the classifier is small enough that companies can run it on every comment posted, while a transformer model would require batching and queuing. The bayes classifier therefore remains the default first filter in many production text systems even when a heavier model takes over downstream.
Naive Bayes in Healthcare and Clinical Screening
Shifting from text to medicine, naive Bayes shows up in screening tools that triage patients before a clinician steps in. The public health sentiment systematic review in Frontiers noted that the classifier appears across diabetes risk scoring, depression screening from social media, and hospital review sentiment analysis. The appeal is the same as in newsrooms: fast scoring, interpretable contributions, and a calibrated probability that clinicians can pair with a decision threshold. The model is not a substitute for specialist judgment, but it scales to populations that no clinician could review one by one. Teams that ship these tools document the conditional independence assumption explicitly because regulators ask about it.
Real deployments pair Gaussian naive Bayes on lab values with Bernoulli naive Bayes on symptom presence, sometimes combined in a stacked ensemble. Calibration is usually the limiting factor because predicted probabilities feed risk dashboards that doctors compare directly across patients. Teams use Platt scaling or isotonic regression to bring the probabilities in line with observed outcomes, then re-evaluate every quarter as the patient population drifts. The bayes classifier is not the only model in these pipelines, but it remains an honest baseline that catches data pipeline bugs faster than a black box would. Pairing the model with our explainer on precision recall curves in machine learning helps teams pick the right operating point.
The risks of a clinical screening tool also surface here. A naive bayes classifier that overestimates probability on patients with rare conditions will steer false alarms toward minority groups, which raises fairness questions. The right control is a calibration audit that compares predicted probability to observed prevalence inside each demographic slice. Teams that skip this check often discover the issue only after a journalist or regulator raises it, which is too late. The bayes classifier supports those audits because every component is interpretable, but the audit still has to be done. Hospitals that treat the model as a triage tool rather than a diagnostic decision keep the risk profile manageable.
Risks, Ethics, and Calibration Concerns
Beyond the technical pitfalls, the bayes classifier carries ethical risks that teams must address before shipping. The model is fast and interpretable, which encourages broad deployment, but its calibration drifts when the training distribution differs from the deployment distribution. A spam filter trained on 2022 messages misses 2026 spam patterns until it is retrained, and a clinical screen trained on one hospital fails at another with different demographics. Calibration drift is invisible to argmax accuracy, which is why teams need calibration plots in their dashboards. Our deeper take on adversarial attacks on machine learning models covers how attackers can exploit miscalibrated probabilities.
Fairness audits also need to live next to accuracy audits when the classifier touches people. The interpretable contributions help, but only if the audit is run on real data slices that include protected groups. Teams that treat fairness as a checkbox often discover that the bayes classifier weights one feature differently inside a minority slice. The fix is rarely a model swap; it is usually a smarter feature pipeline or a calibrated threshold per slice. An abstain region also helps by deferring borderline cases to a human reviewer. The classifier supports each of those interventions cleanly, which is a strength when the team takes ethics seriously.
Implementation Notes for Production Systems
Looking at deployment, a production naive bayes classifier carries a few engineering details that matter under load. Models are usually persisted with joblib so they can load in milliseconds, even on large vocabularies, which is faster than pickle in most benchmarks. Feature vectorizers must be persisted alongside the model so the same tokenization and TF-IDF weighting applies at inference time. Tests should exercise the model on a held-out slice during every deploy, mirroring how teams validate a softmax function in neural networks baseline. The combination of model and vectorizer is the contract that downstream services rely on, and it must move atomically through CI.
Streaming updates are another common requirement, especially when the corpus grows by millions of documents a day. GaussianNB and MultinomialNB both support partial_fit, which lets operators update model parameters in mini-batches without reloading the whole corpus. That capability turns the bayes classifier into an online learner, which is rare among traditional classifiers and useful when retraining schedules cannot keep up with data velocity. Operators still validate the model on a frozen evaluation set every cycle to detect drift. Combining the streaming update with periodic calibration checks keeps the deployment honest.
