Introduction
Modern IT environments generate millions of data points every hour, stretching human operators well beyond their capacity to interpret signals and respond to incidents in real time. The global AIOps market reached an estimated USD 16.6 billion in 2025 and is on track to surpass USD 85 billion by 2035, reflecting an industry-wide recognition that traditional monitoring alone cannot sustain digital operations at scale. Organizations deploying AIOps platforms have reported reductions in mean time to resolution as high as 45 percent, according to Gartner’s Market Guide for AIOps Platforms. These gains do not arrive overnight, and they require deliberate investments in data quality, team readiness, and strategic tooling. The benefits of AIOps extend far beyond simple alert management, touching every layer of IT service delivery from cost optimization to customer satisfaction. This article explores the specific, measurable advantages that organizations cultivate when they commit to an AIOps strategy grounded in machine learning, automation, and operational intelligence.
Quick Answers on the Benefits of AIOps
What are the primary benefits of AIOps for IT operations teams?
AIOps reduces alert noise, accelerates incident resolution, enables predictive maintenance, and frees engineering talent for strategic projects, delivering measurable gains in uptime and operational efficiency.
How does AIOps improve mean time to resolution?
AIOps platforms automate event correlation and root cause analysis, compressing diagnosis cycles from hours to minutes and reducing mean time to resolution by up to 45 percent across hybrid IT environments.
Can AIOps help reduce IT operational costs?
Yes, organizations using AIOps achieve IT cost savings of up to 30 percent by consolidating monitoring tools, automating repetitive workflows, and optimizing cloud resource allocation through predictive analytics.
Key Takeaways
- AIOps strengthens cross-functional collaboration by providing a unified operational view that bridges development, security, and infrastructure teams.
- AIOps platforms correlate thousands of alerts into actionable incidents, reducing noise by 40 to 70 percent and eliminating alert fatigue for operations teams.
- Predictive analytics powered by machine learning enables proactive problem prevention, catching anomalies before they escalate into customer-facing outages.
- Organizations report IT operational cost reductions of up to 30 percent through tool consolidation, automated remediation, and optimized resource provisioning.
Table of contents
- Introduction
- Quick Answers on the Benefits of AIOps
- Key Takeaways
- Understanding AIOps and What It Delivers
- Why IT Teams Are Turning to AIOps
- Faster Incident Detection and Resolution
- Noise Reduction and Alert Fatigue Relief
- Proactive Problem Prevention Through Predictive Analytics
- Cost Savings Across IT Operations
- Enhanced Collaboration Between IT Teams
- Scalability for Hybrid and Multi-Cloud Environments
- Strengthened Security and Compliance Posture
- Smarter Root Cause Analysis at Machine Speed
- Automating Repetitive Tasks to Free Engineering Talent
- Improved End-User and Customer Experience
- Data-Driven Decision Making in Real Time
- Building Organizational Resilience with AIOps
- Risks and Challenges When Adopting AIOps
- The Ethical Dimension of AI-Driven Operations
- Where AIOps Is Heading Next
- Key Insights
- How AIOps Benefits Compare Across Key Operational Dimensions
- Real-World Examples
- Case Studies
- Frequently Asked Questions About AIOps Benefits
Understanding AIOps and What It Delivers
AIOps applies artificial intelligence and machine learning to IT operations, automating event correlation, anomaly detection, root cause analysis, and incident remediation across complex hybrid and multi-cloud environments to improve service reliability and operational efficiency.
AIOps Benefits Impact Calculator
Adjust your current IT operations profile to estimate the measurable improvements AIOps can deliver across incident resolution, cost reduction, and team productivity.
Your AIOps Impact Summary
Based on your current profile, AIOps would reduce your daily actionable alerts from 1,500 to approximately 150, compress your average resolution time from 120 minutes to 66 minutes, and save an estimated $75,000 per month. Your team of 12 would reclaim roughly 4 full-time equivalents of engineering capacity currently spent on reactive tasks.
Why IT Teams Are Turning to AIOps
The complexity of modern IT infrastructure has reached a point where manual monitoring and siloed tooling create more problems than they solve. Hybrid environments, microservices architectures, and distributed cloud deployments produce telemetry volumes that overwhelm human operators, leading to missed signals and extended outages. Traditional threshold-based alerting fires indiscriminately, burying genuine incidents under thousands of redundant notifications that erode team morale and slow response times. Over 84 percent of organizations are currently using or planning to use AIOps to manage this complexity, according to a recent industry survey cited by TechRadar. The shift is not merely technological but cultural, as teams recognize that reactive firefighting cannot sustain the velocity of modern software delivery cycles.
