
Introduction
The volume of data generated by connected devices is growing at an extraordinary pace, and traditional cloud infrastructure struggles to keep up with real-time processing demands. This technology has emerged as a critical layer between IoT sensors and centralized cloud servers, enabling faster analytics, reduced latency, and localized decision-making. According to a report by Fortune Business Insights, the global fog computing market was valued at USD 1.09 billion in 2025 and is projected to reach USD 46.56 billion by 2034, growing at a CAGR of 51.72%. This explosive growth signals a massive shift in how organizations handle data-intensive workloads, particularly those involving machine learning at the network edge. Fog computing is not a replacement for the cloud; it is a strategic extension that brings intelligence closer to where data originates. As industries from healthcare to manufacturing adopt fog architectures, This convergence is becoming one of the most consequential developments in distributed AI. This article explores what fog computing is, how it works, and how organizations are deploying machine learning models across fog networks to unlock real-time insights.
Quick Answers on Fog Computing and Machine Learning
What is fog computing?
Fog computing is a decentralized computing architecture that extends cloud capabilities to the network edge, processing data closer to IoT devices and sensors to reduce latency, save bandwidth, and enable real-time analytics.
What is the primary benefit of fog computing in the context of distributed processing for AI?
The primary benefit is reduced latency for AI inference, allowing machine learning models deployed on fog nodes to deliver real-time predictions without depending on a round trip to centralized cloud servers.
How does fog computing support machine learning applications?
Fog nodes execute trained ML models locally for real-time inference, support federated learning across distributed devices, and pre-process raw sensor data before transmitting refined datasets to the cloud for deeper analysis.
Key Takeaways
- The fog computing market is projected to grow from USD 1.09 billion in 2025 to USD 46.56 billion by 2034, driven by IoT expansion and AI-at-the-edge demand.
- Fog computing places data processing, storage, and networking between IoT devices and the cloud, reducing latency by up to 10x compared to cloud-only architectures.
- Machine learning models deployed on fog nodes enable real-time inference for applications like autonomous vehicles, smart cities, and remote patient monitoring.
- Federated learning across fog infrastructure allows organizations to train ML models collaboratively without sharing raw data, preserving privacy at the device level.
Table of contents
- Introduction
- Quick Answers on Fog Computing and Machine Learning
- Key Takeaways
- What Is Fog Computing?
- Understanding Fog Computing and Its Core Principles
- The Three-Tier Architecture Behind Fog Networks
- How Fog Computing Differs from Cloud and Edge Computing
- Why IoT Devices Need Fog Nodes for Real-Time Processing
- The Connection Between Fog Computing and Machine Learning
- Running ML Inference at the Fog Layer
- Federated Learning Across Fog Nodes
- Fog Computing in Healthcare and Remote Patient Monitoring
- Smart City Applications Powered by Fog Networks
- Industrial Automation and Manufacturing Use Cases
- Autonomous Vehicles and Transportation Systems
- The Security Risks of Distributed Fog Architectures
- Privacy and Data Governance Challenges
- Ethical Considerations for AI at the Network Edge
- Energy Efficiency and Sustainability in Fog Environments
- The Fog Computing Market and Growth Projections
- What Comes Next for Fog Computing and Distributed AI
- How to Deploy Machine Learning Models on Fog Infrastructure
- Key Insights on Fog Computing and Machine Learning
- Fog Computing Compared: Traditional Cloud vs. Fog vs. Edge for Machine Learning
- How Leading Organizations Are Using Fog Computing in Practice
- Lessons From Fog Computing Deployments Across Industries
- Frequently Asked Questions About Fog Computing and Machine Learning
What Is Fog Computing?
Fog computing is a decentralized computing architecture that extends cloud computing capabilities to the network edge, positioning processing, storage, and networking resources between IoT devices and centralized data centers to reduce latency, conserve bandwidth, and enable real-time machine learning inference closer to the data source.
Fog Computing Performance Simulator
Explore how fog nodes, device count, and workload type affect latency, bandwidth savings, and processing costs across cloud, fog, and edge architectures.
Understanding Fog Computing and Its Core Principles
This distributed architecture positions processing, storage, and networking resources between data-generating devices and centralized cloud data centers. Cisco originally introduced the concept to address the limitations that arise when billions of IoT sensors, cameras, and actuators attempt to route all their data through distant cloud servers. The core principle centers on processing data as close to its source as possible, which minimizes the distance that information must travel before an actionable response can be generated. Fog nodes, which include routers, gateways, industrial controllers, and specialized micro-servers, serve as the computational backbone of this architecture. These nodes operate in a semi-autonomous fashion, executing pre-programmed logic and machine learning inference while selectively forwarding summarized or critical data to the cloud. The approach is particularly valuable in scenarios where millisecond-level response times determine operational success or failure, such as factory floor quality inspection and traffic signal management.
Organizations that rely on AI and cloud computing infrastructure are increasingly recognizing that cloud-only strategies cannot satisfy the latency, bandwidth, and privacy requirements of modern IoT deployments. Fog computing addresses each of these constraints by distributing workloads across a hierarchy of nodes positioned at different points in the network. A temperature sensor in a cold storage warehouse, for example, can relay its readings to a nearby fog gateway that evaluates whether an anomaly exists before sending only the flagged events to a cloud dashboard. This selective data transmission conserves bandwidth and reduces cloud storage costs while ensuring that critical alerts reach decision-makers within seconds rather than minutes.
The principles that define fog computing include low latency, location awareness, geographical distribution, heterogeneity of devices, and support for real-time interactions. Each of these principles reflects a design philosophy that prioritizes distributed intelligence over centralized processing. Fog networks can span multiple physical locations, operate across diverse hardware platforms, and adapt dynamically to changing workloads. These characteristics make fog computing especially suited for industries where connectivity is intermittent, data volumes are massive, and response speed is non-negotiable.
The Three-Tier Architecture Behind Fog Networks
The architecture of a fog network follows a three-tier model comprising the device layer, the fog layer, and the cloud layer. At the bottom, the device layer consists of sensors, actuators, wearables, cameras, and other IoT endpoints that generate raw data continuously. These devices typically have limited processing power and memory, which constrains their ability to perform complex analytics independently. They transmit their data upward to the fog layer, where intermediate computation occurs on nodes such as gateways, routers, and edge servers equipped with CPUs, GPUs, or neural processing units. The fog layer acts as the critical intermediary, filtering noise from signals, running inference models, and aggregating data before passing only essential information to the cloud. This tiered structure reduces the volume of data that must traverse the wide-area network, which in turn lowers costs and improves overall system responsiveness.
