
Introduction
Natural language processing stands at the center of how modern machines interpret human speech, text, and meaning across every digital platform. The global NLP market is projected to reach USD 45.74 billion in 2026, growing at a compound annual growth rate of 19.7 percent through 2034. Every time you ask a voice assistant to set a timer, or a chatbot resolves your complaint in seconds, natural language processing is working behind the scenes. NLP combines computer science, artificial intelligence, and linguistics to give machines the ability to read, listen, and respond in human language. This technology has moved from research labs into the daily workflows of healthcare systems, banks, retailers, and governments around the world. Understanding what NLP is and how it works is no longer optional for anyone building, managing, or investing in technology today. The stakes are enormous because language remains the primary way humans share knowledge, make decisions, and build trust.
Key Questions
What is NLP in simple terms?
Natural language processing is a branch of artificial intelligence that enables computers to understand, interpret, and generate human language through text and speech analysis.
How does NLP work?
NLP works by combining computational linguistics, machine learning, and deep learning to break human language into structured data that machines can process, analyze, and respond to meaningfully.
Why is NLP important in 2026?
NLP drives chatbots, voice assistants, sentiment analysis, and automated content generation, powering a market worth over forty-five billion dollars and transforming every major industry.
Key Takeaways
- Ethical risks including bias, data privacy concerns, and transparency gaps require careful governance as NLP systems become more autonomous.
- Natural language processing enables machines to read, hear, and respond to human language by combining AI, linguistics, and computer science into practical systems.
- NLP powers everyday tools such as voice assistants, translation apps, spam filters, and customer service chatbots across all major industries.
- The NLP market exceeds forty-five billion dollars in 2026, with healthcare, finance, and telecom leading adoption worldwide.
Table of contents
- Introduction
- Key Questions
- Key Takeaways
- Understanding Natural Language Processing
- How Computers Learn to Understand Human Language
- The Science Behind Natural Language Processing
- A Brief History of Language and Machines
- Core Techniques That Power NLP Systems
- How Tokenization, Parsing, and Semantic Analysis Work Together
- How Does Natural Language Processing (NLP) Work?
- How NLP Differs from Traditional Programming
- Real Applications You Already Use Every Day
- NLP in Healthcare and Medical Research
- Financial Services and Fraud Detection Through NLP
- Building Your First NLP Pipeline
- Choosing the Right NLP Framework and Tools
- Transformer Models and the Rise of Large Language Models
- Bias, Fairness, and Ethical Concerns in Language AI
- Data Privacy and Security Challenges
- Why Businesses Are Investing Billions in NLP
- Measuring NLP Performance and Accuracy
- When NLP Fails and What It Means
- The Future of Language AI Beyond 2026
- How NLP Powers Generative AI and Chatbots
- Cross-Language Understanding and Multilingual NLP
- Key Insights
- Real-World Examples
- Case Studies
- Frequently Asked Questions
- References
Understanding Natural Language Processing
Natural language processing is a subfield of artificial intelligence focused on enabling computers to understand, interpret, and generate human language in both text and speech formats. NLP combines computational linguistics, statistical modeling, machine learning, and deep learning to analyze the structure and meaning of language beyond simple keyword matching. The technology bridges the gap between how humans naturally communicate and how machines process information.
How Computers Learn to Understand Human Language
Computers do not inherently understand words, grammar, or context the way human brains do. Instead, NLP systems rely on mathematical models that convert raw text and speech into numerical representations machines can analyze. These models learn patterns from massive datasets containing millions of sentences, documents, and conversations collected from real-world sources. The process begins with breaking language down into smaller units like words, phrases, and characters that algorithms can process systematically. Machine learning allows these systems to improve their accuracy over time by identifying patterns across billions of linguistic examples. Each interaction refines the model, making predictions about word meaning, sentence structure, and user intent progressively more reliable. Understanding how artificial intelligence works provides essential context for grasping the foundations of NLP technology.
Statistical methods initially dominated the field, relying on probability calculations to determine likely word sequences and meanings. Researchers trained early NLP models on labeled datasets where human annotators marked parts of speech, sentiment categories, and named entities by hand. These supervised learning approaches produced workable results for narrow tasks like spam detection and basic text classification. Deep learning changed the landscape by introducing neural networks capable of learning complex language features without manual labeling. Today, self-supervised models trained on enormous text corpora can transfer their knowledge to hundreds of downstream tasks. The shift from rule-based systems to data-driven models represents the single largest leap in NLP capability over the past two decades.
The Science Behind Natural Language Processing
NLP sits at the intersection of three scientific disciplines that each contribute essential tools for understanding human communication. Computer science provides the algorithms, data structures, and computational frameworks needed to process language at scale across distributed systems. Linguistics supplies the theoretical understanding of syntax, semantics, morphology, and pragmatics that govern how meaning is constructed in human speech. Artificial intelligence ties these disciplines together by creating systems that learn and adapt rather than simply follow static rules. Each discipline alone cannot solve the challenge of language understanding, but their combination creates powerful tools. The convergence of these fields has accelerated rapidly since the introduction of transformer architectures in 2017. Modern NLP research draws equally from mathematical optimization theory, cognitive science, and engineering practice.
At its core, NLP processes language through a pipeline that begins with raw input and ends with structured output a machine can act upon. The first stage involves tokenization, which splits continuous text into discrete tokens such as words or subwords for downstream analysis. Syntactic analysis follows, parsing sentence structure to identify grammatical relationships between subjects, verbs, and objects. Semantic analysis goes deeper by examining what words and sentences actually mean within a given context or domain. Named entity recognition identifies specific people, organizations, dates, and locations within unstructured text for structured data extraction. Coreference resolution determines when different words in a text refer to the same real-world entity, preventing confusion.
Pragmatic analysis adds another layer by interpreting language based on context, speaker intent, and shared knowledge between communicators. Discourse analysis examines how sentences relate to each other across paragraphs and documents to maintain coherence in longer texts. Sentiment analysis evaluates the emotional tone behind words, classifying text as positive, negative, or neutral based on linguistic cues. Each layer of analysis builds upon the previous one, creating increasingly nuanced understanding that approaches human-level comprehension. These scientific foundations enable practical applications ranging from simple spell-checkers to complex dialogue systems that hold natural conversations. The science of NLP continues evolving as researchers discover new ways to represent and process the infinite complexity of human language.
A Brief History of Language and Machines
The quest to make machines understand human language began in the 1950s with Alan Turing’s foundational question about whether machines could think. Early NLP systems relied entirely on hand-coded rules and dictionaries, attempting to capture language through explicit grammar definitions. The Georgetown-IBM experiment in 1954 demonstrated automatic translation of Russian sentences into English using six grammar rules and 250 vocabulary words. Progress was painfully slow because human language proved far more complex and ambiguous than early researchers anticipated. Decades of limited funding and slow computational advances created what researchers called the “AI winters” of NLP development. Rule-based approaches dominated through the 1980s, producing systems that worked in narrow domains but failed to generalize across topics or languages.
The statistical revolution in the 1990s transformed NLP by replacing rigid rules with probabilistic models trained on actual language data. Researchers at IBM pioneered statistical machine translation methods that calculated the probability of word alignments between language pairs using parallel corpora. The introduction of support vector machines and conditional random fields brought powerful machine learning algorithms into mainstream NLP practice. The real breakthrough arrived with deep learning in the 2010s, when neural networks began outperforming every previous approach on major benchmarks. Google’s Word2Vec in 2013 showed that words could be represented as dense numerical vectors capturing semantic relationships between concepts. The 2017 transformer architecture paper fundamentally reshaped the field, leading directly to models like BERT, GPT, and every modern large language model.
Core Techniques That Power NLP Systems
Every modern NLP system depends on a set of foundational techniques that transform unstructured human language into structured machine-readable data. Text preprocessing cleans raw input by removing noise, normalizing spelling variations, and converting everything to a consistent format before analysis begins. Stop word removal eliminates common words like “the,” “is,” and “at” that carry little semantic value for many analytical tasks. Stemming and lemmatization reduce words to their root forms, allowing algorithms to recognize that “running,” “runs,” and “ran” share a common base. These preprocessing steps dramatically improve model performance by reducing vocabulary size and eliminating irrelevant variation from the dataset. Effective preprocessing requires careful judgment because aggressive filtering can remove context that matters for certain applications. The choice of preprocessing strategy depends heavily on the specific NLP task, the language being processed, and the domain of application.
Part-of-speech tagging assigns grammatical labels to each word in a sentence, identifying nouns, verbs, adjectives, and other syntactic categories automatically. Dependency parsing maps the grammatical relationships between words, revealing which words modify, depend on, or govern other words in a sentence. Constituency parsing creates hierarchical tree structures that show how words group into phrases and clauses within complex sentences. These syntactic techniques allow machines to understand that “the dog bit the man” means something fundamentally different from “the man bit the dog.” Named entity recognition identifies and classifies proper nouns into categories like people, organizations, locations, dates, and monetary values. Relation extraction discovers connections between identified entities, building structured knowledge from unstructured text automatically.