AIOps addresses these pressures by introducing intelligence into the operational pipeline, replacing rigid rules with adaptive models that learn from historical patterns and real-time signals. Machine learning algorithms establish dynamic baselines for every application, service, and infrastructure component, detecting subtle deviations that would escape even the most experienced engineers. The result is an operations model that anticipates failures rather than simply reacting to them, fundamentally changing how teams allocate their time and attention. IT leaders increasingly view AIOps not as an optional enhancement but as a structural requirement for maintaining service-level agreements in environments that grow more complex with every deployment. This recognition is driving AIOps adoption across industries from financial services to healthcare, where the cost of downtime can reach millions of dollars per hour, as noted by Enterprise Management Associates research on IT outage costs.
Faster Incident Detection and Resolution
Speed is the currency of IT operations, and AIOps dramatically compresses the time between detecting an issue and restoring service. Traditional incident management workflows require operators to manually sift through logs, correlate alerts from disparate tools, and escalate through multiple tiers before reaching a resolution. AIOps platforms automate this entire chain by ingesting data from monitoring systems, APM tools, and log aggregators, then applying machine learning to identify root causes in minutes rather than hours. Gartner reports that organizations using AIOps platforms can reduce MTTR by up to 45 percent by automating event correlation and root cause analysis. This acceleration translates directly into reduced downtime, fewer SLA breaches, and a measurable improvement in customer trust that compounds over time.
Beyond raw speed, AIOps brings precision to incident detection that threshold-based systems cannot match. Static thresholds generate false positives during normal traffic fluctuations and miss genuine anomalies that fall just below predetermined limits. Machine learning models trained on historical performance data establish dynamic baselines that adapt to seasonal patterns, deployment cycles, and workload variations, catching deviations that signal emerging failures. This precision means that when an alert fires, engineers can trust that it represents a genuine issue requiring attention, rather than another false alarm competing for their focus. The reduction in false positives alone represents a significant operational improvement, with some deployments reporting noise reduction of 40 to 70 percent as dynamic baselines replace static thresholds across the monitoring stack.
The compounding effect of faster detection and resolution extends beyond individual incidents to reshape organizational capacity for innovation. When engineers spend less time diagnosing outages, they reclaim bandwidth for automation projects that boost long-term business value. Teams that previously operated in perpetual crisis mode begin proactively hardening systems, refining deployment pipelines, and building self-healing capabilities that prevent entire categories of incidents from recurring. This virtuous cycle, where faster resolution feeds proactive improvement, represents one of the most valuable long-term benefits that organizations nurture through AIOps adoption.
Noise Reduction and Alert Fatigue Relief
Alert fatigue is one of the most insidious problems in IT operations, silently degrading team performance long before it manifests as a missed outage or a resigned engineer. Enterprise network operations centers typically receive thousands of alerts daily, and studies indicate that as many as 85 percent of those alerts are false positives or duplicates that demand attention without delivering actionable insight. AIOps platforms use event correlation algorithms to group related alerts into unified incidents, reducing the volume of notifications that reach operators by an order of magnitude. A telecommunications provider profiled in an industry case study reduced daily alert volume from 2,000 to fewer than 200 meaningful incidents, transforming their NOC from a reactive triage center into a proactive maintenance team.
The psychological impact of noise reduction on engineering teams should not be underestimated, as burnout driven by constant alert bombardment contributes directly to attrition in operations roles. When operators know that each notification they receive represents a genuine, prioritized incident with contextual information attached, they engage more effectively and make better decisions under pressure. AIOps transforms the operator experience from one of overwhelming noise to one of curated, high-signal intelligence that respects both their expertise and their cognitive limits. This shift in operational quality also enables organizations to differentiate between automation and genuine AI-driven insight, recognizing that noise reduction through intelligent correlation is fundamentally different from simply suppressing alerts through crude filtering rules.
Proactive Problem Prevention Through Predictive Analytics
Moving beyond the relief of reduced noise, AIOps enables a paradigm shift from reactive incident management to proactive problem prevention that catches failures before they reach customers. Traditional monitoring tells you that something broke; predictive analytics powered by machine learning tells you that something is about to break, giving your team a window of opportunity to intervene before impact occurs. AIOps models analyze historical performance data alongside real-time signals to identify patterns that precede known failure modes, such as gradual memory leaks, disk utilization trends approaching capacity, or latency patterns that indicate emerging network congestion. IDC has predicted that by 2026, 90 percent of large organizations will rely on AI-driven monitoring to proactively manage IT performance, reflecting the growing recognition that prevention is more valuable than cure.