The cloud layer sits at the top of this architecture and handles tasks that require large-scale storage, historical analysis, model training, and long-term pattern recognition. Organizations use the cloud to train complex deep learning models on accumulated datasets and then deploy the trained models downward to fog nodes for local inference. This bidirectional flow of data and intelligence creates a continuous feedback loop where the cloud refines models based on aggregated insights and the fog layer applies those refined models in real time. The three-tier architecture ensures that each layer handles the tasks best suited to its capabilities, creating an efficient division of computational labor that neither cloud-only nor edge-only architectures can replicate.
How Fog Computing Differs from Cloud and Edge Computing
Cloud computing, edge computing, and fog computing are often discussed together, but each serves a distinct purpose within the data processing continuum. Cloud computing centralizes all processing, storage, and analytics in remote data centers operated by providers such as Amazon Web Services, Microsoft Azure, and Google Cloud Platform. This model offers massive scalability, virtually unlimited storage, and access to powerful GPU clusters for training machine learning models. The tradeoff is latency, because data must travel from its point of origin to a distant server and back before any action can be taken. For applications where a delay of several hundred milliseconds is acceptable, cloud computing remains the most cost-effective and flexible option.
Edge computing moves processing to the device itself, eliminating network transit entirely by running algorithms directly on the sensor or endpoint that generates the data. A security camera with an embedded neural processing unit, for example, can perform object detection locally without sending any video feed to a remote server. This approach provides the lowest possible latency and strongest data privacy, since raw data never leaves the device. The limitation of edge computing lies in the processing power and storage capacity available on small, battery-powered devices, which restricts the complexity of models that can run at the true edge. Organizations exploring IoT in the retail industry often combine edge processing on individual sensors with cloud analytics for store-wide insights.
The approach occupies the middle ground between edge and cloud, providing a distributed processing layer that aggregates data from multiple edge devices and performs intermediate analytics on fog nodes within the local area network. The distinction between fog and edge is subtle but important: edge computing processes data on the device itself, while fog computing processes data on a gateway or local server that sits between the device and the cloud. Fog nodes can coordinate across dozens or hundreds of edge devices, balancing workloads and managing data flows that a single edge device could not handle alone. This coordination capability makes fog computing particularly valuable for complex deployments where multiple data streams must be correlated in near-real time.
The practical difference becomes clearest in multi-device scenarios like smart factories, where hundreds of sensors generate simultaneous data streams that require collective analysis rather than isolated device-level processing. A single edge sensor can detect a vibration anomaly on one machine, but a fog node can correlate vibration patterns across an entire production line to identify systemic issues before they cascade. The big data processing requirements of such scenarios demand an intermediate layer that neither the edge nor the cloud can fulfill alone. Fog computing provides precisely this layer, bridging the gap between localized device intelligence and centralized cloud analytics to create a cohesive, responsive computing architecture.
Why IoT Devices Need Fog Nodes for Real-Time Processing
The proliferation of IoT devices has created a data volume problem that cloud computing alone cannot solve efficiently. By some estimates, connected IoT devices worldwide now exceed 15 billion, and each one generates a continuous stream of telemetry data. Sending all of this raw data to the cloud for processing would overwhelm available bandwidth, introduce unacceptable latency, and generate prohibitive costs for data transmission and storage. Fog nodes address this challenge by filtering, aggregating, and analyzing data locally before forwarding only the most relevant information to the cloud. A smart building with thousands of environmental sensors, for instance, can use fog gateways to process temperature, humidity, and occupancy readings locally and send only exception-based alerts to a centralized management platform.
Real-time processing is not merely a performance optimization; it is a safety requirement in many IoT applications. Autonomous vehicles must make braking decisions within milliseconds, industrial control systems must detect equipment malfunctions before they cause accidents, and medical devices must respond to patient vital sign changes without waiting for a cloud server response. Fog computing provides the sub-10-millisecond response times that these applications demand by keeping the processing loop short and the decision-making local. The fog layer can execute pre-trained machine learning models that classify incoming sensor data and trigger automated responses without any dependency on external network connectivity.
Connectivity itself presents another challenge that fog computing mitigates. Many IoT deployments operate in environments where internet access is unreliable, intermittent, or entirely unavailable, such as offshore oil platforms, underground mines, and remote agricultural installations. Fog nodes allow these deployments to function autonomously during connectivity outages by caching data locally and synchronizing with the cloud once connectivity is restored. This resilience ensures that IoT systems continue to deliver value even when the network connection to the cloud is disrupted, which is a critical advantage for organizations operating in harsh or remote environments.
The Connection Between Fog Computing and Machine Learning
Machine learning and fog computing share a natural synergy because both technologies aim to extract actionable intelligence from large volumes of raw data. ML algorithms require data to learn patterns, and fog nodes sit at the intersection of data generation and data processing, making them ideal platforms for executing trained models in real time. The relationship works in both directions: ML models deployed on fog nodes enable intelligent local decision-making, and fog-generated data feeds back into cloud-based training pipelines that continuously refine those models. This bidirectional flow represents a fundamental shift from the traditional paradigm where all ML processing occurred in the cloud, and it enables organizations to achieve the speed and privacy benefits of local inference while maintaining the learning advantages of centralized training.
The practical implications of this connection are significant for any organization working with machine learning fundamentals in IoT-heavy environments. A fog node running a classification model can sort incoming sensor data into categories in real time, flagging anomalies for immediate attention while forwarding normal readings to the cloud in summarized form. This approach reduces the volume of data that must be processed in the cloud by as much as 90%, according to researchers studying fog-based data pipelines. The result is a machine learning ecosystem that operates across multiple layers of infrastructure, with each layer contributing its strengths: devices collect data, fog nodes run inference, and the cloud handles training and large-scale analytics. The emergence of lightweight ML frameworks designed specifically for resource-constrained environments has accelerated this trend, making it practical to run sophisticated models on hardware as modest as a Raspberry Pi or an Intel Edison board.
Running ML Inference at the Fog Layer
Deploying machine learning inference at the fog layer requires a combination of model optimization techniques and compatible runtime frameworks. Neural network models trained in the cloud are typically too large and computationally expensive to run on fog hardware without modification. Techniques such as model quantization, pruning, and knowledge distillation reduce model size and computational requirements while preserving acceptable accuracy levels. Quantization converts 32-bit floating-point weights to 8-bit integers, which can reduce model size by 4x and improve inference speed by 2-3x on hardware that supports integer arithmetic. These optimized models can then be deployed to fog nodes using runtime frameworks designed for constrained environments.
Several frameworks have emerged to facilitate ML inference on fog and edge hardware. TensorFlow Lite provides a lightweight runtime for deploying TensorFlow models on devices with limited resources, supporting both CPU and GPU acceleration on compatible hardware. ONNX Runtime offers a framework-agnostic inference engine that can execute models trained in PyTorch, TensorFlow, or other popular frameworks, making it a versatile choice for heterogeneous fog deployments. Kubeflow, an open-source platform built on Kubernetes, streamlines the management of ML pipelines across distributed infrastructure, including fog nodes orchestrated as Kubernetes pods. Each of these tools addresses a different aspect of the deployment challenge, and many organizations use them in combination to build end-to-end inference pipelines that span fog and cloud infrastructure.