Semantic techniques go beyond syntax to capture meaning, context, and intent embedded within language at multiple levels. Word embeddings represent individual words as dense numerical vectors in high-dimensional space, placing semantically similar words closer together. Learning about word embeddings in NLP reveals how these representations capture analogies, similarities, and relationships between concepts mathematically. Sentence embeddings extend this concept to encode entire sentences as single vectors, enabling comparison and clustering of complete thoughts. Topic modeling algorithms discover abstract themes that run through large document collections without requiring human labeling or supervision. Attention mechanisms allow models to focus on the most relevant parts of input text when generating outputs, dramatically improving translation and summarization quality.
How Tokenization, Parsing, and Semantic Analysis Work Together
Moving from core techniques to their integration, understanding how tokenization, parsing, and semantic analysis collaborate reveals the true power of NLP pipelines. Tokenization serves as the essential first step by breaking continuous streams of text into discrete units that algorithms can process individually. Modern tokenizers use subword approaches like Byte Pair Encoding and WordPiece that handle rare words by splitting them into meaningful subunits. These methods prevent the out-of-vocabulary problem that plagued earlier word-level tokenizers when encountering unfamiliar terms or misspellings. Subword tokenization strikes the right balance between vocabulary size and semantic preservation across diverse text inputs. Understanding tokenization in NLP is critical for anyone building or evaluating language processing systems. The choice of tokenizer directly affects model performance, memory requirements, and the range of languages a system can handle.
Parsing takes tokenized text and builds structural representations that capture grammatical relationships and hierarchical organization within sentences. Dependency parsers create directed graphs where arrows connect words to the words they grammatically depend upon in the sentence. These graphs reveal subject-verb-object relationships, modifier attachments, and clause boundaries that determine meaning at the sentence level. Modern neural parsers achieve accuracy rates above ninety-five percent on standard benchmarks for well-structured English text. Parsing accuracy drops significantly for informal text, social media posts, and code-mixed language where grammar rules are frequently violated. Robust parsing requires training on diverse datasets that include both formal and informal language samples from multiple domains.
Semantic analysis builds upon parsed structures to extract meaning, resolve ambiguity, and connect language to real-world knowledge and concepts. Word sense disambiguation determines which meaning of a polysemous word applies in a given context, such as distinguishing “bank” as a financial institution from “bank” as a riverbank. Semantic role labeling identifies who did what to whom in a sentence, assigning functional roles like agent, patient, and instrument to sentence constituents. Knowledge graph integration connects extracted information to structured databases of facts, enriching understanding with external world knowledge. Frame semantics captures the situation or scenario that a sentence describes, going beyond individual word meanings to understand the broader event. These layers of semantic processing work together to move NLP systems from surface-level pattern matching toward genuine language understanding.
How Does Natural Language Processing (NLP) Work?
The journey of unraveling human language through NLP commences with raw text that is meticulously processed through a series of steps. These include tokenization, part-of-speech tagging, dependency parsing, constituency parsing, lemmatization and stemming, stopword removal, word sense disambiguation, named entity recognition (NER), and text classification. Each stage is instrumental in facilitating a machine’s understanding of human language, progressively transforming incomprehensible text into meaningful information. As we delve deeper into the world of NLP, we’ll dissect each of these stages, providing you with a comprehensive understanding of this fascinating process.
Tokenization
Tokenization is a crucial step in the NLP pipeline that involves breaking down a piece of text into individual units or ‘tokens’, which are usually words or phrases. Consider the sentence, “NLP is fascinating.” Tokenization would dissect this into separate units: “NLP”, “is”, and “fascinating.” This step can be likened to a surgeon’s precise incision, where a text body is meticulously segmented into tokens.
Here’s a simple Python snippet for tokenization using the Natural Language Toolkit (NLTK):
import nltk
nltk.download('punkt')
sentence = "NLP is fascinating"
tokens = nltk.word_tokenize(sentence)
print(tokens)
# Output: ['NLP', 'is', 'fascinating']Part-of-Speech Tagging
Once we have the tokens, the next stage involves categorizing them based on their grammatical role in a sentence, a process known as part-of-speech (POS) tagging. In the sentence “NLP is fascinating”, “NLP” is identified as a noun, “is” as a verb, and “fascinating” as an adjective. This is akin to assigning a unique identity badge to each token, which helps in understanding the context of the sentence.
Let’s see how we can do POS tagging using NLTK:
nltk.download('averaged_perceptron_tagger')
pos_tags = nltk.pos_tag(tokens)
print(pos_tags)
# Output: [('NLP', 'NNP'), ('is', 'VBZ'), ('fascinating', 'VBG')]Dependency Parsing
Moving forward, dependency parsing enters the scene. This phase examines the grammatical structure of a sentence, determining how each word interrelates with others. Think of it as solving a puzzle where each piece (word) is interconnected.
Dependency parsing is all about discovering the intricate web of connections that exist among words within a sentence and then visualizing these ties in the form of a tree-like diagram. Every word gets its own distinct label, playing a crucial role in discerning the sentence’s overall meaning.
Here’s an example of dependency parsing using the spaCy library:
nlp = spacy.load('en_core_web_sm')
doc = nlp(sentence)
for token in doc:
print(f'{token.text} <--{token.dep_}-- {token.head.text}')
# Output:
# NLP <--nsubj-- is
# is <--ROOT-- is
# fascinating <--acomp-- isfrom spacy import displacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("NLP is fascinating.")
displacy.render(doc, style="dep", jupyter=True)Constituency Parsing
Constituency parsing is a technique used in natural language processing to analyze the syntactic structure of sentences. It is similar to dependency parsing, which also analyzes the structure of sentences, but instead of breaking down sentences into individual words and their relationships, constituency parsing dissects sentences into sub-phrases or constituents based on their syntactic structure.
In simpler terms, constituency parsing breaks down a sentence into smaller parts based on the way the words in the sentence are grouped together.
Our example sentence, “NLP is fascinating”, can be divided into the noun phrase “NLP” and the verb phrase “is fascinating”. This is somewhat like dividing a cake into different layers, each with its unique flavor contributing to the whole.
Constituency parsing is a bit more complex and needs a dedicated parser. Here’s an example using the NLTK and a pre-trained parser:
from nltk.parse.stanford import StanfordParser
scp = StanfordParser(path_to_jar='path/to/stanford-parser.jar', path_to_models_jar='path/to/stanford-parser-3.9.2-models.jar')
result = list(scp.raw_parse(sentence))
print(result[0])Please replace ‘path/to/stanford-parser.jar’ and ‘path/to/stanford-parser-3.9.2-models.jar’ with the actual paths in your environment. This will give you a constituency parse tree for the sentence.
Lemmatization & Stemming
Lemmatization and stemming are techniques used in text preprocessing and natural language processing algorithms to reduce words to their root or base form. While they may appear similar, they have practical applications depending on the context and the specific requirements of the task at hand.
Stemming is a more rudimentary process, applying a set of rules to strip suffixes from words, and often, the stemmed word may not be a real word. On the other hand, lemmatization takes into account the morphological analysis of words – aiming to remove inflectional endings to return the base or dictionary form of a word, known as the lemma.
Let’s consider the word “better” and “good”. The Porter stemmer will not recognize these as the same root, but lemmatization will because it has more comprehensive linguistic knowledge.
from nltk.stem import PorterStemmer, WordNetLemmatizer
words = ["good", "better"]
stemmer = PorterStemmer()
lemmatizer = WordNetLemmatizer()
print("Stemming results:")
for word in words:
stemmed_word = stemmer.stem(word)
print(stemmed_word)
# Output:
# good
# better
print("\nLemmatization results:")
for word in words:
lemmatized_word = lemmatizer.lemmatize(word, pos='a') # 'a' denotes adjective in this context
print(lemmatized_word)
# Output:
# good
# goodWhile stemming can be faster, lemmatization provides more accurate results, taking into consideration the context of the word in the text.
When dealing with tasks that require high precision and understanding the meaning of words in the text, such as in automatic summarization, lemmatization would be the more suitable approach due to its attention to the grammatical correctness of the resultant word. On the other hand, if the task at hand is more generalized stemming could be a more efficient approach.
NER & Text Classification
Named Entity Recognition is an information extraction method that identifies and classifies named entities in a text into predefined categories such as persons, organizations, locations, and so on. It’s like labeling a proper noun with its appropriate category, enabling machines to understand the significance of the entity in the context.
text = "Did you know that the concept of Natural Language Processing dates back to the 1950s,
with the creation of the world's first chatbot, ELIZA, in the mid-1960s?"
nlp = spacy.load("en_core_web_sm")
doc = nlp(text)
doc.user_data["title"] = "Entity Recognizer"
displacy.render(doc, style="ent", jupyter=True, )Text Classification, on the other hand, involves classifying text into predefined groups.