The economic case for proactive prevention is compelling when measured against the cost of unplanned downtime. Financial institutions have doubled monitoring budgets because a single hour of downtime costs upwards of USD 2 million in lost transactions and compliance penalties, according to AIOps market analysis by Mordor Intelligence. Predictive analytics addresses this exposure directly by identifying emerging risks days or weeks before they would trigger a customer-facing incident, allowing teams to schedule remediation during maintenance windows rather than scrambling during peak traffic hours. The shift from reactive to predictive operations represents the single largest return on investment that most organizations realize from their AIOps platform, often paying back the entire implementation cost within the first year of deployment. This predictive capability mirrors the analytics approaches that leading technology companies have used to optimize supply chains and customer experiences for over a decade.
Predictive analytics also enables capacity planning that balances cost efficiency with performance headroom, eliminating the guesswork that leads to either over-provisioning or under-provisioning of cloud resources. AIOps platforms continuously analyze workload patterns and forecast future resource requirements, recommending scaling actions that maintain service quality while minimizing infrastructure spend. This capability is particularly valuable in cloud-native environments where resource allocation decisions are made continuously and where the difference between a well-tuned autoscaling policy and a poorly configured one can represent hundreds of thousands of dollars annually in unnecessary compute costs.
Cost Savings Across IT Operations
Cost reduction is often the first benefit that captures executive attention when evaluating AIOps platforms, and the savings can be substantial across multiple dimensions of IT spending. McKinsey has reported that companies adopting AI-driven operations can achieve IT cost savings of up to 30 percent through improved automation and resource optimization, a figure that reflects gains from tool consolidation, reduced labor for routine tasks, and optimized cloud resource provisioning. Many enterprises operate a sprawling ecosystem of monitoring tools acquired over years of organic growth, with overlapping capabilities and siloed data that increase licensing costs while fragmenting operational visibility. AIOps platforms serve as a consolidation layer that unifies data from these disparate sources, enabling organizations to retire redundant tooling and reduce the licensing burden that accumulates when every team selects its own preferred monitoring solution.
The labor savings from AIOps extend beyond simple headcount reduction to encompass a fundamental reallocation of engineering talent toward higher-value activities. When L1 and L2 support tickets are reduced by 35 to 40 percent through automated triage and resolution, as reported across multiple Thoughtworks AIOps deployments, the engineers who previously handled those tickets are freed to work on platform improvements, reliability engineering, and architectural initiatives that strengthen the organization’s competitive position. This reallocation is not about eliminating jobs but about redirecting skilled professionals from repetitive troubleshooting to creative problem-solving that delivers lasting value. The distinction matters because organizations that frame AIOps solely as a cost-cutting measure often undermine the cultural buy-in needed for successful adoption.
Cloud cost optimization represents a third major savings dimension, particularly for organizations running hybrid or multi-cloud environments where resource sprawl can silently inflate infrastructure budgets. AIOps platforms monitor resource utilization in real time, identifying idle instances, oversized virtual machines, and inefficient storage configurations that waste money without contributing to service quality. By recommending right-sizing actions and automating resource scaling based on predicted demand patterns, AIOps helps organizations extract maximum value from their cloud investments while maintaining the performance headroom needed to handle traffic spikes without service degradation.
Enhanced Collaboration Between IT Teams
AIOps breaks down the operational silos that have historically fragmented IT organizations, creating a shared intelligence layer that connects development, operations, security, and business teams around a common understanding of system health. Traditional monitoring tools tend to be domain-specific, giving network engineers visibility into network metrics, application developers insight into APM data, and security analysts access to threat intelligence, while nobody has a comprehensive view of how these domains interact during an incident. AIOps platforms aggregate and correlate data across all of these domains, presenting enriched incidents that contain the full context needed for cross-functional diagnosis and resolution. This unified visibility transforms incident response from a series of siloed investigations into a coordinated effort where every team contributes their expertise to a shared understanding of the problem.