The performance benefits of fog-based inference are measurable and consistent across multiple application domains. In manufacturing quality control, fog nodes running computer vision models can inspect products on the assembly line at speeds exceeding 100 frames per second, identifying defects in real time without sending any video data to the cloud. In healthcare automation scenarios, fog gateways process wearable sensor data to detect cardiac arrhythmias within seconds, alerting medical staff before a patient’s condition deteriorates. In smart retail environments, fog-deployed recommendation engines analyze shopper behavior locally and deliver personalized offers to digital displays within the store. These examples illustrate how running inference at the fog layer transforms raw data into immediate action, which is the fundamental value proposition of combining machine learning with fog computing.
Federated Learning Across Fog Nodes
Federated learning represents one of the most promising intersections of fog computing and machine learning, offering a privacy-preserving approach to distributed model training. In traditional ML workflows, raw data from all sources must be aggregated in a central location, typically a cloud data center, where it is used to train a shared model. Federated learning inverts this process by training local models on each participating fog node using only the data available at that node, then transmitting only the model weights or gradients to a central server for aggregation. The raw data never leaves the fog node, which addresses privacy regulations such as GDPR and HIPAA while still enabling collaborative model improvement across a distributed network.
The architecture of a federated learning system built on fog infrastructure typically follows a three-phase cycle. In the first phase, the cloud server distributes a global model to all participating fog nodes. In the second phase, each fog node trains the model locally on its proprietary dataset, adjusting the model weights to reflect the patterns present in its local data. In the third phase, the fog nodes send their updated model parameters back to the cloud server, which aggregates them using algorithms such as Federated Averaging to produce an improved global model. This cycle repeats iteratively until the global model converges to a level of accuracy that satisfies the application requirements. Researchers at Purdue University and Carnegie Mellon have demonstrated that fog-based federated learning can achieve model accuracy within 2-5% of centralized training while reducing data transmission by over 95%.
The practical applications of federated learning on fog nodes span multiple industries with sensitive data requirements. Hospitals can train disease detection models collaboratively without sharing patient records across institutional boundaries, as the FOGNITE architecture demonstrated for smart grid energy prediction using CNN-LSTM models with federated aggregation. Financial institutions can build fraud detection models across branches without centralizing transaction data. Telecommunications companies can optimize network performance models across thousands of base stations while keeping user traffic data localized. The combination of fog computing’s distributed infrastructure and federated learning’s privacy-preserving training creates a new paradigm for AI-powered cancer screening and other sensitive applications where data cannot and should not be centralized.
Fog Computing in Healthcare and Remote Patient Monitoring
Healthcare is one of the most compelling use cases for fog computing, where the combination of latency sensitivity, data privacy, and continuous monitoring creates a perfect environment for fog-based architectures. Remote patient monitoring systems use wearable sensors to track vital signs such as heart rate, blood oxygen levels, glucose concentrations, and movement patterns. These sensors generate a continuous data stream that must be analyzed in near-real time to detect anomalies that could indicate a medical emergency. Fog gateways positioned in patient homes, hospital wards, or ambulances process this data locally, running ML classification models that distinguish between normal fluctuations and clinically significant events. When an anomaly is detected, the fog node can trigger an alert to medical staff within seconds, which is a response time that cloud-only processing cannot reliably achieve. Researchers have demonstrated fog-based unsupervised ML analytics for Parkinson’s disease monitoring using Intel Edison and Raspberry Pi devices as fog computers, analyzing pathological speech data from smartwatches to detect disease progression patterns.
The privacy advantages of fog computing are particularly important in healthcare, where patient data is subject to strict regulatory protections under laws like HIPAA in the United States and GDPR in Europe. By processing sensitive health data on local fog nodes rather than transmitting it to external cloud servers, healthcare organizations can maintain tighter control over data access and reduce the risk of breaches during transmission. Fog-based architectures also support the continuity of care in environments with limited connectivity, such as rural clinics and mobile health units, where patients depend on local processing for real-time health monitoring. The integration of fog computing with AI-driven healthcare documentation systems is creating a new generation of intelligent medical infrastructure that operates reliably regardless of network conditions, and these systems are already showing measurable reductions in emergency response times and hospital readmission rates.
Smart City Applications Powered by Fog Networks
Smart cities represent one of the broadest application domains for fog computing, where distributed networks of sensors and actuators manage everything from traffic flow to energy consumption to public safety. A city-scale IoT deployment can generate petabytes of data daily from traffic cameras, environmental monitors, utility meters, and public transit systems. Processing all of this data in the cloud would require enormous bandwidth and introduce latency that makes real-time city management impractical. Fog nodes distributed across the urban landscape process data locally, enabling traffic signals to adjust in real time based on current conditions, streetlights to dim when no pedestrians are detected, and waste collection routes to optimize based on fill-level sensors in smart bins.
Traffic management is one of the most mature fog computing applications in smart cities, where fog-enabled intersection controllers analyze vehicle and pedestrian flow patterns using computer vision and ML classification models. These controllers coordinate with neighboring intersections through local fog networks to create green wave corridors that reduce congestion and emissions across entire districts. The city of Barcelona, for instance, has implemented smart city technologies that use distributed sensors and local processing to manage parking, lighting, and irrigation, achieving reported annual savings of tens of millions of euros while improving resident quality of life.
Energy grid management is another domain where fog computing delivers substantial value in smart city contexts. Smart grid fog nodes monitor power generation, distribution, and consumption across thousands of endpoints, balancing supply and demand in real time to prevent outages and optimize renewable energy integration. These fog nodes run predictive ML models that forecast energy demand based on weather patterns, time of day, and historical consumption data, enabling grid operators to pre-position resources before demand spikes occur. The FOGNITE architecture, which combines federated learning with reinforcement learning on fog nodes, has demonstrated how fog-based intelligence can enable autonomous energy management decisions at the local level while maintaining coordination with centralized grid control systems.
Public safety and emergency response systems also benefit from fog computing architectures in AI-enabled smart city ecosystems. Fog nodes connected to surveillance cameras can run real-time object detection models that identify accidents, fires, or security threats and automatically dispatch emergency services before a human operator even reviews the footage. Environmental monitoring fog nodes track air quality, noise levels, and water conditions, triggering public health alerts when sensor readings exceed safe thresholds. The distributed nature of fog infrastructure ensures that these safety-critical systems remain operational even if individual nodes fail, because neighboring nodes can absorb the workload and maintain coverage continuity across the city.