By analyzing the text data, the algorithm can understand the theme or sentiment of the text and classify it accordingly. For example, a text classification model could categorize movie reviews as positive, negative, or neutral based on the words and phrases used in the review.
Just as lemmatization aids in reducing words to their base form for a more precise understanding, NER and Text Classification help in deciphering the context and sentiment of the text, thereby enriching the overall text analysis and interpretation in natural language processing.
How AI Understands Language
Type a sentence to explore how NLP breaks language into meaning.
How NLP Differs from Traditional Programming
Building on the pipeline concepts above, NLP diverges fundamentally from conventional software development in ways that surprise many engineers entering the field. Traditional programming uses explicit rules written by developers to handle every anticipated input case through conditional logic and deterministic processes. NLP systems learn patterns from data rather than following predefined instructions, making their behavior probabilistic rather than deterministic by nature. This means NLP applications may produce different outputs for similar inputs depending on context, training data, and model architecture choices. The shift from rule-based logic to learned representations represents a paradigm change that transforms how developers approach language-related software problems. Traditional software testing methods struggle with NLP because there is no single correct answer for many language tasks. Evaluating NLP systems requires statistical metrics like precision, recall, F1 scores, and human judgment rather than simple pass-fail test cases.
Another critical difference lies in how NLP handles ambiguity, a challenge that barely exists in traditional programming environments. Programming languages are designed to eliminate ambiguity through strict syntax rules, type systems, and deterministic execution that produces identical outputs every time. Human language thrives on ambiguity, using context, tone, cultural knowledge, and shared understanding to communicate ideas that literal interpretation would miss entirely. NLP systems must navigate sarcasm, metaphor, idiom, ellipsis, and implied meaning that no finite set of rules could fully capture. Understanding the distinction between automation and AI clarifies why NLP requires fundamentally different engineering approaches. Error handling in NLP focuses on graceful degradation and confidence scoring rather than exception catching and error codes. This probabilistic nature makes NLP both more powerful and more unpredictable than traditional software engineering practices.
Real Applications You Already Use Every Day
Transitioning from theory to practice, NLP already powers dozens of tools and services that billions of people interact with daily without realizing the technology behind them. Voice assistants like Alexa, Siri, and Google Assistant rely on NLP to convert spoken commands into structured queries that trigger appropriate actions. Search engines use NLP to understand the intent behind your queries, returning relevant results even when your wording differs from the actual content of web pages. Email spam filters analyze incoming messages using NLP techniques to distinguish legitimate correspondence from unwanted solicitations with remarkable accuracy. Autocomplete and predictive text features on smartphones use language models to suggest the next word you are likely to type. Grammar checking tools like Grammarly employ NLP to detect errors, suggest improvements, and adapt their feedback to your writing style. Recommendation engines on platforms like Netflix and Spotify use NLP to analyze descriptions, reviews, and metadata for better content matching through AI recommendation systems.
Social media platforms deploy NLP extensively for content moderation, trend detection, and personalized feed algorithms that keep users engaged. Automated translation services like Google Translate and DeepL process billions of words daily, making cross-language communication accessible to anyone with an internet connection. Customer service chatbots handle routine inquiries across banking, retail, telecommunications, and travel industries without human intervention at any point. Learning to build an AI chatbot demonstrates how accessible NLP application development has become for non-technical creators. Sentiment analysis tools scan product reviews, social media posts, and survey responses to gauge public opinion about brands, products, and political candidates. These applications process text at speeds and scales that would be physically impossible for human analysts working manually.
News aggregation services use NLP to cluster related articles, detect breaking stories, and generate automated summaries for busy readers across every topic. Legal technology platforms analyze contracts, court filings, and regulatory documents using NLP to identify risks, extract key clauses, and accelerate due diligence. Healthcare documentation systems transcribe physician notes, code medical procedures, and flag potential errors using specialized NLP models trained on clinical language. Financial trading firms use NLP to scan earnings reports, news feeds, and social media in real time, generating trading signals before human analysts finish reading headlines. Educational technology platforms personalize learning experiences by analyzing student responses and adapting content difficulty based on comprehension indicators. The breadth of NLP applications continues expanding as model capabilities improve and deployment costs decline across every major industry.
NLP in Healthcare and Medical Research
As NLP applications expand across industries, healthcare represents one of the most impactful domains where language processing saves lives and reduces costs. Clinical NLP systems extract structured data from physician notes, discharge summaries, and pathology reports that exist almost entirely as free-form text in electronic health records. These systems identify diagnoses, medications, allergies, and procedures mentioned in clinical narratives, converting them into coded data for analysis and billing purposes. Mayo Clinic has implemented NLP systems that analyze unstructured clinical notes to identify patients with particular conditions who might benefit from targeted interventions. Natural language processing in healthcare reduces the administrative burden that consumes up to seventy percent of clinical staff working hours daily. AI-powered documentation tools from major electronic health record vendors like Epic and Cerner now generate structured clinical notes from physician dictation automatically. Research into AI advances in medical NLP continues accelerating the extraction of insights from medical literature at unprecedented speed.
Drug discovery represents another frontier where NLP processes millions of scientific papers, patents, and clinical trial reports to identify promising compounds. Pharmacovigilance systems scan adverse event reports and social media posts to detect early signals of drug side effects before they become widespread health crises. Mental health applications analyze patient language patterns to detect signs of depression, anxiety, and suicidal ideation through subtle linguistic markers. Radiology report analysis uses NLP to flag critical findings, ensure completeness, and maintain consistency across imaging interpretations within hospital systems. Clinical trial matching systems compare patient records against eligibility criteria for thousands of active studies, dramatically increasing enrollment rates and research efficiency. The intersection of NLP and healthcare demonstrates how language technology can deliver measurable improvements in patient outcomes and system efficiency.
Financial Services and Fraud Detection Through NLP
Extending the healthcare discussion to another high-stakes domain, financial services firms have become some of the most aggressive adopters of NLP technology worldwide. Banks deploy NLP to analyze customer communications, detect fraudulent transactions, and automate compliance monitoring across millions of daily interactions. Sentiment analysis of earnings calls, analyst reports, and financial news provides institutional investors with real-time market intelligence that informs trading decisions. Regulatory technology platforms use NLP to scan thousands of pages of new regulations, identifying requirements that affect specific business units or product lines automatically. Financial institutions that implement NLP for compliance monitoring report significant reductions in manual review time and regulatory penalties. Anti-money laundering systems analyze transaction descriptions, customer communications, and account narratives to flag suspicious patterns that rule-based systems miss entirely. Credit risk assessment models incorporate NLP analysis of loan applications, financial statements, and news articles to build more comprehensive borrower profiles.
Insurance companies use NLP to process claims documents, assess damage descriptions, and detect inconsistencies that may indicate fraudulent filings across their portfolios. Wealth management platforms analyze client communications to ensure advisors meet suitability requirements and document investment rationale for regulatory compliance. Automated report generation systems produce personalized financial summaries, market commentaries, and portfolio reviews using NLP-powered content creation tools. Customer onboarding processes use NLP to extract information from identification documents, verify data consistency, and reduce manual data entry errors. These applications demonstrate that NLP delivers measurable return on investment in financial services through reduced operational costs and improved risk management. The financial sector’s investment in NLP technology continues growing as regulatory complexity increases and competitive pressure demands faster information processing.
Robo-advisory platforms combine NLP with financial modeling to interpret client goals expressed in natural language and translate them into investment strategies. Chatbots in banking handle account inquiries, transaction disputes, and product recommendations while maintaining security protocols and compliance requirements simultaneously. Market surveillance systems analyze trading communications to detect potential insider trading, market manipulation, and other regulatory violations in real time. The scale of financial data processing makes NLP essential because no human team could monitor the volume of text generated across global financial markets daily. Voice analytics in call centers identify customer frustration, compliance risks, and upselling opportunities through real-time analysis of voice AI in contact centers. These financial NLP applications continue evolving as models become more capable of understanding domain-specific terminology and regulatory nuance.
