
Introduction
Reinforcement Learning with Human Feedback (RLHF) offers a fresh avenue for training machines to solve complex tasks where reward functions are challenging to define. Here, the model learns an optimal policy (a policy is essentially the “brain” of an agent) through human guidance rather than direct observation of reward data. RLHF is widely applicable, seen in large language models, robotics, auto-driving, clinical trials, and more.
Through reinforcement learning from human feedback (RLHF), a GPT model can be taught to be more accurate, truthful, and less prone to ‘hallucinating‘. Humans can guide the model to understand its ‘state of knowledge’ more clearly, express uncertainty where necessary, and avoid guessing responses.

In this comprehensive guide, we delve into the fundamentals, approaches, challenges, and applications of Reinforcement Learning with Human Feedback (RLHF). You will also learn about a successful case study, OpenAI’s ChatGPT, and its implementation of RLHF.
Table of contents
- Introduction
- Reinforcement Learning (RL) and Human Feedback (HF)
- Approaches to Incorporate Human Feedback into RL
- Human Feedback Collection and Annotation
- Algorithms for Reinforcement Learning Human Feedback
- ChatGPT: A Success Story in RLHF beyond GPT-4
- Applications of Reinforcement Learning with Human Feedback (RLHF)
- Challenges of Reinforcement Learning with Human Feedback (RLHF)
- Conclusion
- References
Reinforcement Learning (RL) and Human Feedback (HF)
Reinforcement Learning, problems are typically modeled as a Markov Decision Process (MDP), specified by the tuple (S, A, T, R) defining the set of possible world states, actions available to the agent, transition function, and a reward function. The role of an RL algorithm is to identify a policy that maximizes the expected reward from the environment.
The fundamental objective of an RL agent is to learn an optimal policy π* : S → A, which is a mapping from states to actions. The optimal policy tells the agent what action to take in each state so as to maximize the expected cumulative reward over the course of many steps.

An agent interacts with the environment in a series of discrete time steps. At each time step t, the agent observes the current state s_t, selects an action a_t according to its policy, receives a reward r_t from the environment, and transitions to a new state s_{t+1}.
Value functions quantify the ‘goodness’ of a state or action for the agent. A state-value function V(s) under a policy π gives the expected cumulative reward from starting in state s and following π thereafter. Similarly, an action-value function Q(s, a) under a policy π gives the expected cumulative reward from starting in state s, taking action a, and following π thereafter.
Mathematically, the state-value function is defined as:
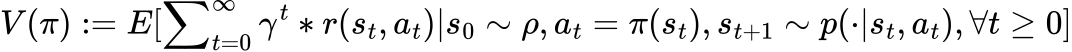
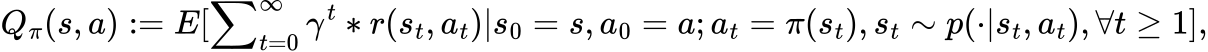
Where γ is the discount factor that determines the present value of future rewards. It is a number between 0 and 1, usually close to 1. For instance, γ might be set as 1/(1+r) for a certain discount rate r. A lower discount factor nudges the decision-maker to favor immediate actions, as opposed to delaying them indefinitely.
A policy that optimizes the aforementioned function is referred to as an optimal policy, commonly denoted by π*. Interestingly, an MDP might have several distinct optimal policies. However, owing to the Markov property, it’s shown that the optimal policy is a function of only the current state, thus simplifying the task of optimal policy determination.
To further measure the quality of policy π, the Q-value function, Q_π(s, a), is introduced which represents the expected long-term return, starting from a specific state-action pair (s, a):
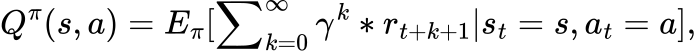
A deterministic policy π : S → A signifies a policy where given a state, the action is determined without any randomness. The expected long-term return, V(π), under such a policy can be represented as:

