Introduction
One of the forms of Machine Learning Algorithms is Semi – Supervised learning. A supervised machine learning algorithm is a very costly process because all the data must be labeled by hand. In an unsupervised machine learning algorithm the spectrum of use is very limited as it has no output labels. Semi supervised learning was introduced in order to overcome these limitations.
Table of contents
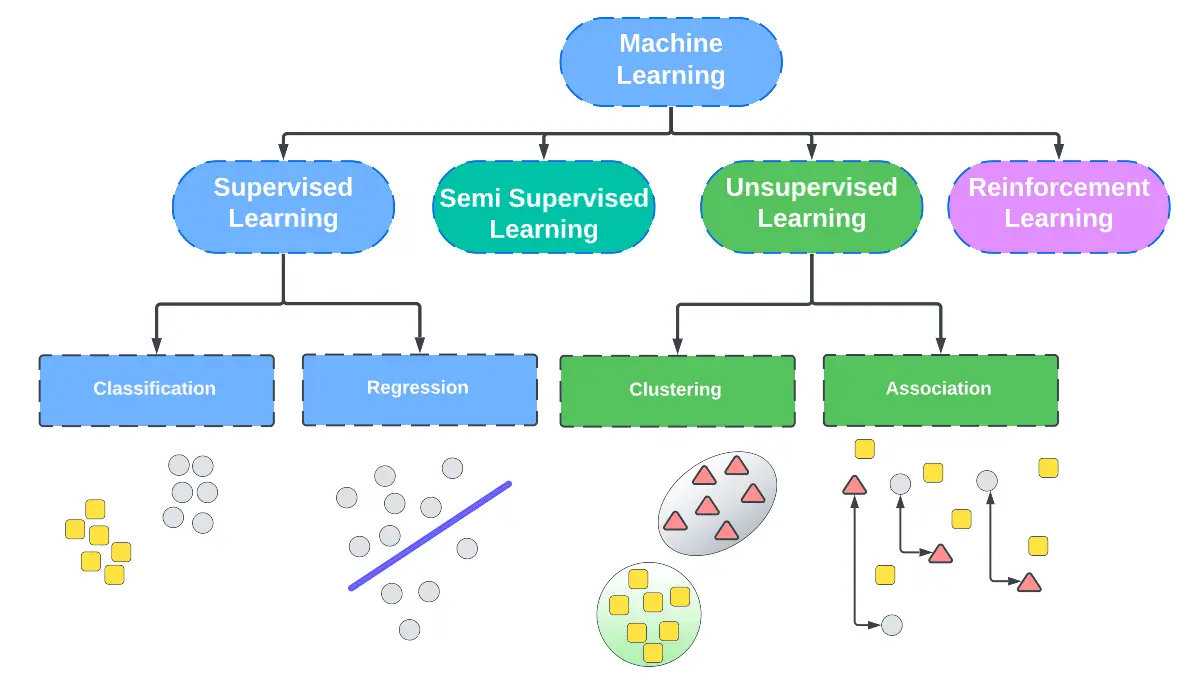
What is Semi-Supervised learning?
Semi supervised machine learning algorithms are a hybrid that takes the best parts of supervised learning and unsupervised learning algorithms. It is able to use some labeled data and a lot of unlabeled data in order to train a model that is able to label data without having to do it by hand. This gives it both the benefits of supervised and unsupervised machine learning algorithms while avoiding the drawbacks.
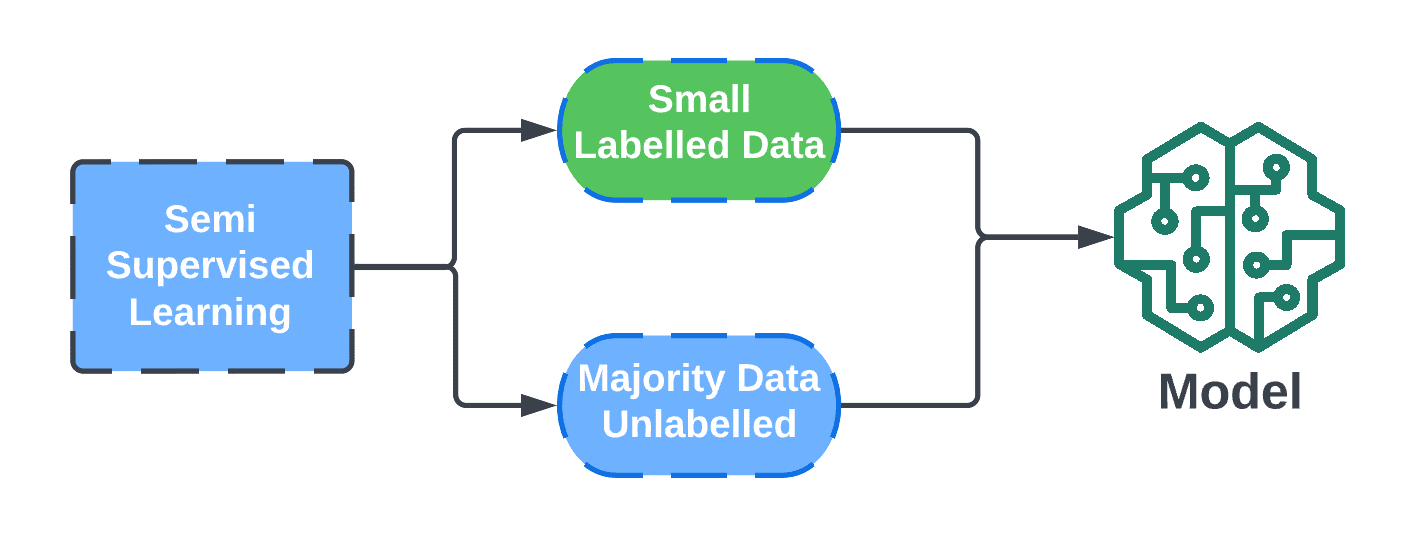
The semi supervised machine learning algorithms are often used for regression, classification, and clustering problems. However, clustering problems can also be solved using unsupervised algorithms using the k-means model. Semi supervised learning is cheaper than supervised learning and more useful than unsupervised learning making it the perfect hybrid between the two. Next let us look at how semi supervised learning actually works.