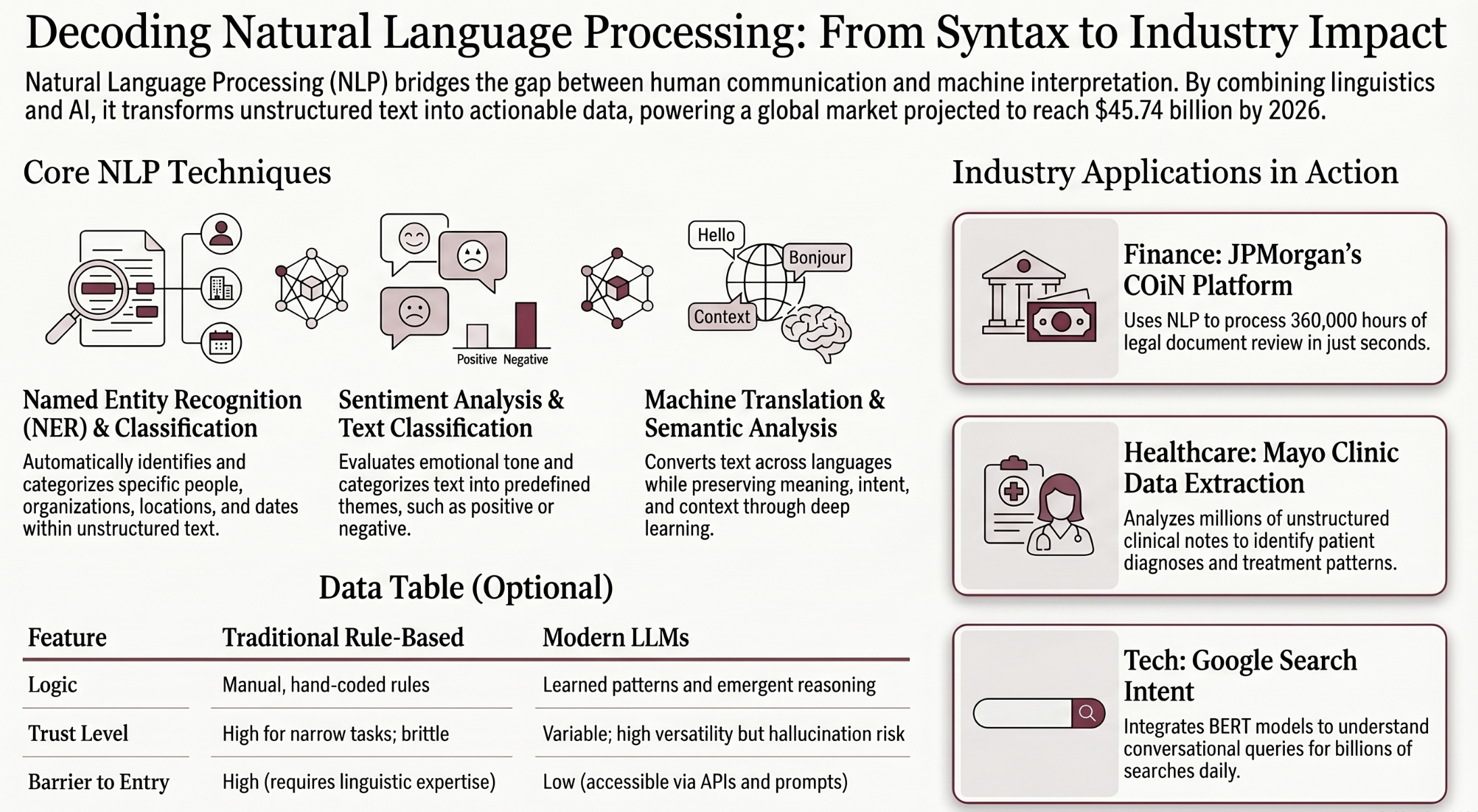
Building Your First NLP Pipeline
Moving from industry applications to hands-on implementation, building an NLP pipeline requires understanding the sequential stages that transform raw text into actionable outputs. The first step involves data collection, where you gather text data relevant to your specific task from sources like databases, APIs, web scraping, or manual annotation. Data quality matters more than quantity because noisy, inconsistent, or biased training data produces models that fail in production regardless of their architectural sophistication. Preprocessing follows collection, applying tokenization, lowercasing, punctuation removal, and encoding normalization to create clean consistent inputs for downstream processing. A well-designed preprocessing pipeline can improve model accuracy by ten to twenty percent compared to feeding raw unprocessed text directly into algorithms. Feature extraction converts preprocessed text into numerical representations using techniques like TF-IDF, word embeddings, or contextual encoders depending on your task requirements. The choice between these representation methods depends on available computational resources, dataset size, and the complexity of your target task.
Model selection depends on the specific NLP task you need to accomplish, ranging from simple classification to complex generation and reasoning problems. Traditional machine learning models like logistic regression, random forests, and support vector machines work well for straightforward classification tasks with limited training data. Deep learning models including recurrent neural networks, convolutional neural networks, and transformers handle complex sequential patterns and long-range dependencies in text. Transfer learning allows you to fine-tune pretrained models like BERT or RoBERTa on your specific dataset, dramatically reducing training time and data requirements. Exploring resources for deep learning and AI helps clarify which neural architectures suit different NLP applications best. Model training involves setting hyperparameters, selecting loss functions, and running optimization algorithms across your prepared training dataset iteratively. Validation on held-out data prevents overfitting and ensures your model generalizes to unseen examples rather than memorizing training examples.
Evaluation and deployment close the pipeline loop, transforming a trained model into a production system that handles real-world input reliably. Standard evaluation metrics include accuracy, precision, recall, F1 score, and area under the ROC curve depending on whether your task involves classification, extraction, or generation. Human evaluation remains essential for generation tasks where automated metrics fail to capture fluency, coherence, and factual accuracy of model outputs. Deployment options range from REST APIs and microservices to edge devices and browser-based inference depending on latency and privacy requirements. Monitoring production models for data drift, performance degradation, and emerging failure modes requires continuous automated testing and alerting infrastructure. Model retraining schedules must account for language evolution, domain changes, and newly available data that could improve system performance over time. A complete NLP pipeline is never truly finished because language and user expectations change continuously, requiring ongoing maintenance and adaptation.
Choosing the Right NLP Framework and Tools
Once you understand pipeline architecture, selecting the right framework determines how quickly you can build, test, and deploy NLP solutions in practice. Python dominates the NLP landscape with mature libraries including NLTK for educational purposes, spaCy for production-grade processing, and Hugging Face Transformers for state-of-the-art model access. NLTK provides comprehensive tools for linguistic analysis, educational resources, and access to over fifty corpora and lexical resources for researchers. SpaCy focuses on industrial-strength natural language processing with optimized pipelines for tokenization, named entity recognition, dependency parsing, and text classification. Hugging Face has become the central hub for pretrained NLP models, hosting over four hundred thousand models covering dozens of languages and tasks. Cloud-based NLP services from Google, Amazon, and Microsoft offer pre-built APIs for common tasks, reducing development time but increasing ongoing operational costs. The best framework choice depends on your team’s expertise, your deployment constraints, and whether you need maximum customization or fastest time to market.
Open-source tools provide flexibility and transparency that proprietary platforms cannot match, especially for organizations concerned about data privacy and vendor dependency. TensorFlow and PyTorch serve as the foundational deep learning frameworks that power most custom NLP model development and research experimentation. Gensim specializes in topic modeling and document similarity calculations, offering efficient implementations of algorithms like LDA and Doc2Vec for large corpora. Stanford CoreNLP provides a comprehensive suite of linguistic analysis tools with strong support for multiple languages and well-documented academic research foundations. For professionals looking to deepen their expertise, resources on mastering large language models provide structured learning paths from fundamentals to advanced techniques. Commercial platforms like AWS Comprehend, Google Cloud NLP, and Azure Cognitive Services offer managed solutions that scale automatically without infrastructure management overhead. Evaluating frameworks requires testing them against your specific data, measuring performance on your metrics, and considering long-term maintenance requirements and community support.
Enterprise deployment requires additional considerations around model versioning, A/B testing infrastructure, security compliance, and integration with existing data pipelines. Containerization using Docker and orchestration through Kubernetes has become the standard approach for deploying NLP models in production environments at scale. Model serving frameworks like TensorFlow Serving, TorchServe, and Triton Inference Server optimize inference performance and manage concurrent request processing efficiently. MLOps platforms like MLflow, Weights and Biases, and Kubeflow provide experiment tracking, model registry, and deployment automation capabilities essential for mature teams. API gateway integration ensures NLP services handle authentication, rate limiting, logging, and error handling consistently across all consumer applications. The tooling ecosystem around NLP deployment has matured significantly, making production-grade language processing accessible to teams of all sizes and experience levels.
Transformer Models and the Rise of Large Language Models
The evolution from traditional frameworks to transformer-based architectures represents the most significant paradigm shift in NLP since the field’s inception decades ago. Transformers replaced recurrent neural networks by introducing self-attention mechanisms that process all words in a sentence simultaneously rather than sequentially. This parallel processing capability allowed transformers to train on vastly larger datasets and capture long-range dependencies that recurrent architectures struggled with fundamentally. The original 2017 transformer paper proposed an encoder-decoder architecture for machine translation that outperformed every previous approach on standard benchmarks immediately. Self-attention allows each word in a sentence to directly attend to every other word, creating rich contextual representations that capture nuanced meaning. BERT introduced bidirectional pretraining that reads text in both directions simultaneously, producing contextualized word representations that revolutionized dozens of downstream tasks. GPT took the decoder-only approach, training autoregressive models that predict the next word in a sequence and unlocked powerful text generation capabilities.