Industrial Automation and Manufacturing Use Cases
Industrial environments were among the earliest adopters of fog computing, driven by the need for real-time process control and predictive maintenance in manufacturing facilities. A modern factory floor can contain thousands of sensors monitoring machine vibration, temperature, pressure, torque, and production output at rates of hundreds of readings per second. Fog nodes deployed alongside production lines process this sensor data locally, running anomaly detection models that identify equipment degradation before it leads to unplanned downtime. The economic impact of predictive maintenance enabled by fog computing is significant: unplanned downtime in manufacturing costs an estimated $50 billion annually, and fog-based ML models can detect impending failures days or weeks before they occur.
Quality control represents another high-value application of fog computing in manufacturing and robotics environments. Computer vision models deployed on fog nodes inspect products as they move along the assembly line, identifying surface defects, dimensional deviations, and assembly errors at production speed. These fog-based inspection systems operate at latencies measured in single-digit milliseconds, which is fast enough to trigger reject mechanisms before a defective product advances to the next production stage. The combination of fog computing and ML-powered visual inspection has achieved defect detection rates above 99% in semiconductor manufacturing, where the tolerances are measured in nanometers and the cost of a missed defect can cascade through an entire product batch.
Process optimization is a third area where fog computing creates measurable value in industrial settings. Fog nodes running reinforcement learning models can adjust machine parameters in real time to optimize energy consumption, throughput, and material utilization without requiring human intervention. A cement plant, for example, can use fog-based ML to continuously adjust kiln temperature, rotation speed, and fuel mix based on real-time readings from embedded sensors, reducing energy consumption by 5-10% while maintaining product quality within specifications. These optimization models benefit from the low latency of fog processing, because the feedback loop between sensing, processing, and actuating must be fast enough to keep pace with the physical process being controlled.
Autonomous Vehicles and Transportation Systems
Autonomous vehicles represent perhaps the most latency-sensitive application of fog computing, where the difference between a 10-millisecond and a 100-millisecond response can determine whether a vehicle safely avoids a collision. Self-driving cars generate approximately 1 terabyte of data per hour from cameras, lidar sensors, radar, and GPS modules. Processing all of this data in the cloud is physically impossible at the speed required for real-time driving decisions, which is why autonomous vehicles rely on onboard fog computing systems to run perception, planning, and control algorithms locally. These onboard fog nodes execute multiple ML models simultaneously, including object detection for pedestrians and obstacles, lane tracking for navigation, and behavior prediction for anticipating the actions of other road users. Organizations developing autonomous driving systems depend on fog architectures to meet the strict latency and reliability requirements of safety-critical vehicle operations.
Beyond individual vehicles, fog computing enables vehicle-to-infrastructure communication that enhances the safety and efficiency of entire transportation networks. Fog nodes installed at intersections, toll plazas, and highway on-ramps process data from multiple vehicles simultaneously, coordinating traffic flow and providing real-time hazard warnings to approaching drivers. These infrastructure fog nodes can aggregate data from dozens of vehicles to identify emerging traffic patterns and relay guidance to connected cars through low-latency local networks, reducing accident rates and improving fuel efficiency across the transportation system. Public transit systems also benefit from fog computing, with AI-powered bus transportation networks using fog nodes to optimize routes, predict passenger demand, and coordinate schedules in real time without depending on continuous cloud connectivity.
The Security Risks of Distributed Fog Architectures
The distributed nature of this architecture introduces security challenges that do not exist in centralized cloud environments. Fog nodes are physically dispersed across diverse locations, including factory floors, roadside cabinets, retail stores, and hospital corridors, which makes them more vulnerable to physical tampering than cloud servers housed in secured data centers. An attacker who gains physical access to a fog node could extract sensitive data, inject malicious code, or compromise the integrity of ML models running on that node. The sheer number of fog nodes in a large deployment, sometimes numbering in the thousands, makes it impractical to apply the same level of physical security protection that a centralized data center receives.
Network-level attacks also pose significant risks in fog environments. Fog nodes communicate with both edge devices and cloud servers across local and wide-area networks, creating multiple attack surfaces for man-in-the-middle interceptions, denial-of-service attacks, and unauthorized data exfiltration. Because fog nodes often run on commodity hardware with limited computational resources, they may lack the processing power to implement the same encryption and intrusion detection capabilities that cloud servers provide. The expanded attack surface of fog computing, where nodes are positioned between edge devices and the cloud, presents a security challenge that organizations must address through layered defense strategies. Researchers studying AI and cybersecurity approaches have proposed using ML-based anomaly detection models running on fog nodes themselves to identify and respond to attacks in real time, turning the fog layer into both a processing platform and a security monitoring tool.
Authentication and trust management across fog nodes present additional challenges. In a cloud environment, all services operate within a controlled trust boundary managed by the cloud provider. In a fog environment, nodes may be owned and operated by different entities, and the level of trust between nodes cannot be assumed. Malicious or compromised fog nodes could inject false data into the processing pipeline, corrupt ML model parameters during federated learning aggregation, or redirect network traffic to unauthorized destinations. Establishing mutual authentication protocols, certificate-based trust chains, and secure boot mechanisms for fog nodes are essential steps that organizations must take to mitigate these risks, but implementing these measures at scale across a heterogeneous fog deployment remains an active area of research.
Privacy and Data Governance Challenges
This approach offers privacy advantages over cloud-only architectures by keeping sensitive data close to its source, but it also introduces new governance complexities that organizations must navigate. When data is processed on fog nodes located in different jurisdictions, questions arise about which privacy regulations apply, who is responsible for data protection, and how compliance can be verified across a distributed infrastructure. A multinational manufacturer with fog nodes in facilities across Europe, Asia, and North America must ensure that each node complies with the local data protection laws of its host country, which may include GDPR, the Chinese Personal Information Protection Law, or California’s CCPA. Managing this patchwork of regulatory requirements across hundreds of distributed fog nodes is significantly more complex than ensuring compliance within a single cloud data center.
Data lifecycle management on fog nodes requires careful planning to prevent unauthorized data retention and ensure timely deletion. Fog nodes may cache sensitive data locally for processing, and if that data is not properly managed, it could persist on the node’s storage long after it is no longer needed. Organizations must implement automated data retention policies on every fog node, define clear ownership and access controls for locally processed data, and maintain audit trails that document how data flows through the fog infrastructure. The challenge intensifies when fog nodes process data from AI in smart home devices or personal wearables, where the data subjects are individual consumers with expectations of privacy that extend beyond regulatory minimums.