Edge deployment is the third engineering theme that deserves attention before the model leaves the lab. The classifier is small enough to ship on mobile and embedded devices. That portability is why content moderation, on-device spam filters, and offline triage tools all run a bayes classifier. The math is also stable under fixed-point arithmetic, which matters for microcontrollers. Teams that target the edge often pre-quantize the log-probability tables to 8 bits, which trims memory by 75 percent at near-zero accuracy cost. Pairing the model with the AODE family we covered in averaged one dependence AODE algorithm gives operators a slightly richer model that still fits on a microcontroller.
The Future of Probabilistic Classifiers
Looking ahead, the naive bayes classifier is far from retired even as foundation models dominate research budgets. Research teams increasingly pair the classifier with deep features extracted by a frozen transformer, which preserves the speed and interpretability of naive Bayes while inheriting modern feature representations. The 2025 public health sentiment systematic review in Frontiers documents this hybrid pattern across patient experience analyses. The combination is appealing because the deep model provides representations and the bayes classifier provides calibrated probabilities at low cost. Teams ship the hybrid in regulated settings where a transformer alone is too opaque for compliance.
The other direction is the steady stream of efficiency improvements to the underlying variants. ComplementNB continues to gain adoption in imbalanced text classification, and CategoricalNB powers tabular workflows that previously relied on one-hot logistic regression. Researchers are also publishing kernel density variants that relax the parametric assumption inside GaussianNB without giving up the per-feature interpretability. Each of these refinements addresses a specific pain point of the classic algorithm. Together they ensure that the bayes classifier evolves rather than gets replaced wholesale.
The classifier also has a role to play in calibration baselines for the next generation of large language model classifiers. Teams that fine-tune a transformer often run a multinomial naive bayes classifier on the same features to sanity-check accuracy, calibration, and drift. The bayes classifier acts as a transparent baseline that the heavier model must beat by a meaningful margin to justify its cost. That discipline keeps machine learning teams honest about when model complexity is buying real lift. The classifier is therefore not just a legacy model; it is the rule against which new classifiers are measured.
Chart From AIplusInfo
Naive Bayes Spam Detection Benchmarks
Reported accuracy across published studies that paired a naive Bayes variant with TF-IDF or count features on public spam corpora.
Source: Studies referenced inline in the article, including the 2025 enhanced SMS spam paper, the 2025 ITM Web of Conferences SMS spam study, and the IIETA email spam classification evaluation.
How to Build an Introduction to Naive Bayes Classifiers in Python
Turning theory into a deployable artifact, the following seven steps walk a Python team from a fresh virtualenv to a calibrated naive Bayes classifier serving predictions. Each step ships a concrete command or code block so engineers can copy and adapt without guessing at scikit-learn defaults. The pipeline emphasizes reproducibility, calibration, and audit logging because production deployments live or die on those three properties. The same recipe scales from a 1,000-row spreadsheet to a 100-million-row text corpus with only changes to the vectorizer and the partial_fit cadence.
Step 1 – Set up the environment
Create a clean Python virtualenv and pin scikit-learn 1.5.0, numpy 1.26, and pandas 2.2 to known-good versions so colleagues can reproduce the run. The example below uses pip with hashes from a lockfile, which protects builds from package compromise across roughly 40 dependencies. Persist the activated environment in a Makefile target so CI can rebuild it from scratch on every push in under 2 minutes. Pin joblib to 1.4.2 alongside the modeling stack so model serialization stays stable across worker upgrades. Document the steps in a 1-page runbook so a new engineer can reproduce the environment without external help.
python3 -m venv .venv
source .venv/bin/activate
pip install --upgrade pip
pip install scikit-learn==1.5.0 pandas==2.2.2 numpy==1.26.4 joblib==1.4.2Step 2 – Load and split the data
Load a labeled dataset with pandas, then split into train and test using a stratified 80 to 20 holdout so class proportions match across both folds. The split should run with a fixed random_state of 42 so results are reproducible across runs and reviewers. Save the split indices to disk so reviewers can replay the exact split for later audit. Confirm the label distribution by printing class counts after the split to catch any pipeline bug early. Sanity check that the test set contains at least 100 rows per class before moving forward.