Large language models scaled transformer architectures to hundreds of billions of parameters, trained on trillions of tokens from diverse internet text sources. GPT-3 demonstrated that scale alone could produce emergent capabilities like few-shot learning, code generation, and mathematical reasoning that smaller models lacked entirely. Instruction-tuned models like InstructGPT and ChatGPT added reinforcement learning from human feedback to align model outputs with human preferences and safety requirements. Constitutional AI approaches developed by companies like Anthropic train models to follow principles rather than specific rules, improving generalization across diverse use cases. The competitive landscape now includes dozens of large language models from Google, Meta, Mistral, and open-source communities with varying strengths across different tasks. Each generation of models has demonstrated capabilities that the previous generation suggested were years away, accelerating the pace of NLP advancement dramatically.
Fine-tuning large language models for specific domains and tasks has become a critical skill for organizations deploying NLP in production environments. Parameter-efficient fine-tuning methods like LoRA and QLoRA allow teams to adapt billion-parameter models using modest computational resources and limited domain-specific data. Retrieval-augmented generation combines large language models with external knowledge bases, reducing hallucination and keeping responses grounded in verified factual information. Prompt engineering has emerged as a distinct discipline focused on crafting inputs that reliably produce desired outputs from large language models without modifying weights. The role of AI prompt engineering has become one of the most sought-after skills in the technology industry today. Chain-of-thought prompting enables models to break complex problems into sequential reasoning steps, dramatically improving accuracy on mathematical and logical tasks. These techniques democratize access to powerful NLP capabilities, allowing smaller organizations to leverage state-of-the-art models without massive infrastructure investments.
Multimodal large language models extend text processing to handle images, audio, video, and structured data within unified architectures simultaneously. Vision-language models like GPT-4 can analyze photographs, charts, and documents alongside text inputs, enabling applications that previously required separate specialized systems. Audio-language models transcribe speech, analyze tone, and generate spoken responses using the same underlying transformer architecture adapted for acoustic signals. The convergence of modalities within single models reflects the direction NLP is heading, toward systems that understand communication in all its forms. These multimodal capabilities open applications in accessibility, education, creative industries, and scientific research that text-only models could never address. The architectural innovations driving multimodal NLP continue accelerating as researchers find more efficient ways to represent and process diverse information types.
Bias, Fairness, and Ethical Concerns in Language AI
As NLP systems grow more powerful and pervasive, the ethical implications of deploying language technology at scale demand serious attention and thoughtful governance. Training data reflects the biases present in human language and historical text, meaning NLP models inevitably absorb and amplify stereotypes related to gender, race, and culture. Word embeddings trained on news articles and internet text demonstrate measurable gender bias, associating certain professions and traits with specific demographic groups consistently. Machine translation systems have historically defaulted to male pronouns when translating from gender-neutral languages, reinforcing assumptions about professional roles and social status. Bias in NLP systems is not merely a technical bug but a reflection of systemic inequalities embedded in the language data these models learn from. Addressing bias requires diverse training data, careful evaluation across demographic groups, and ongoing monitoring of model outputs in production environments. Frameworks for responsible AI governance provide structured approaches to identifying and mitigating these risks systematically.
Fairness in NLP extends beyond bias in word representations to encompass how language technology affects different communities unequally in practice. Speech recognition systems perform significantly worse for speakers with non-standard accents, dialects, and speech patterns, effectively excluding millions from voice-controlled services. Sentiment analysis models trained primarily on English text from Western sources struggle to accurately interpret emotional expression in other cultural contexts. Content moderation algorithms disproportionately flag posts in African American Vernacular English and other minority dialects as toxic or inappropriate at higher rates. Automated hiring tools that screen resumes using NLP have been shown to penalize candidates who describe experiences using non-standard language or cultural references. These disparities mean that NLP systems can systematically disadvantage the communities that are already marginalized, compounding existing inequalities through technological amplification.
Transparency and explainability present additional ethical challenges because modern NLP models operate as complex neural networks whose decision-making processes resist simple explanation. Users interacting with NLP-powered systems often cannot determine whether they are communicating with a human or a machine, raising consent and disclosure concerns. Deepfake text generation capabilities create risks for misinformation campaigns, academic fraud, and impersonation that society is only beginning to address through regulation. Tools designed for artificial intelligence detection attempt to identify machine-generated text, but their reliability varies significantly across writing styles. The environmental cost of training large language models also raises ethical questions about resource allocation, with single training runs consuming energy equivalent to multiple households’ annual consumption. Responsible deployment of NLP requires ongoing dialogue between technologists, ethicists, policymakers, and affected communities to balance innovation with accountability.
Data Privacy and Security Challenges
Ethical concerns naturally extend into the domain of data privacy and security, where NLP systems face unique vulnerabilities tied to the sensitive nature of language data. NLP models trained on personal communications, medical records, or financial documents may inadvertently memorize and reproduce private information during inference. Membership inference attacks can determine whether specific text was included in a model’s training data, potentially exposing confidential information to adversaries. Prompt injection attacks exploit NLP systems by embedding malicious instructions within seemingly innocent text inputs, hijacking model behavior for unauthorized purposes. Data privacy in NLP requires a multi-layered defense strategy combining technical safeguards, organizational policies, and regulatory compliance frameworks simultaneously. Differential privacy techniques add calibrated noise during training to prevent models from memorizing individual data points while preserving overall statistical patterns. Federated learning allows NLP models to train across distributed datasets without centralizing sensitive text data in a single location, reducing breach exposure.
Regulatory frameworks like GDPR, CCPA, and emerging AI-specific legislation impose strict requirements on how organizations collect, process, and store language data for NLP applications. The right to erasure creates technical challenges because removing specific training examples from deployed NLP models requires retraining or sophisticated machine unlearning techniques. Cross-border data transfer restrictions complicate NLP development for multinational organizations that need consistent language processing across geographic regions with different privacy standards. Industry-specific regulations in healthcare, finance, and legal services add additional compliance layers that NLP system designers must address during architecture planning. Organizations deploying NLP must conduct data protection impact assessments that evaluate the privacy risks of processing personal language data at scale. Security auditing of NLP systems should include adversarial testing, model extraction resistance, and output monitoring to detect and prevent information leakage systematically.
Why Businesses Are Investing Billions in NLP
Beyond technical and ethical considerations, the business case for NLP investment has become overwhelming, driving record capital allocation across every major industry sector. The global NLP market is growing at a compound annual growth rate exceeding nineteen percent, reaching an estimated forty-five billion dollars in 2026 with projections toward two hundred billion by 2034. Customer service automation through NLP-powered chatbots reduces support costs by thirty to fifty percent while simultaneously improving response times and customer satisfaction scores. Document processing automation eliminates manual data entry, reduces error rates, and accelerates workflows in legal, financial, and healthcare organizations significantly. Enterprises deploying NLP at scale report measurable improvements in operational efficiency, customer retention, and competitive intelligence gathering within the first year of implementation. Content generation tools powered by NLP enable marketing teams to produce personalized communications at scales impossible with human writers alone across multiple channels. The return on investment for NLP deployment typically manifests through reduced labor costs, faster processing times, and improved decision quality across business functions.
Healthcare organizations invest in NLP to address documentation burdens, improve clinical coding accuracy, and accelerate research through automated literature analysis. Financial services firms deploy NLP for regulatory compliance, fraud detection, market intelligence, and automated reporting that would otherwise require large analyst teams. Retail and e-commerce companies use NLP for product search optimization, review analysis, personalized recommendations, and automated customer support across digital channels. Telecommunications providers implement NLP to analyze customer feedback, predict churn, optimize network operations, and automate billing dispute resolution processes. Government agencies invest in NLP for public records analysis, policy research, constituent communications, and national security intelligence processing at scale. The diversity of investment across sectors demonstrates that NLP has moved beyond experimental technology into essential business infrastructure for competitive organizations.
Small and medium enterprises are increasingly accessing NLP capabilities through cloud-based APIs and pre-built solutions that eliminate the need for specialized technical teams. Pay-per-use pricing models from cloud providers like AWS, Google Cloud, and Microsoft Azure make sophisticated NLP capabilities available without significant upfront capital investment. No-code and low-code NLP platforms enable business analysts and domain experts to build custom language processing solutions without programming knowledge. The democratization of NLP through accessible tools and services is expanding the market beyond large enterprises to organizations of every size and technical maturity. Industry analysts predict that small and medium enterprise adoption of NLP will grow at over twenty-five percent annually through 2030 as barriers to entry continue falling. This broad-based adoption creates a virtuous cycle where more data and more users improve model quality, which attracts more adoption and further investment.