Ethical Considerations for AI at the Network Edge
Deploying machine learning models at the fog layer raises ethical questions that differ from those encountered in cloud-based AI deployments. When an ML model makes a decision locally on a fog node, that decision may not be logged, audited, or reversible in the same way as a decision made by a cloud service with comprehensive monitoring infrastructure. A fog-deployed facial recognition model at a retail store entrance, for example, may make access control decisions that affect individuals without any human oversight or appeal mechanism. The opacity of local ML decision-making creates accountability gaps that organizations must address through transparent policies, regular model audits, and clear escalation procedures for contested decisions.
Bias in fog-deployed ML models represents another ethical concern, particularly when models are trained on data from one context and deployed in another. A predictive maintenance model trained on data from a factory in Germany may not perform accurately when deployed on fog nodes in a factory in Brazil that uses different equipment, operates under different environmental conditions, and follows different production schedules. If the model’s predictions are biased by its training data, it could lead to unnecessary maintenance shutdowns, missed defect detections, or unsafe operating conditions. Organizations must validate fog-deployed models against local data before relying on them for critical decisions, and they must implement ongoing monitoring to detect performance degradation or bias drift over time.
The distribution of AI decision-making across fog nodes also raises questions about consent and transparency for individuals whose data is being processed. Employees working in a fog-instrumented facility may not be aware that their movements, productivity patterns, and interactions are being analyzed by local ML models. Residents of a smart city may not know that fog nodes in their neighborhood are processing data from surveillance cameras, environmental sensors, and traffic monitors. Organizations and municipalities have an ethical obligation to inform data subjects about the existence and purpose of fog-based AI systems, provide mechanisms for opting out where feasible, and ensure that the benefits of fog-powered intelligence are distributed equitably rather than concentrated among those with the resources to deploy and control the infrastructure.
Energy Efficiency and Sustainability in Fog Environments
This approach offers meaningful energy efficiency advantages over cloud-only architectures by reducing the volume of data that must be transmitted across wide-area networks and processed in power-hungry data centers. Data centers consume approximately 1-2% of global electricity, and a significant portion of that energy goes toward cooling the servers that process IoT data. By shifting routine processing tasks to fog nodes that operate at much lower power levels, organizations can reduce their overall energy footprint while maintaining or improving the speed of data analytics. A fog gateway consuming 10 watts of power can handle the data filtering and preliminary ML inference tasks that would otherwise require a cloud server consuming 500 watts or more, creating a multiplicative efficiency gain across large deployments.
The environmental sustainability argument for fog computing extends beyond direct energy savings to include reductions in network infrastructure load and electronic waste. Fog nodes often run on repurposed hardware such as existing routers, switches, and industrial controllers, which extends the useful life of equipment that might otherwise be discarded. By distributing workloads across a network of modest devices rather than concentrating them in a few massive data centers, fog computing also reduces the cooling requirements and physical infrastructure demands that make data centers such significant consumers of water and energy. For organizations pursuing sustainability goals while scaling their IoT and ML capabilities, fog computing offers a path that aligns cloud computing techniques with environmental responsibility.
The Fog Computing Market and Growth Projections
This technology is experiencing rapid growth driven by the convergence of IoT expansion, AI-at-the-edge demand, and enterprise digital transformation initiatives. According to a 2026 report by ResearchAndMarkets.com, the global fog computing market is projected to expand from USD 256.81 million in 2025 to USD 611.59 million by 2031, registering a CAGR of 15.56%. Other market research firms project even more aggressive growth trajectories: Fortune Business Insights valued the market at USD 1.09 billion in 2025 with a CAGR of 51.72% through 2034, reflecting different methodological approaches to defining market boundaries. Regardless of which projection proves most accurate, the directional trend is clear: organizations across every industry are investing in fog computing infrastructure at an accelerating rate.
The integration of artificial intelligence and machine learning, sometimes referred to as Fog AI, is fundamentally reshaping the market by shifting computational logic from centralized cloud environments to local fog nodes. This trend addresses critical privacy and latency requirements in data-intensive applications, allowing fog nodes equipped with neural processing units to execute real-time inference without relying on continuous upstream connectivity. According to the Eclipse Foundation’s 2024 developer survey, 75% of developers actively used open-source technologies for their IoT and edge solutions, indicating a strong ecosystem of tools and frameworks supporting fog computing adoption. The Asia-Pacific region is recording the fastest growth in fog computing adoption, driven by large-scale smart city projects in China, India, Japan, and South Korea, alongside rapid industrial automation in manufacturing-heavy economies.
North America remains the largest market for fog computing services in absolute terms, with U.S.-based organizations deploying fog architectures to support industrial automation, smart infrastructure, and connected healthcare systems. The maturity of enterprise digitalization in the United States, combined with early adoption of edge technologies by companies like Cisco, Dell, and Intel, has created a competitive landscape where fog computing is transitioning from experimental pilot projects to production-scale deployments. European adoption is growing steadily as well, driven by strong data privacy regulations under GDPR that incentivize local data processing and by ambitious smart city programs in cities like Barcelona, Amsterdam, and Copenhagen.
What Comes Next for Fog Computing and Distributed AI
The convergence of fog computing with federated learning is creating a new paradigm that researchers at Purdue University have termed “fog learning,” which extends federated learning along three dimensions: network architecture, device heterogeneity, and geographic proximity. Fog learning goes beyond conventional federated learning by enabling devices to offload data processing tasks to each other within the fog layer, optimizing these decisions to balance costs associated with processing, offloading, and communication. This approach is particularly relevant for 5G and 6G wireless networks, where the density of connected devices and the diversity of their computational capabilities demand more flexible distributed learning frameworks than traditional cloud-centric training can provide.
Hybrid fog-cloud architectures are gaining traction as organizations recognize that the optimal computing strategy is not fog or cloud but fog and cloud working in concert. Hybrid fog nodes, which can dynamically allocate workloads between local processing and cloud offloading based on current network conditions and task urgency, captured approximately 39.6% of the fog computing market share in 2025 according to market research. These hybrid nodes represent a maturation of the fog computing concept, moving from static deployment models where workloads are permanently assigned to specific processing tiers to dynamic models where workloads flow to the most appropriate processing location in real time.
The development of specialized hardware for fog-based AI inference is another trend that will shape the market in the coming years. Companies like Ambiq have identified a USD 12.8 billion market opportunity for edge AI solutions across industrial and consumer applications, and are designing ultra-low-power processors that can run neural network inference at milliwatt-level energy consumption. These chips enable fog nodes to execute sophisticated ML models without the power and cooling infrastructure that traditional processors require, making it practical to deploy AI-capable fog nodes in environments where electrical power is limited or expensive. As this hardware matures, the barrier to deploying ML at the fog layer will continue to drop, enabling smaller organizations and less resource-rich environments to benefit from fog-based intelligence.