The collaboration benefits of AIOps are amplified when enriched incidents are integrated with ChatOps platforms, ITSM workflows, and collaboration tools that teams already use daily. When an AIOps platform detects an incident and automatically posts relevant context, topology maps, and suggested remediation steps into a Slack channel or Microsoft Teams conversation, it eliminates the communication overhead that typically delays cross-team coordination during critical events. Engineers from different teams can review the same data simultaneously, share observations in real time, and converge on a resolution without waiting for sequential escalation through a rigid incident management hierarchy. Successful AIOps implementation requires this kind of cross-functional collaboration, ensuring that insights are actionable and that automation aligns with organizational goals rather than operating in a vacuum.
Scalability for Hybrid and Multi-Cloud Environments
As organizations expand their infrastructure across on-premises data centers, public clouds, and edge locations, the scalability demands placed on monitoring and management tools grow exponentially. AIOps platforms are purpose-built for this distributed reality, ingesting telemetry from thousands of devices, services, and applications across heterogeneous environments without losing correlation context or analytical fidelity. Gartner’s Hype Cycle for ITSM has highlighted that AIOps adoption is becoming mainstream specifically because organizations running distributed and cloud-native applications cannot maintain operational visibility through traditional tools alone. The ability to scale monitoring and analysis alongside infrastructure growth is not just convenient; it is existential for organizations whose competitive advantage depends on the reliability of globally distributed digital services.
AIOps platforms handle the scale challenge not by simply processing more data but by extracting more intelligence from every data point through adaptive algorithms that improve their accuracy as data volumes increase. This is a crucial distinction from traditional monitoring approaches that degrade under volume pressure, generating more noise as the environment grows and producing diminishing returns from each additional monitoring agent deployed. Machine learning models thrive on data volume, using larger datasets to build more accurate baselines and more precise anomaly detection capabilities that improve over time without requiring manual threshold tuning. The foundational machine learning principles that power this scalability are the same concepts that drive advances in natural language processing, computer vision, and other AI domains, applied specifically to the unique challenges of operational data at scale.
Cloud-based AIOps deployments offer an additional scalability advantage by eliminating the need for organizations to provision and maintain the compute infrastructure required for large-scale data analysis. Cloud-native AIOps platforms scale their processing capacity automatically in response to data ingestion volumes, absorbing traffic spikes during peak business periods or major incidents without requiring advance provisioning. This elastic scalability is particularly valuable for organizations that experience highly variable workload patterns, such as e-commerce companies facing seasonal traffic surges or financial services firms processing elevated transaction volumes during market events.
Strengthened Security and Compliance Posture
The intersection of AIOps and cybersecurity represents one of the most rapidly evolving areas of benefit, as organizations recognize that the same machine learning techniques powering operational intelligence can detect security threats hidden within vast streams of telemetry data. AIOps platforms continuously analyze network traffic patterns, user behavior, and application logs to identify anomalies that may indicate unauthorized access attempts, data exfiltration, or lateral movement by threat actors within the network. This capability extends the organization’s security posture beyond traditional perimeter defenses by bringing intelligent, continuous monitoring to every layer of the technology stack. The convergence of security and operations monitoring eliminates the blind spots that attackers exploit when these functions operate in isolation.
Compliance requirements in regulated industries create an additional layer of operational burden that AIOps helps manage through automated audit trails, policy enforcement, and continuous monitoring for configuration drift. Financial services firms, healthcare organizations, and government agencies must demonstrate ongoing compliance with regulations that mandate specific security controls, data handling practices, and incident response procedures. AIOps platforms automate the collection and correlation of compliance-relevant data, generating audit-ready reports that reduce the manual effort required to satisfy regulatory examinations. Forrester has highlighted that automation tools like AIOps are increasingly used to support regulatory requirements and data governance frameworks across multiple industry verticals.
Security teams benefit from AIOps not only through threat detection but also through the automated correlation of security events with operational context that reveals the full scope and impact of an incident. When a suspicious login event occurs simultaneously with an unusual data access pattern and an unscheduled configuration change, AIOps correlates these signals into a single enriched alert that conveys the probable attack chain, rather than presenting three separate notifications that a human analyst must manually connect. This contextual enrichment accelerates security incident response times and reduces the expertise threshold required to triage complex threats, enabling organizations to maintain effective security operations even as the threat landscape grows more sophisticated.
The healthcare sector illustrates the combined security and compliance value of AIOps particularly well, where patient data protection requirements intersect with the need for continuous system availability. Healthcare organizations deploying AIOps platforms benefit from unified monitoring that ensures both the security of protected health information and the uptime of clinical systems that support patient care. The healthcare segment is experiencing a 16.66 percent compound annual growth rate in AIOps adoption through 2031, according to market research by Mordor Intelligence, driven by the strict audit trail and patient safety imperatives that make intelligent automation a regulatory necessity rather than a discretionary investment.