Semi Supervised Learning Steps for Self training
We know that semi supervised learning uses small amounts of labeled data and large amounts of an unlabeled data set, but how does it actually work? Below are the steps for the self training method, which is the most common method:
- The first step involves training the data using small amount of labeled data that you have. This is done in a similar way to supervised machine learning algorithms. Do this step until you have satisfactory results and the entire input space is filled.
- The second step occurs after the entire input space is filled. Here we use the labeled data trained model to predict outputs on the data set containing all the unlabeled samples. The predicted outputs are known as pseudo labels. They are called pseudo labels because they may not be accurate labels. At the end of the steps we want the ground truth over pseudo labels.
- In the third step, we use the pseudo labels from the second step and try to link them to the training data from step one, which is the labeled training data. This is the training phase.
- For the fourth step, we look at the data inputs from the unlabeled training data and the labeled training data and try to find links between the entire data set and output labels.
- The fifth and final step involves training this new model the same way as done in step one. This is done in the hopes of decreasing error and improving the accuracy of the model. This allows the model to make confident predictions.
Also Read: Introduction to Machine Learning Algorithms
Semi Supervised Learning Steps for Co-training
Co-training is an improvement over self training. Similarly to self training it uses a small amount of labeled data and a large amount of unlabeled sample data. Unlike self training though, co-training uses two classifiers that are able to view the data in two different ways. The co-training learning method can be used for classification tasks. Below are the steps for co-training:
- For the first step you choose two classifiers and two different views of the data. Each classifier is trained on one view of the data using a small amount of labeled data. One performs active learning, the other inductive learning.
- In the second step we take a look at the two trained models and choose the one that has more unlabeled data. This data is then given pseudo labels. Do this step until the entire input space is filled with pseudo labels.
- In the third step the classifiers from the first step are then used to co-train each other using pseudo labels. We then look at their learning performance.
- The two classifiers update each other’s labels based on confidence and error rates. This is the step where pseudo labels are thrown out and true labels are added. The goal is to minimize entropy and have a model that can make confident predictions.
- The fifth and final step occurs when the two classifiers have finished their learning tasks. The two are combined into a final classification result.
Semi Supervised Learning with graph-based label propagation
The graph based method for label propagation is another way to implement semi supervised learning. This graph based method was first proposed in 2002. The intuition behind this graph based method is based on euclidean distance. The nodes in this graph based method will all have soft labels or be distributed in a way that is based on their labels. Some of the nodes will have human made annotations. The goal of the graph based method is to spread these annotations across the whole graph. One possible way of doing this in the graph based method is to first choose a starting point or node.
From that starting point count all paths that travel through that node across the entire network. Once that is done, then the same step is repeated across every node in the network. The graph based method sounds tedious but it has some practical applications. With the graph based method for label propagation it is possible to make label predictions to predict what a potential customer on a website may be interested in. For example, the graph based method for semi supervised learning is used in recommendation systems.
It is also used in systems that personalize web pages for a user. This makes graph based semi supervised learning useful for things like social media. Graph based semi supervised learning can also be used in Hyper-spectral Image Classification. Hyper-spectral Image Classification is the task of applying a label to every single pixel on an image that was captured using hyper-spectral sensors. This is done more efficiently using pairwise similarity across pixels.
Semi-Supervised Learning Examples
Now that we know about graph based semi supervised learning, lets look at other machine learning applications of semi supervised learning.
Speech Recognition
A semi supervised learning approach is used in speech recognition to provide better performance. Facebook has implemented a self supervising learning approach to label audio on their website. This semi supervised learning approach was successful and resulted in the word error rate on audio going down by 33 percent.