The cornerstone of RL is the Bellman Optimality Equation, which states that the optimal Q-value function, Q*, satisfies the following:
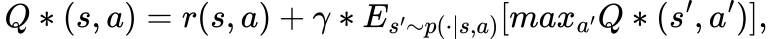
This equation expresses the fact that the value of a state-action pair (s, a) is the immediate reward r(s, a) plus the maximum discounted (γ) future value achievable from the next state s’.
At the heart of RL lies the process of exploration and exploitation. Exploration helps the agent find more information about the environment, while exploitation helps the agent make the best decision based on its current knowledge. Balancing these two conflicting objectives is still a challenge in RL.
An agent excessively focused on exploration might squander opportunities for obtaining known rewards. Conversely, an agent overly concentrated on exploitation might miss out on discovering potentially more rewarding experiences.
By continuously fine-tuning this balance, we can design RLHF agents that learn more efficiently and perform more robustly, even in complex environments. Achieving this equilibrium enables the agent to maximize its understanding of human feedback while also being versatile enough to discover and adapt to new scenarios.
Approaches to Incorporate Human Feedback into RL
There are several ways to incorporate human feedback into reinforcement learning:
- Reward Shaping: Humans provide additional rewards to guide the agent’s learning process. This is typically done by adding a reward function that provides extra rewards based on human intuition or domain knowledge.
- Policy Shaping: Human feedback directly influences the agent’s policy, for example, by advising the agent on which actions to take during learning.
- Inverse Reinforcement Learning: Here, the agent learns from observing human behavior. The underlying assumption is that human actions implicitly reveal their reward function.
- Learning from Comparisons: Humans compare two or more actions or trajectories, and the agent learns the better option from these comparisons.
These methods are not mutually exclusive and can be used in combination to provide more robust and effective learning.
Human Feedback Collection and Annotation
Leveraging the insights from human trainers, RLHF systems can effectively utilize human annotations and advice, accelerating the learning process and aligning AI behaviors with human values. This involves humans interacting with the learning system, either by providing feedback on the system’s actions, comparing different actions or trajectories, or demonstrating the correct behavior. This feedback is then used to inform the reinforcement learning process.
Feedback can be provided in a number of ways, including:
- Ranking or comparison: The system presents multiple potential actions or outputs to the human, who then rank them based on their quality or appropriateness.
- Direct feedback: The human provides feedback on specific actions taken by the system, such as indicating whether an action was correct, providing a numerical score, or even providing a corrected version of the action.
Collecting feedback effectively and efficiently is crucial, as the quality and quantity of feedback directly impact the system’s ability to learn and improve.
Algorithms for Reinforcement Learning Human Feedback
Several algorithms have been developed for RLHF, each with their unique strengths and challenges. These algorithms combine reinforcement learning techniques with human feedback to improve the learning process. Here are a few notable ones:
Proximal Policy Optimization (PPO): PPO is a policy optimization method used widely in RL. It’s designed to address the challenges of policy optimization in complex environments.
Deep Deterministic Policy Gradient (DDPG): DDPG is an off-policy algorithm and an actor-critic method that concurrently learns a Q-function and a policy. It uses off-policy data and the Bellman equation to update the Q-function and uses the Q-function to update the policy.
Cooperative Inverse Reinforcement Learning (CIRL): CIRL is a framework for RL where both the human and the AI agent cooperate to achieve a shared goal, with the agent trying to learn the human’s reward function through their actions.
ChatGPT: A Success Story in RLHF beyond GPT-4
Deep Reinforcement Learning combines deep learning and reinforcement learning techniques to enable AI systems to learn the best actions possible in virtual simulation environments.
Proposed by OpenAI, combines RL and HF to create safer AI models. RLHF utilizes human feedback to solve modern RL environments, as demonstrated in Atari games and MuJoCo simulations. The novel aspect of RLHF is that the reward function is learned rather than hand-crafted, bridging the gap between human understanding and AI learning.
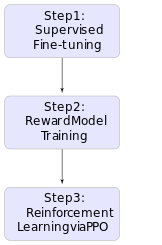
Step 1: Data Collection and Human Evaluation
In the first step, the goal is to collect samples from existing policies and send comparisons for human evaluation. For any given task, these samples could come from a variety of sources, including the current policy (the current state of the machine learning model’s behavior), the initial policy (the model’s behavior at the start of training), and various baseline models.
Here’s how it works:
- Generate outputs for a range of input data points using the different policies mentioned above.
- For each data point, select pairs of outputs and send these pairs to human evaluators.
- The evaluators are tasked with judging which output from each pair is better.
For example, in a machine learning task of image classification, the model’s “outputs” could be the predicted labels for a set of images, and the human evaluators would judge which set of labels is more accurate.
Step 2: Learning a Reward Model
The second step involves training a reward model based on the human evaluations from Step 1. This is a type of supervised learning, where the input is an output from the policy (e.g., a classification label, a generated sentence, etc.), and the target is the human evaluation of that output.
Specifically, for each input-output pair, the reward model is trained to predict the log odds that a particular output is the better one, as judged by the human evaluators. The log odds is simply the logarithm of the probability of an event happening divided by the probability of it not happening. If P is the probability of the event (in this case, the output being the better one), then the log odds are calculated as log(P / (1 – P)).
This reward model can be any type of model that is suitable for the task at hand, such as a neural network for complex tasks or a simpler model for less complex tasks.
Step 3: Optimizing the Policy
The third step involves optimizing the policy based on the reward model from Step 2. This is where reinforcement learning comes into play.
The output of the reward model — the logit output, which is the input to the final activation function of the model — is treated as a reward signal. This reward signal is then used to optimize the policy using reinforcement learning.
The specific algorithm used may vary, but Proximal Policy Optimization (PPO) is a popular choice due to its stability and efficiency. In PPO, the objective is to maximize the expected reward while keeping the new policy close to the old policy.
This is done by optimizing the following objective function:

Here, θ represents the parameters of the policy, E_t is the expectation over the time steps, r_t(θ) is the ratio of the probabilities under the new and old policies, A_t is the advantage function at time step t, and ε is a hyperparameter that controls how much the policy is allowed to change at each step.
By iterating through these steps — collecting data, learning a reward model, and optimizing the policy — the machine learning model gradually improves its performance on the task at hand.
Applications of Reinforcement Learning with Human Feedback (RLHF)
RLHF’s application spans various domains, particularly in natural language processing (NLP), where it has been instrumental in refining conversational agents, text summarization, and natural language understanding. It allows language models to generate more verbose responses, reject inappropriate or out-of-scope queries, and offer outputs that align with intricate human values and preferences. OpenAI’s ChatGPT and InstructGPT, and DeepMind’s Sparrow are remarkable examples of RLHF-trained language models.
Employing pre-trained models in the context of RLHF can drastically accelerate the learning process, providing the AI agent with a robust starting point. These models, having undergone extensive training in diverse environments, equip the agent with a well-rounded understanding of various scenarios, enabling it to respond more effectively in novel situations.
RLHF also has a remarkable presence in the gaming industry. Esteemed entities such as OpenAI and DeepMind have harnessed the power of RLHF to coach AI agents in mastering Atari games, basing their strategies on human preferences. Notably, these RLHF-trained agents have often managed to exceed the performance of human players, displaying an impressive capability to learn and adapt.
Challenges of Reinforcement Learning with Human Feedback (RLHF)
Reinforcement Learning from Human Feedback (RLHF) has shown immense promise in training artificial intelligence systems. However, it is accompanied by a host of challenges that researchers are currently grappling with. Here are five significant challenges they face:
Failures and Regularization Needs: RLHF models sometimes fail unexpectedly. It’s unclear whether these failures will disappear as capabilities scale. Regularization is crucial to prevent the model from diverging drastically from the desired outcomes. But determining the constant of regularization often feels arbitrary and brings its own challenges, such as potential mode collapse – an overbearing bias towards certain patterns or completions.
Incentives Issues and Goal-Directedness: RLHF can make AI systems overly goal-directed. In an effort to achieve the desired outcome or reward, these systems may end up becoming too narrow in their focus. For instance, an AI model trained using a positive sentiment reward system might obsessively generate content around wedding parties, perceived as extremely positive, irrespective of the prompt given.
Opaque Thoughts and Capability Externalities: RLHF might lead to models that “think” in opaque ways, making their decision-making process difficult to interpret. The added capabilities resulting from RLHF might exceed base models, potentially leading to harmful externalities. As the capability increases, it could further shrink timelines, exacerbating the issue.
Human Feedback Limitations: The RLHF process requires significant human feedback. But this approach suffers from human limitations, including error-prone evaluations and potential biases. The cost of obtaining necessary data might become prohibitive as systems advance, requiring more complex feedback. Simultaneously, the number of qualified human annotators might fall short. These challenges can lead to inconsistencies in the training process and may not always result in the desired AI behavior.
Conclusion
Interactive Machine Learning has seen a substantial rise, with an increased interest in applying Reinforcement Learning from Human Feedback. RLHF techniques have considerable potential in Autonomous Systems, improving their learning efficiency and adaptability to new scenarios. Generative Models have found significant application in RLHF, serving to predict potential future scenarios for the agent to learn from.
The guide provides an insightful exploration into the application of reinforcement learning with human feedback, a field with vast potential for diverse applications, including autonomous driving.
Reinforcement learning models provide a powerful framework for training agents to interact with uncertain environments, creating the capability to map observations from the observation space to actions within the action spaces effectively. When coupled with human demonstrations, these models become more robust and effective, allowing for a form of learning that aligns well with human advice.
Our understanding of training language models is critical in this context. The use of human language as a medium for providing feedback and advice, as a human reinforcement function, serves as a more natural way to impart complex knowledge to reinforcement learning models. This approach also offers an intuitive platform for providing corrective demonstrations when the model’s actions diverge from the expected behavior.
The use of a loss function is integral to the reinforcement learning process, guiding the learning towards minimizing errors and optimizing performance. Reward engineering also plays a significant role in shaping the behavior of reinforcement learning models. It guides the agent transitions from its initial model to a proficient actor within the environment, leading to the successful completion of tasks.
The integration of unsupervised learning presents an exciting avenue for future development, enabling models to extract useful features from raw data autonomously, reducing reliance on manual feature engineering, and improving the model’s adaptability.
Overall, the synergistic combination of reinforcement learning with human feedback, coupled with strategies such as the use of corrective demonstrations, introduces a robust, flexible, and intuitive approach to creating powerful, responsive agents. This guide underscores the potential of these techniques in fostering enhanced machine learning models capable of operating efficiently and effectively in a myriad of complex and uncertain environments.

References
Bonaccorso, Giuseppe. Machine Learning Algorithms. Packt Publishing Ltd, 2017.
Munro, Robert, and Robert Monarch. Human-in-the-Loop Machine Learning: Active Learning and Annotation for Human-Centered AI. Simon and Schuster, 2021.
Sutton, Richard S., and Andrew G. Barto. Reinforcement Learning, Second Edition: An Introduction. MIT Press, 2018.