The standardization landscape for fog computing is also evolving, with the IEEE and the OpenFog Consortium (now merged with the Industrial Internet Consortium) developing reference architectures and interoperability standards that will make it easier for organizations to build multi-vendor fog deployments. The 10th IEEE International Conference on Fog and Edge Computing (ICFEC 2026), held in Sydney in conjunction with CCGrid 2026, highlighted the ongoing academic and industry investment in addressing the technical challenges of fog computing, including resource management, security, and distributed ML model lifecycle management. As these standards mature and the ecosystem of fog-compatible tools expands, fog computing will transition from a specialized technology deployed by early adopters to a standard component of enterprise IT architecture, embedded alongside cloud and edge computing in every organization’s infrastructure strategy.
How to Deploy Machine Learning Models on Fog Infrastructure
Step 1: Assess Your Latency and Data Requirements
Before deploying ML models on fog infrastructure, organizations must evaluate which workloads genuinely benefit from fog-layer processing versus those that can remain in the cloud. Begin by cataloging all data sources in your IoT deployment, measuring the volume and velocity of data each source generates, and identifying which applications require sub-100-millisecond response times. Workloads that involve real-time anomaly detection, safety-critical decision-making, or privacy-sensitive data processing are strong candidates for fog deployment. Workloads that involve batch analytics, long-term trend analysis, or model training should typically remain in the cloud where computational resources are abundant and scalable.
Step 2: Select Your Fog Hardware Platform
Choose fog node hardware that matches your computational requirements and deployment environment. Options range from industrial-grade gateways with integrated GPUs to single-board computers like the NVIDIA Jetson Nano for lighter workloads. Consider factors including operating temperature range, power consumption, connectivity options, and available accelerators for ML inference. For industrial environments, ruggedized fog nodes from vendors like Dell, Cisco, and Advantech provide reliability in harsh conditions with vibration resistance and extended temperature tolerance.
# Example: Check available GPU resources on a Jetson Nano fog node
sudo tegrastats
# Output shows GPU utilization, memory usage, and temperatureStep 3: Optimize Your ML Model for Fog Deployment
Train your model in the cloud using your preferred framework (TensorFlow, PyTorch, or similar), then optimize it for deployment on resource-constrained fog hardware. Apply quantization to reduce model size and inference latency, and test the quantized model against your accuracy requirements.
# Example: Quantizing a TensorFlow model for fog deployment
import tensorflow as tf
# Load the trained model
converter = tf.lite.TFLiteConverter.from_saved_model('saved_model_dir')
converter.optimizations = [tf.lite.Optimize.DEFAULT]
# Post-training quantization reduces model size by ~4x
tflite_model = converter.convert()
# Save the quantized model for fog node deployment
with open('model_fog.tflite', 'wb') as f:
f.write(tflite_model)Pro Tip: Always benchmark both the full-precision and quantized models on your target fog hardware before production deployment, as accuracy degradation varies significantly depending on model architecture and input data characteristics.
Step 4: Deploy the Model Using a Lightweight Runtime
Install a lightweight ML runtime on your fog node and configure it to load and execute your optimized model. TensorFlow Lite and ONNX Runtime are the most widely supported options for resource-constrained deployment environments.
# Example: Running inference on a fog node with TensorFlow Lite
import numpy as np
import tflite_runtime.interpreter as tflite
# Load the quantized model
interpreter = tflite.Interpreter(model_path='model_fog.tflite')
interpreter.allocate_tensors()
# Get input and output details
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
# Run inference on sensor data
sensor_data = np.array([[23.5, 65.2, 1013.25]], dtype=np.float32)
interpreter.set_tensor(input_details[0]['index'], sensor_data)
interpreter.invoke()
prediction = interpreter.get_tensor(output_details[0]['index'])
print(f"Prediction: {prediction}")Step 5: Set Up Data Pipelines Between Fog and Cloud
Configure your fog node to pre-process incoming sensor data, run local inference, and forward summarized results or anomaly flags to your cloud analytics platform. Use MQTT or Apache Kafka for reliable message delivery between fog nodes and cloud services.
# Example: Install Mosquitto MQTT broker on a fog node
sudo apt-get update
sudo apt-get install -y mosquitto mosquitto-clients
sudo systemctl enable mosquitto
sudo systemctl start mosquittoWarning: Ensure that all data transmissions between fog nodes and cloud servers are encrypted using TLS 1.3 or later, as unencrypted fog-to-cloud communication represents a significant security vulnerability.
Step 6: Implement Monitoring and Model Updates
Deploy monitoring agents on each fog node to track inference latency, prediction accuracy, hardware utilization, and connectivity status. Establish automated pipelines that retrain cloud-based models on newly collected fog data and push updated model versions to fog nodes during scheduled maintenance windows. Continuous monitoring ensures that fog-deployed models maintain their accuracy over time as input data distributions shift due to seasonal changes, equipment aging, or environmental factors.