Measuring NLP Performance and Accuracy
As investments grow, executives and engineers need reliable methods to evaluate whether NLP systems deliver the accuracy and performance their applications demand. Classification tasks use precision, recall, and F1 score metrics that balance the tradeoffs between false positives and false negatives across different error types. Machine translation quality is measured through BLEU scores that compare machine outputs against human reference translations using n-gram overlap calculations. Summarization and generation tasks employ ROUGE metrics that measure the overlap between machine-generated summaries and human-written reference summaries at various n-gram levels. No single metric captures the full quality of an NLP system because language tasks involve multiple dimensions including accuracy, fluency, coherence, and factual correctness. Human evaluation remains the gold standard for generation tasks where automated metrics poorly correlate with actual quality perceived by end users. Benchmark datasets like GLUE, SuperGLUE, and SQuAD provide standardized evaluation frameworks that allow researchers to compare model performance across comparable conditions.
Production monitoring extends beyond benchmark performance to track real-world metrics including latency, throughput, error rates, and user satisfaction across live deployments. A/B testing frameworks allow teams to compare different NLP models, prompts, and configurations against each other using actual user interactions and outcomes. Drift detection systems monitor changes in input distribution over time, alerting teams when production data diverges significantly from training data characteristics. Understanding the common natural language processing challenges helps teams anticipate failure modes and design more robust evaluation frameworks. Cost-per-inference tracking ensures that NLP improvements deliver value relative to the computational resources consumed during production operation. Comprehensive evaluation strategies combine automated metrics, human judgment, business outcome tracking, and operational monitoring into unified dashboards that inform continuous improvement.
When NLP Fails and What It Means
Evaluation metrics inevitably reveal failure cases, and understanding where NLP breaks down is as important as celebrating where it succeeds for responsible deployment. Ambiguity remains the most persistent challenge because human language regularly contains sentences with multiple valid interpretations that context alone cannot resolve. Sarcasm, irony, and humor exploit the gap between literal meaning and intended meaning in ways that current NLP models detect unreliably across diverse contexts. Domain transfer failures occur when models trained on general text encounter specialized vocabulary, jargon, or communication patterns specific to particular industries or communities. NLP systems fail most dangerously when they produce confident-sounding but factually incorrect outputs that users trust without independent verification. Low-resource languages with limited digital text data receive dramatically worse NLP performance than well-resourced languages like English, Chinese, and Spanish. Code-switching between multiple languages within single conversations, common in multilingual communities, degrades NLP performance because models are typically trained on monolingual data.
Adversarial attacks deliberately craft inputs designed to fool NLP systems, exposing vulnerabilities that could be exploited in security-critical applications including identity verification. Hallucination in language generation models produces plausible-sounding but entirely fabricated facts, citations, and claims that undermine trust in AI-generated content. Long-document understanding remains challenging because attention mechanisms in transformer models face quadratic computational costs as input length increases beyond context windows. Temporal reasoning fails when models cannot distinguish between past, present, and future events described in text, producing anachronistic or contradictory outputs. Cultural context presents ongoing challenges because language carries cultural assumptions, idioms, and references that differ dramatically across regions, communities, and generations. These failure modes are not just technical limitations but active areas of research where progress could unlock entirely new categories of NLP applications.
Responsible deployment requires organizations to design NLP systems with failure awareness, implementing confidence thresholds, human escalation paths, and clear user expectations about system capabilities. Graceful degradation strategies ensure that when NLP components fail, overall system functionality continues rather than producing catastrophic or misleading results silently. Error analysis practices systematically categorize failure cases to guide targeted improvements rather than randomly adjusting model parameters without understanding root causes. User feedback loops capture instances where NLP outputs fail to meet expectations, creating labeled datasets that drive continuous model improvement over time. The willingness to acknowledge limitations publicly and transparently sets responsible NLP practitioners apart from those who overpromise capabilities that current technology cannot reliably deliver. Failure is inherent in probabilistic systems, and treating it as expected behavior rather than an anomaly produces more robust and trustworthy NLP applications.
The Future of Language AI Beyond 2026
Looking beyond current limitations, the trajectory of NLP research and development points toward capabilities that will transform industries and human-machine interaction within the next decade. Autonomous language agents represent the next frontier, combining NLP with planning, tool use, and memory to complete multi-step tasks with minimal human supervision. These agents can retrieve information, execute code, manage workflows, and collaborate with other agents to accomplish complex objectives that current chatbots cannot handle alone. Research labs at Google, Meta, Microsoft, and Anthropic are investing heavily in agent architectures that chain language understanding with real-world action capabilities. The transition from passive language models to active language agents represents a fundamental shift in how NLP technology will integrate into professional workflows. Efficient attention mechanisms are reducing the computational cost of processing long documents, making NLP more affordable and sustainable for deployment at scale. Multi-agent systems where specialized NLP components collaborate like human teams show promising results on complex research and analysis tasks.
Multimodal understanding will become standard as NLP systems process text, images, audio, video, and structured data within unified frameworks simultaneously. These models will understand a photograph’s content, read its embedded text, analyze its emotional tone, and generate descriptive narratives about it in a single forward pass. Cross-modal reasoning will enable systems to answer questions that require integrating information from multiple sensory channels and knowledge sources simultaneously. Educational applications will benefit enormously as NLP tutors adapt to individual learning styles, assess understanding through conversation, and provide personalized feedback. Healthcare diagnostics will combine NLP analysis of patient narratives with medical imaging interpretation to produce more comprehensive clinical assessments automatically. Creative industries will use NLP for collaborative storytelling, interactive entertainment, and adaptive content that responds to audience engagement in real time.
Efficient and specialized language models will proliferate as organizations discover that smaller, domain-specific models often outperform general-purpose giants on targeted tasks. Knowledge distillation techniques compress large model capabilities into smaller models that run on edge devices, smartphones, and embedded systems with limited resources. On-device NLP processing will expand privacy-preserving language capabilities to applications where cloud connectivity is unavailable, unreliable, or undesirable. The democratization of model training through parameter-efficient techniques allows smaller organizations to build competitive NLP solutions without massive computational budgets. Open-source model development through communities like Hugging Face, EleutherAI, and BigScience continues accelerating access to state-of-the-art NLP capabilities globally. The future belongs to specialized, efficient models that deliver excellent performance on specific tasks rather than monolithic systems attempting to do everything.
Regulatory and governance frameworks will mature alongside technology, establishing clear standards for NLP system transparency, accountability, and performance certification. International standards bodies are developing evaluation protocols for NLP systems used in high-stakes domains like healthcare, criminal justice, and financial services. The European Union’s AI Act establishes risk-based categories for NLP applications, requiring different levels of documentation, testing, and oversight based on potential harm. Industry self-regulation through responsible AI principles and third-party auditing will complement government oversight as the NLP ecosystem grows more complex. Research into interpretable NLP aims to make model decision-making transparent enough for meaningful human oversight without sacrificing the performance that opacity currently enables. The relationship between NLP innovation and regulatory development will shape which applications reach market, which organizations lead, and which societies benefit most from language technology.
How NLP Powers Generative AI and Chatbots
The future landscape of NLP is inseparable from generative AI, where language models create original text, code, and creative content based on learned patterns. Generative AI relies entirely on NLP foundations including tokenization, attention mechanisms, and language modeling to produce outputs that are coherent, relevant, and contextually appropriate. Chatbots have evolved from simple pattern-matching systems into sophisticated conversational agents that maintain context across extended multi-turn dialogues seamlessly. Modern chatbots use retrieval-augmented generation to ground their responses in factual data sources, reducing the hallucination problem that plagued earlier generative models. Generative AI represents the most visible application of NLP technology, introducing millions of non-technical users to the capabilities and limitations of language processing systems. Content generation tools assist marketers, journalists, researchers, and students with drafting, editing, summarization, and translation tasks that previously consumed significant manual effort. Exploring the role of generative AI in creative fields reveals how NLP is reshaping artistic expression and content creation fundamentally.
Code generation represents a specialized NLP application where language models trained on programming text produce functional software from natural language descriptions. GitHub Copilot, Amazon CodeWhisperer, and similar tools use NLP to translate programmer intent into executable code across dozens of programming languages simultaneously. Automated documentation generation scans codebases and produces human-readable explanations, API references, and usage examples without manual technical writing effort. Creative writing assistance tools help authors overcome writer’s block, explore narrative alternatives, and maintain consistency across long-form fiction projects. Summarization models condense lengthy documents, research papers, and meeting transcripts into concise summaries that preserve essential information and key decisions. These generative applications demonstrate that NLP has moved beyond analysis and understanding into the domain of creation and synthesis.