Web Content Classification
This is a semi supervised classification method. This semi supervised classification method sets out to go through webpages and organize them based on labels. This is seen in search engines like Google or Bing. By using this semi supervised classification method, Google Search is able to bring content to the user based on what they searched for with a high level of accuracy. This is done using similarity graph testing. Similarity graph testing is when we look at the degree of similarity between two items and that allows the model to determine if they are similar.
Text Document Classification
This is also another semi supervised classification method.This semi supervised approach helps to read text documents and label them in a faster and more efficient way than humans. Sometimes this semi supervised classification method can be built on top of the neural networks that come with deep semi supervised learning using generative models. Usually training neural networks are time consuming, but deep semi supervised learning makes it efficient. The SALnet text classifier was developed using deep semi supervised learning, thus demonstrating its effectiveness. SALnet uses a base classifier, which is a bunch of k-means models. It also uses a supervised classifier to assign a new object to a class.
Semi-supervised support vector machine (SVM)
A SVM is a machine learning model that is based on statistical learning theory. This model is used in some text document classification algorithms. However, most of the time it is used for supervised learning algorithms.
Holistic Approach
There are also holistic approaches to semi supervised learning, one such example is MixMatch. Here we use the variable ‘L’ to define label space, and ‘U’ for unlabeled space. The output labels are then defined as ‘X’. The holistic approach then follows a very complicated mathematical algorithm that streamlines the guessing labels step of the semi supervised learning steps.
Positive Unlabeled Learning
Positive unlabeled learning or PU learning for short was a term coined in the year 2005. PU learning’s goal is to build a binary classifier to classify a test set into two classes. In PU learning we use P to represent positive classes and U to label unlabeled data. The ultimate goal in PU learning to get a set of classes where P can be U. PU learning is only used in cases where there is both positive samples and unlabeled samples. This makes PU learning only useful in some fields like bioinformatics.
Class distribution mismatch
Most semi supervised models rely on there being good labeled data. This is one of the semi supervised learning assumptions we make before using the algorithm on a data set. For example some data could be class shared which would make co training difficult. So what do we do when there is a class distribution mismatch causing bad labeled data? In this cause we use deep belief networks with deep semi supervised learning. When facing a class distribution mismatch problem, instead of looking at labels we can instead look at parameters. From there we can divide the parameters into good ones and bad ones, which helps overcome the class distribution mismatch problem. This method is used in convergence and divergence problems.
Also Read: Artificial Intelligence Labeling: Present and Future
Challenges of Semi Supervised Learning
After reading this article you might be starting to think that semi supervised learning is always better in every scenario. However, it does not fit for some learning tasks. For example if the labeled data does not represent the entire data set, then semi supervised learning will not perform well.
For example if you have a large amount of objects that look different from different angles, semi supervised learning will not be accurate in labeling them. High dimensional data also can pose the problem of concept of similarity. This can cause the algorithm to think two objects are the exact same when they are not, this occurs when the similarity measure is too high. Semi supervised learning algorithms need a balanced training data set.
Also if you have a large amount of labeled data already supervised learning will out perform semi supervised learning approaches. Semi supervised learning also has a problem when high dimensional data gets involved, because there will be input vectors. Recently though in 2019, a team has come together to develop a high dimensional semi supervised learning framework that can be used on high dimensional data, by using semi supervised neural networks on input vectors . Semi supervised learning also has to be resilient against adversarial training.
Adversarial training is the process of providing deceptive input to machine learning models in order to trick them into providing bad data. When there are a small number of labeled data in a data set semi supervised learning algorithms also have to be wary of marginal distribution of labeled data. Marginal distribution refers to data that has nothing to do with the rest of the data. Label prediction shifts can also be a problem in semi supervised learning when using active learning.
Label prediction shifts happen when class proportions are different. To overcome this problem of label prediction shifts, semi supervised learning uses ground truth after pseudo labeling data. By using ground truth semi supervised learning algorithms are able to avoid label prediction shift issues.
References
Bewtra, Avi. Semi-Supervised Learning: Techniques & Examples [2023]. 2 Feb. 2023, https://www.v7labs.com/blog/semi-supervised-learning-guide. Accessed 16 Feb. 2023.
Brownlee, Jason. “What Is Semi-Supervised Learning.” MachineLearningMastery.Com, 8 Apr. 2021, https://machinelearningmastery.com/what-is-semi-supervised-learning/. Accessed 16 Feb. 2023.
Contributors to Wikimedia projects. “Semi-Supervised Learning.” Wikipedia, 5 Feb. 2023, https://en.wikipedia.org/wiki/Semi-supervised_learning. Accessed 16 Feb. 2023.
ICML 2007 Tutorial: Semi-Supervised Learning. https://pages.cs.wisc.edu/~jerryzhu/icml07tutorial.html. Accessed 16 Feb. 2023.
Mahendra, Sanksshep. “What Is Supervised Learning?” Artificial Intelligence +, 5 Oct. 2022, https://www.aiplusinfo.com/blog/supervised-learning/. Accessed 16 Feb. 2023.