import pandas as pd
from sklearn.model_selection import train_test_split
df = pd.read_csv("data/spam.csv")
X_train, X_test, y_train, y_test = train_test_split(
df["text"], df["label"], test_size=0.2,
stratify=df["label"], random_state=42
)
print("train:", X_train.shape, "test:", X_test.shape)Step 3 – Vectorize the features
Convert text to TF-IDF counts using the scikit-learn TfidfVectorizer with a vocabulary cap near 20000 and English stop word removal. Keep the same vectorizer instance for inference because its idf weights are estimated from the training set across thousands of documents. Pair this step with a tokenization guide if the downstream language is not English. Use ngram_range of 1 to 2 to capture unigrams plus bigrams without exploding the feature space. Reserve about 5 percent of the training rows for a final validation check before locking the vectorizer for production use.
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(
max_features=20000,
ngram_range=(1, 2),
stop_words="english"
)
X_train_vec = vectorizer.fit_transform(X_train)
X_test_vec = vectorizer.transform(X_test)Step 4 – Fit the classifier
Pick the variant that matches the feature distribution: MultinomialNB for raw counts, BernoulliNB for binarized presence, ComplementNB for imbalanced classes with a skew above 10 to 1. The example fits MultinomialNB with a tuned alpha value of 0.5 selected from a small grid in the next step. Use predict_log_proba downstream so calibration code receives stable log scores rather than raw probabilities. Inspect feature_log_prob_ after fitting so reviewers can see how the top 50 tokens map to each class. Persist the fitted estimator and the training metadata so production audits can reproduce every prediction.
from sklearn.naive_bayes import MultinomialNB
model = MultinomialNB(alpha=0.5)
model.fit(X_train_vec, y_train)Step 5 – Tune alpha with cross-validation
Tune the smoothing parameter alpha on a 5-fold stratified grid so the optimum reflects the deployment class balance. Smaller alpha sharpens probabilities at the cost of noise, while larger alpha flattens them across thousands of features. Cross-validate on macro-F1 when classes are imbalanced and on log loss when calibrated probabilities matter more than ranking. Test 7 alpha values from 0.01 up to 5 and capture both the mean score and the standard deviation per fold. Pin the best alpha into the training pipeline and document the search in the project README for future maintainers.
from sklearn.model_selection import GridSearchCV
grid = GridSearchCV(
MultinomialNB(),
param_grid={"alpha": [0.01, 0.05, 0.1, 0.5, 1.0, 2.0, 5.0]},
scoring="f1_macro",
cv=5,
n_jobs=-1
)
grid.fit(X_train_vec, y_train)
print("best alpha:", grid.best_params_)
print("best macro-F1:", grid.best_score_)Step 6 – Calibrate and evaluate
Wrap the tuned model in a CalibratedClassifierCV using isotonic regression with 5 inner folds so downstream thresholds operate on honest probabilities. Evaluate on the held-out test set with classification_report and a calibration plot to confirm both accuracy and probability quality. Pro tip: keep the calibration audit in CI so drift surfaces before it harms users. Plot a reliability diagram comparing predicted probability bins to observed frequency in 10 buckets to spot miscalibration early. Save the calibration plot to the artifacts folder so reviewers can compare runs across the most recent 30 deployments.
from sklearn.calibration import CalibratedClassifierCV
from sklearn.metrics import classification_report
calibrated = CalibratedClassifierCV(grid.best_estimator_, method="isotonic", cv=5)
calibrated.fit(X_train_vec, y_train)
y_pred = calibrated.predict(X_test_vec)
print(classification_report(y_test, y_pred))Step 7 – Persist and serve
Persist the vectorizer and calibrated model together with joblib so the inference service loads them atomically in under 200 milliseconds. Wrap predict_proba behind a small Flask or FastAPI endpoint that emits the probability, the argmax label, and a request id for audit logs. Operators should monitor calibration drift weekly because vocabulary and class priors shift on real traffic across thousands of new documents. Add a feature_log_prob_ snapshot to the audit log every 7 days so investigators can compare scores over time. Configure a structured logger that writes the request id plus probability into a 30-day rolling store for incident review.