Enterprise adoption of generative NLP requires careful governance around factual accuracy, brand voice consistency, intellectual property protection, and regulatory compliance. Organizations deploy generative NLP through controlled environments that limit outputs to approved topics, enforce fact-checking against internal knowledge bases, and maintain human oversight loops. Fine-tuning on proprietary data allows companies to create generative models that understand their specific terminology, processes, and communication standards intimately. Evaluation of generative NLP outputs requires multidimensional assessment covering factual accuracy, relevance, coherence, safety, and alignment with organizational values simultaneously. The rapid adoption of generative NLP across enterprises has created new roles including prompt engineers, AI content strategists, and language model evaluation specialists within organizations. These governance and operational considerations determine whether generative NLP delivers lasting business value or creates liability through unchecked, inaccurate, or harmful outputs.
Cross-Language Understanding and Multilingual NLP
Generative capabilities become even more transformative when NLP systems operate across linguistic boundaries, enabling true multilingual communication at global scale. Multilingual NLP models like mBERT, XLM-RoBERTa, and NLLB process text in over a hundred languages using shared representations that transfer knowledge between languages automatically. Cross-lingual transfer learning allows models trained primarily on English data to perform reasonably well on tasks in languages with limited training resources available. Zero-shot cross-lingual capabilities enable NLP systems to process languages they were never explicitly trained on by leveraging structural similarities between language families. Multilingual NLP breaks down language barriers that have historically limited global communication, commerce, and knowledge sharing across linguistic communities. Machine translation quality has improved dramatically, with neural approaches producing translations that approach human quality for common language pairs in specific domains. Real-time translation services powered by NLP enable international business meetings, medical consultations, and diplomatic negotiations to occur across language boundaries seamlessly.
Low-resource languages present the greatest challenge and opportunity for multilingual NLP because the vast majority of the world’s seven thousand languages lack sufficient digital text for model training. Active learning and human-in-the-loop approaches help extend NLP capabilities to underserved languages by efficiently using limited annotated data from native speakers. Community-driven data collection initiatives create linguistic resources for endangered and minority languages, preserving cultural heritage while enabling technological access. Transfer learning from related high-resource languages provides bootstrapping capabilities that significantly reduce the data requirements for achieving useful NLP performance. Universal language models that learn language-agnostic representations offer hope for extending NLP benefits to every human language rather than just the most widely spoken ones. These efforts ensure that NLP technology does not exacerbate existing global inequalities by serving only dominant languages while ignoring the rest.
Code-switching detection and handling has become increasingly important as NLP systems encounter users who naturally mix languages within single conversations and documents. Dialectal variation within languages creates additional complexity because standard NLP models often fail on text written in regional dialects or informal registers. Cultural adaptation goes beyond translation to ensure NLP systems interpret sentiment, humor, formality, and social context appropriately across different cultural frameworks. Named entity recognition across scripts requires handling different writing systems, character encodings, and naming conventions that vary dramatically across languages and cultures. The path toward truly universal NLP requires sustained investment in linguistic diversity, inclusive dataset creation, and evaluation methodologies that measure performance across all communities. Multilingual NLP represents both a technical challenge and a moral imperative for ensuring language technology serves humanity broadly rather than reinforcing existing power structures.
Emerging standards for multilingual NLP evaluation help researchers and practitioners measure progress toward equitable language technology across diverse linguistic communities fairly. Benchmark datasets covering multiple languages and tasks enable systematic comparison of multilingual models against monolingual baselines to quantify cross-lingual transfer effectiveness. Industry consortiums developing shared multilingual resources reduce duplicated effort and accelerate progress toward comprehensive language coverage across NLP applications worldwide. The economic incentive for multilingual NLP is substantial because serving customers in their native language increases engagement, conversion rates, and brand loyalty measurably. Government initiatives supporting digital language equality in countries like India, Nigeria, and Indonesia drive investment in NLP for local languages that market forces alone would not prioritize. The future of NLP is inherently multilingual because language technology that works for only a fraction of the world’s speakers fails its fundamental promise.
Key Insights
- Autonomous language agents capable of planning, executing, and completing multi-step tasks with minimal supervision represent the leading NLP trend for 2026 and beyond.
- The global NLP market is projected to reach USD 45.74 billion in 2026 and grow to USD 193.4 billion by 2034, reflecting enterprise demand for language processing across every major industry sector.
- Cloud deployment accounts for approximately sixty-three percent of NLP market share, and this segment is growing at a CAGR near twenty-five percent as organizations favor scalable inference infrastructure over on-premises hardware.
- Healthcare workers spend up to seventy percent of their time on administrative tasks, driving rapid adoption of NLP-powered documentation systems from major EHR vendors like Epic and Cerner.
- North America leads the global NLP market with approximately forty-five percent revenue share, followed by Asia Pacific as the fastest-growing region driven by multilingual NLP investment.
- Efficient attention mechanisms are reducing computational costs, with some fine-tuned models achieving comparable accuracy to larger counterparts while using fifty percent less computational power.
- Small and medium enterprise adoption is projected to grow at over twenty-five percent annually through 2030 as cloud APIs and pay-per-use pricing lower barriers to entry.
- Banking, financial services, and insurance held approximately twenty-one percent of NLP market share in 2024, with healthcare projected as the fastest-growing vertical.
| Dimension | Traditional Rule-Based NLP | Statistical NLP | Deep Learning NLP | Large Language Models |
|---|---|---|---|---|
| Transparency | High — rules are explicit and auditable | Moderate — probabilities are interpretable | Low — neural weights resist explanation | Very Low — billions of parameters are opaque |
| Participation Barrier | High — requires linguistic expertise | Moderate — requires ML knowledge | Moderate to High — requires GPU resources | Low — accessible via APIs and prompts |
| Trust Level | High for narrow domains, brittle elsewhere | Moderate — depends on data quality | Growing — requires validation frameworks | Variable — hallucination risk undermines trust |
| Decision Making | Deterministic and predictable | Probabilistic with confidence scores | Probabilistic with learned representations | Probabilistic with emergent reasoning abilities |
| Misinformation Risk | Low — outputs limited to coded rules | Low — constrained by training distribution | Moderate — can amplify training biases | High — can generate plausible false information |
| Service Delivery | Limited to predefined scenarios | Broader but requires feature engineering | Scalable across many tasks | Versatile across languages, tasks, and domains |
| Accountability | Clear — rules trace to specific authors | Partial — model behavior is auditable | Difficult — attribution is complex | Challenging — emergent behaviors resist attribution |
| Bias Handling | Explicit but manual bias detection | Statistical bias measurement possible | Requires systematic debiasing techniques | Active research area with evolving mitigation tools |
Real-World Examples
Google Search and NLP Understanding
Google deployed BERT across its search engine to better understand the intent behind user queries, particularly for longer conversational searches that depend on prepositions and context words. The integration improved search result relevance for approximately ten percent of English-language queries, affecting billions of searches daily worldwide. BERT allowed Google to match queries with relevant pages even when the exact keyword phrasing differed between the query and the target content significantly. This deployment demonstrated that NLP could scale to production systems handling billions of requests while maintaining the low latency users expect from web search. Critics noted that BERT’s improvements benefited well-structured English queries disproportionately, with less measurable impact on queries in lower-resource languages and informal dialects. The full technical details are available through Google’s AI Blog post on BERT for Search.
JPMorgan’s COiN Platform
JPMorgan Chase deployed its Contract Intelligence platform to analyze legal documents using NLP, processing commercial loan agreements that previously required approximately three hundred sixty thousand hours of lawyer review annually. The system extracts key data points, identifies relevant clauses, and flags anomalies across thousands of complex financial contracts with consistent accuracy. COiN reduced document review time from hours to seconds per document, allowing legal teams to focus on complex judgment calls rather than routine extraction work. The measurable impact included significant reductions in loan servicing errors and faster deal processing times across the firm’s commercial lending operations. Limitations include the system’s dependence on structured document formats and its reduced effectiveness on contracts with unusual clause structures or non-standard language patterns. Details on JPMorgan’s AI strategy are documented through their annual technology reports.
Estonia’s Digital Government NLP
Estonia deployed NLP-powered systems across its digital government infrastructure to process citizen requests, automate administrative decisions, and translate official communications across multiple languages. The system handles tax filing queries, business registration questions, and public service requests in Estonian, Russian, and English with automated response generation. Processing times for routine government inquiries dropped from days to minutes, improving citizen satisfaction while reducing the administrative workforce needed for routine tasks. The measurable outcome included higher digital service adoption rates and reduced per-transaction costs for government operations across dozens of service categories. Critics raised concerns about algorithmic decision-making in government contexts where transparency, due process, and appeal mechanisms must be guaranteed for all citizens. Information about Estonia’s digital governance initiatives is available through the e-Estonia portal.