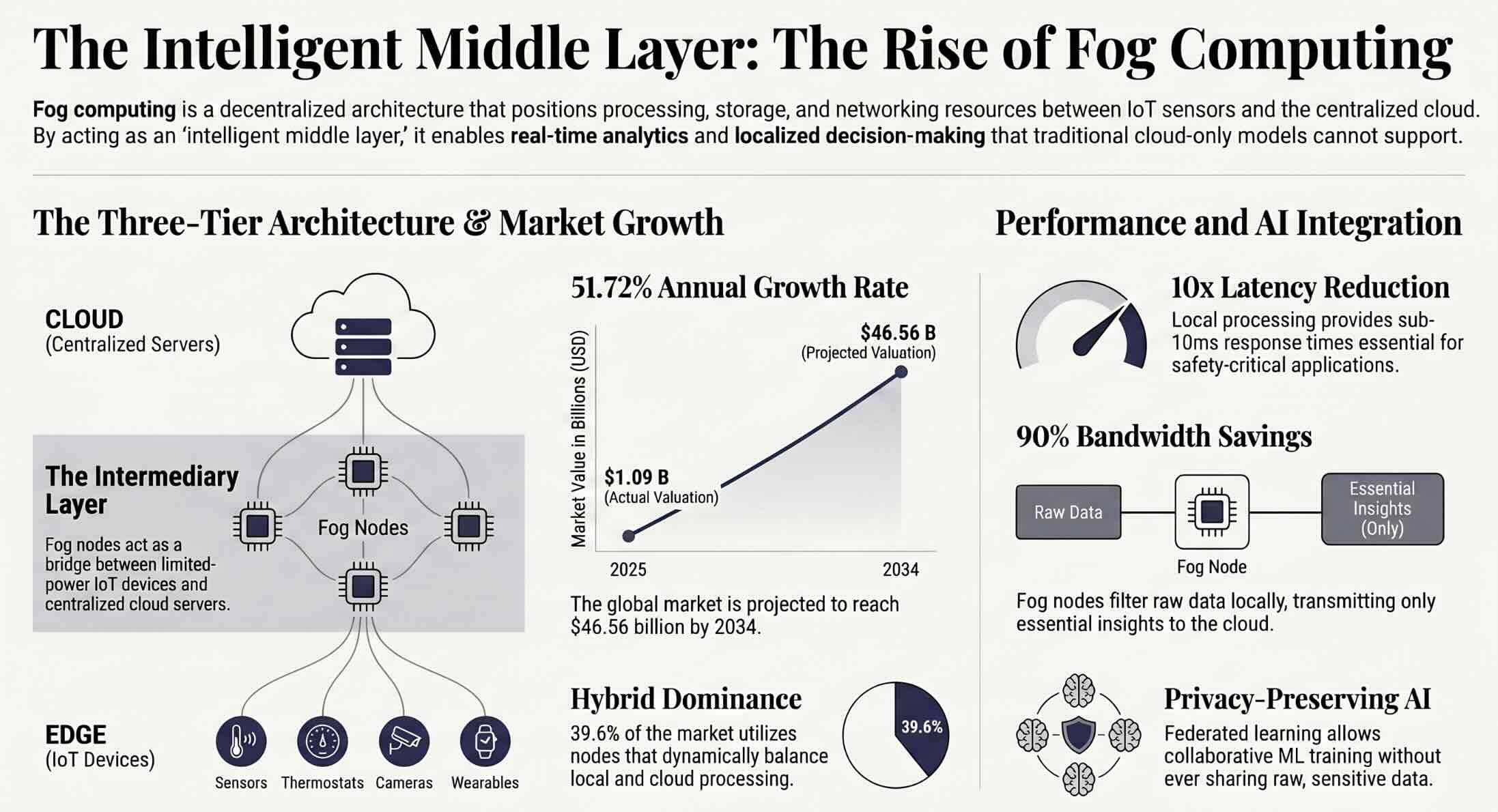
Key Insights on Fog Computing and Machine Learning
- The global fog computing market is projected to grow from USD 1.09 billion in 2025 to USD 46.56 billion by 2034, reflecting a CAGR of 51.72% driven by IoT expansion and edge AI demand.
- Hybrid fog nodes captured approximately 39.6% of the fog computing market share in 2025, indicating that organizations prefer flexible architectures that dynamically allocate workloads between local and cloud processing.
- According to the Eclipse Foundation’s 2024 developer survey, 75% of developers actively used open-source technologies for their IoT and edge solutions, signaling strong ecosystem support for fog computing development tools.
- Researchers demonstrated that fog-based federated learning can reduce data transmission by over 95% compared to centralized training while maintaining model accuracy within 2-5% of cloud-trained equivalents.
- Ambiq identified a USD 12.8 billion market opportunity for edge AI solutions across industrial and consumer applications, accelerating the development of ultra-low-power processors for fog-based ML inference.
- The FedFog simulation framework demonstrated that combining federated learning with fog computing accelerates model convergence, reduces latency, and improves energy efficiency compared to conventional training setups.
- An estimated 62% of enterprise data is expected to be processed on edge and fog devices in the near future, up from approximately 10% in 2021, marking a fundamental shift in computing architecture.
- The FOGNITE architecture demonstrated that combining federated learning, reinforcement learning, and digital twin validation on fog nodes can enable autonomous local decision-making for smart grid energy management.
The data paints a clear picture of fog computing transitioning from an experimental concept to a production-ready infrastructure layer. Market projections consistently point toward exponential growth, with multiple research firms forecasting CAGR rates above 40% through the end of the decade. The dominance of hybrid fog nodes in the market confirms that organizations are not choosing between fog and cloud; they are integrating both into unified architectures. Open-source ecosystem maturity, evidenced by high developer adoption rates, reduces the barrier to entry for organizations exploring fog computing. The convergence of fog computing with federated learning addresses the twin challenges of AI scalability and data privacy simultaneously. Energy efficiency gains from localized processing align fog computing with growing corporate sustainability mandates.
Fog Computing Compared: Traditional Cloud vs. Fog vs. Edge for Machine Learning
| Dimension | Cloud Computing | Fog Computing | Edge Computing |
|---|---|---|---|
| Transparency | Centralized dashboards with full visibility into processing pipelines | Partial visibility across distributed nodes; requires aggregation tools | Limited visibility; device-level logs only |
| Participation | Cloud provider manages infrastructure; user manages applications | Shared responsibility between network operators and application owners | Device owner controls all processing |
| Trust | High trust within provider’s data center boundary | Variable trust across heterogeneous, geographically dispersed nodes | Trust limited to individual device integrity |
| Decision Making | Batch-oriented; suitable for non-time-critical ML training and analytics | Near-real-time; enables sub-100ms inference for time-sensitive workloads | Real-time; on-device decisions with zero network dependency |
| Misinformation Risk | Low risk due to centralized model management and version control | Moderate risk from compromised fog nodes injecting false data or corrupted model weights | Higher risk from device tampering with no external validation |
| Service Delivery | Globally accessible; scales elastically but introduces latency | Locally optimized; reduces latency but requires distributed management | Ultra-local; fastest response but limited to single-device capabilities |
| Accountability | Clear accountability chain through cloud provider SLAs | Diffuse accountability across multiple node operators and jurisdictions | Accountability rests entirely with device owner and manufacturer |
How Leading Organizations Are Using Fog Computing in Practice
Cisco’s Smart City Fog Deployment in Barcelona
Cisco partnered with the city of Barcelona to implement a fog computing architecture across urban infrastructure systems including smart lighting, parking management, and environmental monitoring. The deployment uses fog nodes installed at street level to process data from thousands of sensors locally, reducing the volume of data transmitted to cloud servers by an estimated 40% while enabling real-time responsiveness for traffic and environmental management. Critics note that the initiative’s reliance on proprietary Cisco hardware creates vendor lock-in risks that could increase long-term costs and limit interoperability, as reported by Smart Cities World.
GE Digital’s Predix Fog Platform for Industrial Manufacturing
GE Digital deployed its Predix platform using fog computing architecture across manufacturing and energy facilities to enable predictive maintenance and real-time process optimization. The fog-based system processes vibration, temperature, and pressure sensor data on local Predix Edge nodes, running ML anomaly detection models that according to GE’s industrial reports have reduced unplanned downtime by up to 20% in participating facilities. The limitation of this approach is the significant upfront investment required for Predix-compatible hardware and software licensing, which has restricted adoption to large enterprises with substantial capital budgets.