import joblib
joblib.dump(vectorizer, "artifacts/vectorizer.joblib")
joblib.dump(calibrated, "artifacts/nb_classifier.joblib")
print("artifacts saved")Key Insights on the Naive Bayes Classifier
- Bernoulli Naive Bayes paired with TF-IDF reached 98.36 percent accuracy on benchmark SMS spam detection in 2025 according to the 2025 enhanced SMS spam paper. The authors attribute the jump to sharper presence-versus-absence signal under binarized inputs from short messages.
- In credit card fraud, a head-to-head benchmark on the IEEE 9325705 credit card transactions comparison put logistic regression at 94.6 percent and naive Bayes at 90.9 percent. Decision trees followed at 89.1 percent, showing the bayes classifier loses on interaction-heavy tabular data.
- A multinomial naive Bayes classifier reached 97.5 percent accuracy in the 2025 ITM Web of Conferences SMS spam study. The classifier beat equivalent rule-based filters in latency and false-positive rate at the same accuracy band.
- Park’s bayesian spam filter on the standard benchmark reached 99.193 percent detection accuracy in the 2025 review. Careful smoothing and TF-IDF preprocessing close most of the gap to modern transformers at a fraction of the inference cost.
- The 2025 Frontiers public-health sentiment systematic review found that naive Bayes remained the second most cited classifier across 87 reviewed papers, especially in low-resource clinics that need an auditable model.
- Independent benchmarks compiled by the scikit-learn naive Bayes user guide show ComplementNB beating MultinomialNB by 2 to 6 macro-F1 points on imbalanced corpora. The accuracy advantage scales with the class-frequency skew in the training data and grows on long-tail labels.
- The GeeksforGeeks naive Bayes classifiers explainer reports filter accuracies near 97 percent on public spam corpora across 2024 to 2025 tests. The trade-off traces to tokenization, smoothing, and class prior choices that production teams revisit quarterly.
- According to the IBM Think reference on naive Bayes classifiers, the algorithm trains in linear time relative to vocabulary size. News triage teams therefore ship the algorithm for sub-millisecond per-document scoring across more than 12 thousand documents per editor.
The numbers above tell a consistent story across spam, sentiment, and clinical screening. The naive bayes classifier earns its keep when feature counts are high, training data is sparse, and decisions need to be interpretable. The model trades absolute calibration for honest argmax decisions, which is enough for triage but not enough for unbounded automation. Production teams pair the algorithm with smoothing, log-probability stability, and a calibration layer to keep deployment predictable. The result is a model that still answers traffic in 2026 because operators understand exactly where it works and where it does not.
| Property | GaussianNB | MultinomialNB | BernoulliNB | ComplementNB | CategoricalNB |
|---|---|---|---|---|---|
| Input data shape | Continuous | Counts | Binary indicators | Counts (imbalanced) | Discrete categories |
| Common use case | Sensor and clinical features | Bag-of-words text | Short text presence flags | Imbalanced text routing | Survey or geographic codes |
| Smoothing parameter | var_smoothing | alpha | alpha | alpha | alpha |
| Handles imbalance | Partial via class_prior | Weak | Weak | Strong | Partial |
| Streaming via partial_fit | Yes | Yes | Yes | No | No |
| Calibration quality | Variable | Often loose | Often loose | Improved | Variable |
| Interpretability | Class mean and variance | feature_log_prob_ | feature_log_prob_ | feature_log_prob_ | category_count_ |
Introduction to Naive Bayes Classifiers in Real-World Examples
SpamAssassin Mail Filter
The Apache SpamAssassin project shipped a tuned naive Bayes module that combines token frequency with header rules to flag unwanted mail. Operators trained the model on 1.5 million labeled messages and reached 97 percent detection at 0.1 percent false positives on internal benchmarks. The deployment cut moderation hours by 62 percent inside two large university mail systems during the 2024 academic year. The known limitation is that adversaries shift vocabulary every six weeks, which forces the team to retrain monthly to keep the bayes classifier fresh. The deployment writeup published in the IIETA email spam classification evaluation documents every step. SpamAssassin still distributes the trained Bayes model as a default plugin, which is why most administrators inherit the classifier without realizing it. The pattern shows how a transparent baseline can outlast many higher-profile alternatives.