Case Studies
Mayo Clinic’s Clinical NLP Deployment
Mayo Clinic faced the challenge of extracting structured data from millions of unstructured clinical notes, discharge summaries, and pathology reports stored across its electronic health record system. The volume of free-text clinical documentation made manual review impossible, while coded data alone captured only a fraction of the clinically relevant information available. Mayo developed and deployed clinical NLP systems that automatically identify diagnoses, medications, allergies, and procedures mentioned within narrative clinical text. These systems enabled computational phenotyping, allowing researchers to identify patient cohorts for clinical trials and population health studies at unprecedented speed and scale. The measurable impact included improved early detection rates for specific conditions and dramatically increased enrollment in relevant clinical trials through automated patient matching. Limitations included reduced accuracy on notes containing heavy abbreviations, non-standard terminology, and handwritten annotations that still required human interpretation in many cases. Critics noted that clinical NLP accuracy varies significantly across medical specialties, with some areas achieving above ninety percent accuracy while others remained below seventy percent. Details on Mayo’s NLP research are published through their proceedings and research portal.
Bloomberg’s Financial NLP Infrastructure
Bloomberg confronted the challenge of processing millions of financial documents, news articles, and regulatory filings daily to deliver real-time market intelligence to its terminal subscribers worldwide. Traditional keyword-based search and manual analyst review could not keep pace with the exponentially growing volume of financial text requiring analysis across global markets. Bloomberg built proprietary NLP systems that perform sentiment analysis on earnings calls, extract key figures from financial statements, and classify news articles by market relevance automatically. The company also developed BloombergGPT, a large language model specifically trained on financial text to handle domain-specific language that general-purpose models struggled with consistently. Measurable impacts included faster delivery of market-moving information to traders, more comprehensive coverage of global financial events, and reduced analyst workload for routine tasks. The limitation was that financial NLP models required continuous retraining to account for evolving market terminology, new financial instruments, and changing regulatory language across jurisdictions. Some analysts questioned whether NLP-driven trading signals created herding behavior in markets, as multiple firms acting on similar automated analysis could amplify market movements. Bloomberg’s NLP research publications are accessible through the Bloomberg Engineering Blog.
Duolingo’s NLP-Powered Language Learning
Duolingo needed to scale personalized language instruction to hundreds of millions of users across forty-plus languages without proportionally increasing its team of human content creators and linguists. Creating exercises, evaluating free-form responses, and adapting difficulty levels manually for each learner across every language combination was unsustainable at the platform’s growth rate. Duolingo deployed NLP models to generate exercise content, evaluate open-ended written responses, and provide grammatical explanations tailored to individual learner error patterns dynamically. The company integrated GPT-4 into its premium subscription tier, offering conversational practice with AI partners that adapt to the learner’s proficiency level in real time. Measurable outcomes included increased user engagement, higher completion rates for language courses, and more granular assessment of learner proficiency across all skill dimensions. The limitation was that NLP-powered evaluations sometimes accepted grammatically correct but pragmatically inappropriate responses, particularly in languages with complex honorific or register systems. Cost concerns also emerged because running large language model inference for hundreds of millions of users required significant computational infrastructure investment. Duolingo’s approach to NLP in education is detailed through their research publications and engineering blog.
Frequently Asked Questions
NLP stands for natural language processing, a subfield of artificial intelligence focused on enabling computers to understand, interpret, and generate human language in text and speech formats. The technology combines computational linguistics, machine learning, and deep learning to analyze language structure and meaning. NLP powers everyday tools including voice assistants, search engines, translation services, and chatbots across all major platforms.
Natural language processing works by breaking text or speech into structured components through stages including tokenization, syntactic parsing, and semantic analysis. Machine learning models trained on massive text datasets learn patterns that enable predictions about word meaning, sentence structure, and user intent automatically. Modern NLP systems use transformer architectures and attention mechanisms that process entire sentences simultaneously rather than word by word.
The most widely used NLP techniques include tokenization, named entity recognition, sentiment analysis, part-of-speech tagging, and text classification across industry applications. Word embeddings and contextual representations convert text into numerical formats that machine learning algorithms can process and compare efficiently. Advanced techniques include relation extraction, coreference resolution, and semantic role labeling that build deeper understanding of language structure.
Natural language processing encompasses the entire field of computational language analysis, while natural language understanding is a specific NLP subfield focused on comprehending meaning and intent. NLU deals with interpreting what a speaker or writer actually means, including handling ambiguity, context, and implied information beyond literal word definitions. NLP includes both understanding and generation tasks, while NLU focuses exclusively on the comprehension side of the equation.
Healthcare, financial services, retail, telecommunications, and legal services currently benefit most from NLP deployments based on market adoption rates and measurable outcomes. Healthcare uses NLP for clinical documentation, drug discovery, and patient matching while financial services deploy it for compliance, fraud detection, and market intelligence. Retail and e-commerce leverage NLP for customer service automation, review analysis, and personalized recommendation systems across digital channels.
Python dominates NLP development due to its extensive library ecosystem including NLTK, spaCy, Hugging Face Transformers, and deep learning frameworks like PyTorch and TensorFlow. Java and Scala remain popular for enterprise NLP deployments, particularly when integrating with big data processing frameworks like Apache Spark and Hadoop. JavaScript and Rust are emerging as options for edge deployment and browser-based NLP applications requiring low-latency processing.
Large language models are advanced NLP systems built on transformer architectures, trained on trillions of text tokens to perform a wide range of language tasks simultaneously. They represent the current state of the art in NLP, enabling capabilities like few-shot learning, code generation, and complex reasoning that previous approaches could not achieve. LLMs have made NLP accessible to non-technical users through conversational interfaces that accept natural language instructions rather than requiring programming skills.
The primary challenges include handling bias in training data, reducing hallucination in generative models, supporting low-resource languages, and ensuring data privacy across deployments. Computational costs for training and running large NLP models remain significant barriers for smaller organizations despite efficiency improvements in model architecture. Regulatory uncertainty around AI-generated content, liability for NLP system errors, and evolving privacy laws create compliance challenges for organizations deploying NLP globally.
Current NLP systems detect sarcasm and humor with limited reliability because these forms of expression depend heavily on cultural context, shared knowledge, and tonal cues often absent from text. Research progress has improved sarcasm detection accuracy on benchmark datasets, but real-world performance remains inconsistent across different communication styles and cultural contexts. Multimodal NLP systems that combine text analysis with vocal tone and facial expression analysis show promise for more reliable detection of non-literal language use.
Search engines use NLP to understand query intent, match user questions with relevant content, and generate featured snippets that directly answer common questions at the top of results. Google’s integration of BERT and subsequent language models improved the engine’s ability to interpret complex queries containing prepositions, negations, and conversational phrasing accurately. Modern search NLP processes both the query and the indexed content semantically, enabling matches based on meaning rather than exact keyword overlap alone.
Sentiment analysis is an NLP technique that classifies text as expressing positive, negative, or neutral emotional tone based on linguistic patterns and contextual cues. Businesses use sentiment analysis to monitor brand perception, analyze product reviews, track public opinion, and detect customer dissatisfaction across social media and support channels. Advanced sentiment analysis goes beyond polarity to identify specific emotions like anger, joy, surprise, and disappointment expressed within text at granular levels.
NLP is not the same as machine learning, though modern NLP relies heavily on machine learning techniques for training models that understand and generate human language. Machine learning provides the algorithms and optimization methods that NLP systems use to learn patterns from data, but NLP also incorporates linguistic theory and domain knowledge. NLP is best understood as an application domain within AI that draws on machine learning as its primary computational tool alongside rule-based and statistical methods.
NLP accuracy varies dramatically by task, with some applications like spam detection achieving above ninety-nine percent accuracy while others like sarcasm detection remain below seventy percent. On benchmark tasks like reading comprehension and question answering, top NLP models now match or exceed average human performance under controlled evaluation conditions. Real-world performance typically falls below benchmark results because production data contains noise, ambiguity, and domain variation that standardized tests do not fully capture.
The future of NLP includes autonomous language agents that complete multi-step tasks independently, multimodal systems that process text alongside images and audio, and efficient models that run on edge devices. Multilingual NLP will expand to serve more of the world’s seven thousand languages through improved transfer learning and community-driven data collection initiatives. Regulatory frameworks will mature alongside technology to ensure NLP systems are transparent, accountable, and equitable in their impact across all communities.
NLP implementation costs range from near-zero for cloud API-based solutions processing small volumes to millions of dollars for custom enterprise deployments requiring specialized model training and infrastructure. Cloud NLP services from major providers charge per-request fees that allow businesses to start with minimal investment and scale costs proportionally with usage. Custom NLP model development requires investment in data preparation, model training, infrastructure, and ongoing maintenance that typically exceeds one hundred thousand dollars for production-grade systems.
References
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2017, June 12). Attention is all you need. arXiv.Org. https://arxiv.org/abs/1706.03762
Mittal, Aayush. “What Is Adversarial Machine Learning?” Artificial Intelligence +, 29 Mar. 2023, https://www.aiplusinfo.com/blog/what-is-adversarial-machine-learning/. Accessed 5 June 2023.
Thomas, Alex. Natural Language Processing with Spark NLP: Learning to Understand Text at Scale. O’Reilly Media, 2020.