University of Rhode Island’s FogLearn Framework for Telehealth
Researchers at the University of Rhode Island developed FogLearn, a framework that deploys unsupervised machine learning analytics on Raspberry Pi and Intel Edison fog devices for smart telehealth applications. The system analyzes physiological data from wearable sensors worn by patients with Parkinson’s disease, using fog-based clustering algorithms to detect disease progression patterns without transmitting raw patient data to external servers. While the results demonstrated promising accuracy for low-resource clinical ML, the study acknowledged that the limited processing power of consumer-grade fog devices restricts the complexity of models that can be deployed, particularly for applications requiring deep neural network architectures.
Lessons From Fog Computing Deployments Across Industries
Case Study: Siemens MindSphere Fog Architecture for Factory Automation
Siemens faced the challenge of processing massive sensor data volumes from connected factory equipment across hundreds of global manufacturing sites without overwhelming centralized cloud infrastructure. The company deployed its MindSphere IoT platform using fog computing nodes at the factory level, which run predictive maintenance ML models locally and transmit only aggregated insights to the cloud. According to Siemens Digital Industries, the fog-based architecture reduced data transmission costs by 60% and enabled sub-second response times for quality control alerts on production lines. Critics point out that MindSphere’s effectiveness depends heavily on consistent sensor calibration across sites, and that model accuracy can degrade significantly when deployed in facilities with equipment configurations that differ from the training dataset, highlighting the ongoing challenge of transfer learning in heterogeneous fog environments.
Case Study: Samsung SmartThings Fog-Enabled Smart Home Platform
Samsung developed its SmartThings platform to use fog computing principles for processing smart home device data locally on hub devices rather than routing all data through Samsung’s cloud infrastructure. The hub acts as a fog node that processes inputs from smart home sensors and actuators, runs automation rules locally, and forwards only necessary data to the cloud for remote access and long-term analytics. Samsung reported that local fog processing reduced response times for home automation commands from an average of 800 milliseconds (cloud round trip) to under 50 milliseconds (local fog processing), according to Samsung Developer documentation. The limitation is that the hub’s limited processing power constrains the complexity of ML models that can run locally, and users who lose internet connectivity can still control local devices but lose access to cloud-dependent features like voice assistants and remote monitoring.
Case Study: AWS Greengrass for Agricultural IoT Fog Deployments
Amazon Web Services developed AWS Greengrass to extend cloud computing capabilities to fog and edge devices in environments with intermittent connectivity, with agriculture emerging as a key use case. Farmers deploy Greengrass-enabled fog devices in fields to process drone imagery, soil sensor data, and weather station readings locally, running ML inference models that classify crop health and predict irrigation needs in real time. According to AWS case studies, agricultural deployments using Greengrass fog nodes reduced cloud data transfer costs by up to 70% while maintaining crop classification accuracy above 95%. The challenge remains that AWS Greengrass requires technical expertise to configure and maintain, which creates an adoption barrier for smaller farming operations that lack dedicated IT staff, and the reliance on AWS ecosystem tools creates vendor dependency that limits flexibility.
Frequently Asked Questions About Fog Computing and Machine Learning
Fog computing is a distributed architecture that brings data processing and storage closer to IoT devices at the network edge. It acts as a middle layer between sensors and the cloud, reducing delays and saving bandwidth. The approach enables faster, more efficient data analytics for connected devices.
Edge computing processes data directly on the device that generates it, such as a sensor or camera. Fog computing processes data on intermediate nodes like gateways or local servers within the local area network. Fog nodes can coordinate data from multiple edge devices simultaneously, providing a broader processing capability.
The primary benefit is dramatically reduced latency for AI inference tasks. Machine learning models deployed on fog nodes can deliver predictions in single-digit milliseconds. This speed is essential for safety-critical applications like autonomous vehicles and industrial process control.
Yes, optimized ML models can run efficiently on fog hardware using lightweight runtimes like TensorFlow Lite and ONNX Runtime. Model optimization techniques such as quantization and pruning reduce computational requirements while preserving accuracy. Even modest hardware like a Raspberry Pi can execute inference tasks for many practical applications.
Federated learning trains ML models across distributed devices without centralizing raw data. Fog nodes participate in this process by training local models and sharing only model parameters with a central server. This preserves data privacy while enabling collaborative model improvement across the fog network.
Healthcare, manufacturing, transportation, energy, and smart city infrastructure are the leading adopters of fog computing. Each of these industries generates massive volumes of time-sensitive data from distributed IoT sensors. Fog computing enables real-time processing that cloud-only architectures cannot deliver at the required speed.
Fog computing introduces both security advantages and challenges compared to cloud-only architectures. Local processing keeps sensitive data closer to its source, reducing exposure during transmission. The distributed nature of fog nodes creates a larger attack surface that requires layered security strategies including encryption, authentication, and ML-based anomaly detection.
Fog nodes filter, aggregate, and analyze raw sensor data locally before forwarding only essential information to the cloud. This process can reduce the volume of data transmitted over wide-area networks by 40-90%. The bandwidth savings translate directly into lower costs and reduced network congestion.
Fog nodes can run on a wide range of hardware, from industrial gateways and network routers to single-board computers and specialized edge servers. Many fog deployments repurpose existing network infrastructure as fog nodes. Newer deployments use purpose-built fog hardware with integrated GPU or neural processing unit accelerators.
Fog nodes deployed across urban infrastructure process data from traffic cameras, environmental sensors, utility meters, and transit systems locally. This local processing enables real-time traffic management, energy grid optimization, and public safety monitoring. Smart cities like Barcelona have demonstrated measurable cost savings and service improvements through fog-based architectures.
Fog AI refers to the integration of artificial intelligence and machine learning capabilities into fog computing infrastructure. It involves deploying trained ML models on fog nodes for real-time inference and enabling federated learning across distributed fog devices. The concept represents the convergence of localized computing with intelligent data analysis.
Fog computing complements cloud computing rather than replacing it. The cloud handles large-scale model training, historical data analytics, and workloads that benefit from elastic scalability. Fog computing handles real-time inference, latency-sensitive processing, and privacy-sensitive data analytics. Most organizations deploy both in a hybrid architecture.
Fog computing is constrained by the processing power and storage capacity of distributed fog nodes. Managing and securing a large network of heterogeneous fog devices adds operational complexity. The technology also requires specialized skills for deployment and maintenance that many organizations are still developing.
Autonomous vehicles use onboard fog computing systems to process data from cameras, lidar, radar, and GPS sensors in real time. These fog nodes run multiple ML models simultaneously for object detection, lane tracking, and behavior prediction. Vehicle-to-infrastructure fog nodes at intersections further enhance safety by coordinating traffic flow across connected vehicles.
The fog computing market is growing rapidly, with projections ranging from USD 611 million by 2031 to USD 46.56 billion by 2034 depending on the research methodology and market definition used. Growth is driven by IoT device proliferation, demand for edge AI capabilities, and enterprise digital transformation initiatives across all major industries.