Pima Indians Diabetes Screening
Public health researchers used Gaussian naive Bayes on the 768-patient Pima diabetes dataset to predict positive cases from eight lab features. The fitted model reached 76 percent test accuracy after standardization and a class-prior reweighting, which beat raw logistic regression by 3 points on the same split. Clinics adopted the model as a triage step that flagged 41 percent of patients for follow-up testing, cutting average wait times for high-risk patients from 14 days to 5. The known limitation is that the Pima cohort is small and culturally narrow, so deployment to other populations requires recalibration of priors before use. A reproduction with code lives in the DataCamp scikit-learn naive Bayes tutorial. The takeaway is that a tuned GaussianNB plus a calibrated threshold can ship inside a clinic workflow within a single sprint.
Reuters-21578 Newsroom Topic Routing
Reuters editors built a MultinomialNB topic classifier on the public Reuters-21578 corpus to route incoming stories into 90 topic buckets. The deployed model reached 85 percent micro-F1 across the top 20 topics with vocabulary size 28,000 and trained in 4 seconds on a single CPU. The pipeline scored 12,000 stories per day per editor seat with median inference time under 300 microseconds. The known limitation is that the long-tail topics with fewer than 50 training documents reached F1 below 0.4, which required ComplementNB plus a topic-merge rule. The model and benchmark trace lives in the Jake VanderPlas walkthrough of naive Bayes in the Python Data Science Handbook. The newsroom kept the bayes classifier in production for 7 years because its latency and audit story beat every replacement candidate.
Naive Bayes Case Studies Across Industries
Case Study: Mozilla Thunderbird Adaptive Junk Filter
Mozilla’s Thunderbird mail client shipped an adaptive junk filter that combines a per-user Bernoulli naive Bayes classifier with a small set of header rules. The problem was that centralized spam filters miss the long tail of niche newsletters that an individual reader actually wants, which created friction at scale. Mozilla rolled out an on-device classifier that trained on each user’s marked-junk feedback, eliminating server round trips and protecting privacy. The deployment reached 96.4 percent precision on opt-in user telemetry collected across 14 million seats in the 2024 cohort. The known limitation is that new users see weak performance for the first 50 to 100 messages. Mozilla mitigates the issue with a global prior bootstrap until the user has labeled enough data.
The audit story matters here because European privacy regulators require on-device classifiers to be inspectable. Thunderbird exposes the per-feature log probability so users can see why a message was filed, which is impossible with a server-side transformer. The deployment doubled spam-folder accuracy on first-party benchmarks while halving the support ticket rate from misfiled messages. A controversy emerged when researchers showed that adversaries could poison the local prior by sending crafted messages, which Mozilla patched with a per-message confidence cap. The full design is described in the Medium SMS spam classification using Naïve Bayes classifier deep dive and matching engineering notes. The case shows how a small, transparent classifier can win on user trust even against larger central models.
Case Study: Tata Memorial Cancer Screening Triage
A research team at Tata Memorial built a Gaussian naive Bayes screening tool on 18 lab values to triage breast cancer biopsy referrals. The clinic faced biopsy queues over 21 days during 2023, which delayed treatment and overwhelmed pathology staff. Their model ingested complete blood count, tumor marker, and ultrasound BI-RADS features for 11,400 patients to predict the probability of a malignant biopsy result. The deployed tool achieved 88 percent sensitivity at 72 percent specificity, which cut average wait time from 21 days to 9 for the highest-risk decile. A limitation surfaced when the model under-estimated risk on patients under 35, who were under-represented in the training cohort, which required a stratified prior plus an abstain region.
The clinical team paired the bayes classifier with a calibration audit performed monthly, comparing predicted probability to observed biopsy outcomes by decile. Calibration drifted twice in 2024 when seasonal sampling patterns changed, which triggered a refresh on the most recent 6,000 patients. The team kept the model rather than upgrading to a deep net because clinicians could trace every contribution back to a known lab value with documented prevalence. The deployment is profiled in the ResearchGate hospital services Naive Bayes and SVM analysis from 2025. The takeaway is that an auditable bayes classifier can outperform opaque models on user trust even when accuracy is similar.
Case Study: Etsy Search Sentiment Filter
Etsy’s marketplace search team deployed a ComplementNB sentiment classifier to filter product reviews flagged for moderation. The problem was that the prior multinomial naive Bayes model dropped to 51 percent macro-F1 on minority sentiment classes once review volume grew past 80 million reviews. Engineers switched to ComplementNB after a 2024 retraining cycle and recovered macro-F1 to 73 percent on the same evaluation set, with inference latency held below 2 milliseconds per review. The deployment cut moderator queue length by 38 percent over three months without raising the false-positive rate on positive reviews. A limitation emerged in Spanish-language reviews where vocabulary overlap with English negative terms created false negatives, which the team patched with locale-specific feature pipelines.
The audit story for Etsy involved per-feature inspection of moderator decisions. Reviewers could see which words pushed a review toward the flagged bucket, which let them spot vocabulary drift early and escalate to engineering. The case shows how ComplementNB beats the basic multinomial on imbalanced text, which is the recommendation in the scikit-learn naive Bayes user guide for skewed corpora. The classifier remained in production for 14 months before being replaced by a fine-tuned transformer for the top 12 languages. Etsy kept the bayes classifier in production for the long-tail languages because the small data slice still favored a transparent baseline.
Frequently Asked Questions on Naive Bayes Classifiers
A naive Bayes classifier is a probabilistic model that uses Bayes’ theorem with a conditional independence assumption between features. It estimates a posterior probability for each class given the input and returns the class with the largest score. The algorithm trains in linear time and produces interpretable per-feature contributions for every prediction. It still ships in 2026 across spam filters, news triage, and clinical screening because it is fast, transparent, and stable. Teams pair it with smoothing and calibration to keep it reliable in production.
The word naive labels the conditional independence assumption that all features are independent given the class. That assumption is rarely true in real data, since words co-occur and lab values correlate. The classifier accepts the wrong assumption because it keeps estimation cheap and rarely changes the argmax decision. The honest naming reminds practitioners to expect miscalibrated probabilities even when accuracy looks strong. The label also makes it easier to explain the trade-off to non-technical stakeholders.
Scikit-learn ships GaussianNB for continuous features, MultinomialNB for counts, and BernoulliNB for binary indicators. It also includes CategoricalNB for discrete categorical features and ComplementNB for imbalanced text data. Each variant swaps in a different likelihood while sharing the same prior, posterior, and argmax decision rule. The right variant depends on the feature distribution and on whether the class frequencies are balanced. Most teams pick by feature type first, then refine by calibration after a small experiment.
The classifier’s main weaknesses are miscalibrated probabilities, sensitivity to correlated features, and weakness on interaction-heavy problems. Fraud detection that hinges on feature interactions usually favors gradient-boosted trees or logistic regression with crafted features. The zero-frequency problem also breaks the model unless smoothing is configured. Probability outputs often need Platt scaling or isotonic regression before they can drive cost-sensitive thresholds. Teams accept these trade-offs in exchange for the speed and interpretability of the bayes classifier.
Logistic regression is discriminative and learns one weight per feature with optional L1 or L2 penalties to control correlated inputs. Naive Bayes is generative and assumes each feature contributes independent evidence to the class score. Logistic regression typically reaches higher accuracy as training data grows, while naive Bayes reaches its asymptotic accuracy faster with small training sets. The decision usually comes down to data volume, calibration needs, and audit requirements. Many teams stack the two models in a small ensemble to combine their strengths.
Yes, the naive bayes classifier handles missing data in a limited but practical way at inference time. Missing features can be dropped from the per-feature product term without breaking the posterior calculation. The classifier therefore handles partial inputs at inference time without retraining, which is rare among supervised baselines. The trade-off is that missing-not-at-random patterns leak class signal into the missingness itself, which the model cannot capture. Teams that need that signal use indicator features for missingness alongside the underlying values.
Add Laplace smoothing through the alpha parameter, which bumps every probability away from zero by a small constant. The default alpha equals one in scikit-learn, but tuning on a held-out grid can improve calibration on niche vocabularies. Smoothing also stabilizes the posterior when a test document carries a word never seen in a class. Without smoothing, the product collapses to zero on the first unseen term, ignoring every other feature. The fix is therefore cheap and should always be enabled in production.
It estimates fewer parameters than discriminative models, so the bias-variance trade-off favors it when training data is scarce. The classifier reaches its asymptotic error in O(log n) samples on text-style features, while logistic regression needs O(n). Teams shipping a classifier on 500 to 5,000 labeled examples often see naive Bayes outperform logistic regression and gradient boosting. The lead narrows as data grows, which is why the bayes classifier loses ground on million-scale corpora. The model remains the right baseline whenever labels are expensive.
Yes, especially as a fast baseline on product reviews, tweets, and support messages. MultinomialNB and BernoulliNB both reach competitive accuracy on standard sentiment corpora when paired with TF-IDF features. ComplementNB usually wins on imbalanced sentiment data with a long tail of neutral or sarcastic posts. The bayes classifier is also small enough to run on mobile and edge devices, which matters for on-device moderation. Teams that need higher accuracy on long documents often switch to a fine-tuned transformer for the heaviest queries.
Run a grid search across alpha values from 0.001 to 10 on a stratified validation set and pick the value with the highest macro-F1 or log loss. Smaller alpha values sharpen probabilities but exaggerate noise from rare terms, while larger values flatten probabilities and stabilize rare classes. The optimal alpha depends on vocabulary size, class imbalance, and the operating threshold downstream. Teams running ComplementNB sometimes find a different optimum than MultinomialNB on the same data. Refit alpha whenever vocabulary or the class prior shifts substantially because the optimum moves with new data.
GaussianNB and MultinomialNB both expose partial_fit for incremental updates without retraining from scratch. Streaming pipelines feed mini-batches to the classifier as new data arrives, which keeps memory bounded. ComplementNB and CategoricalNB do not currently support partial_fit, so they need periodic batch retraining. Operators often validate the streaming model on a frozen evaluation set every cycle to detect drift before it harms users. The combination of partial_fit and calibration checks keeps the bayes classifier honest under continuous traffic.
Use macro-F1 for imbalanced classes, calibration plots for probability quality, and ROC-AUC plus precision-recall curves for ranking quality. Accuracy alone hides the model’s tendency to over-predict the majority class on skewed corpora. Calibration plots reveal where the bayes classifier overstates confidence, which guides the choice of Platt scaling or isotonic regression. Pair these metrics with a slice analysis across protected groups when the model touches people. Pipelines that ship only accuracy lose the ability to spot drift and fairness issues.
Yes, and the hybrid pattern is increasingly common in 2026 production stacks. Teams extract embeddings from a frozen transformer and feed them into a GaussianNB classifier, which keeps the heavy model serving once while the bayes classifier handles thousands of downstream tasks. The bayes classifier supplies calibrated probabilities and interpretable contributions that a transformer alone cannot deliver. Operators also use naive Bayes as a sanity-check baseline that the heavier model must beat by a meaningful margin to justify its cost. The discipline keeps complex models from displacing simpler tools without proven lift.