Smarter Root Cause Analysis at Machine Speed
Root cause analysis has traditionally been one of the most time-consuming and expertise-dependent activities in IT operations, requiring senior engineers to piece together evidence from multiple monitoring tools while under intense pressure to restore service. AIOps transforms root cause analysis from an artisanal investigation into a systematic, data-driven process that leverages machine learning to identify causal relationships across complex dependency chains in minutes rather than hours. AIOps platforms maintain real-time topology maps that capture the dependencies between applications, services, and infrastructure components, enabling the system to trace impact chains automatically when failures occur and pinpoint the originating fault with high confidence. This capability is especially valuable in microservices architectures where a single degraded component can cascade failures across dozens of downstream services.
Automated root cause analysis becomes even more powerful when AIOps platforms correlate current incidents with historical patterns, identifying recurring failure modes that may have different surface symptoms but share a common underlying cause. An application team investigating slow response times might discover through AIOps analysis that the current latency spike shares a root cause with three previous incidents that manifested as connection timeouts, all tracing back to the same database connection pool configuration that becomes problematic under specific load conditions. This pattern recognition capability transforms individual incidents into systemic improvements, enabling teams to address root causes permanently rather than repeatedly treating symptoms. Understanding deep learning techniques and their operational applications provides useful context for how AIOps models achieve this level of analytical sophistication.
Advanced AIOps implementations are beginning to incorporate large language models for root cause analysis, using natural language reasoning to explain complex causal chains in terms that both technical and non-technical stakeholders can understand. These explanations go beyond identifying which component failed to articulate why the failure occurred, what sequence of events led to the current state, and what actions will prevent recurrence. This explainability dimension addresses one of the historical challenges of AI-driven operations, where teams sometimes struggled to trust automated diagnoses they could not fully understand or verify independently.
Automating Repetitive Tasks to Free Engineering Talent
Repetitive, low-value tasks consume a disproportionate share of engineering capacity in organizations that have not adopted AIOps, trapping skilled professionals in cycles of manual log review, threshold tuning, ticket routing, and routine maintenance that could be automated. AIOps platforms identify these repetitive patterns and execute predefined remediation playbooks automatically, handling common incidents such as service restarts, resource scaling, log rotation, and certificate renewals without requiring human intervention. The automation extends beyond simple scripted actions to include conditional logic that assesses incident classification certainty and verifies remediation prerequisites before executing, preventing automation from amplifying novel failures that do not match expected patterns.
The talent freed by AIOps automation does not disappear from the organization; it is redirected toward activities that generate lasting competitive advantage, including platform engineering, reliability architecture, and innovation projects. This reallocation represents a strategic transformation for operations teams, evolving their role from reactive maintenance to proactive engineering that builds resilience into systems before failures occur. Organizations that leverage robotic process automation alongside AIOps amplify this effect, creating an automation ecosystem where routine operational and business process tasks are handled by intelligent systems while human expertise is reserved for creative problem-solving, architectural decisions, and strategic planning that drive the organization forward.
Improved End-User and Customer Experience
Every operational improvement that AIOps delivers ultimately manifests as a better experience for the end users and customers who depend on digital services for their daily lives and business activities. When incidents are detected faster, resolved more quickly, and prevented more frequently, customers encounter fewer disruptions, faster page loads, and more reliable access to the services they rely on. This connection between operational excellence and customer satisfaction is not abstract; it is measurable through metrics like customer satisfaction scores, net promoter scores, and digital experience monitoring data that correlate directly with system availability and performance metrics. Organizations deploying AIOps platforms report significant reductions in IT-related customer complaints as proactive issue detection catches problems before they reach the user experience layer.
The proactive dimension of AIOps is especially impactful for customer experience because it addresses the category of issues that customers notice but cannot articulate, such as gradual performance degradation that makes an application feel sluggish without triggering an explicit error. AIOps models trained on application performance data detect these subtle trends and alert teams before the degradation reaches a threshold that prompts customer complaints or abandonment. This ability to maintain experience quality at the margins, catching the small issues that accumulate into significant dissatisfaction, distinguishes organizations that nurture AIOps from those that rely on reactive monitoring and customer-reported incidents as their primary signal for service quality. The principles behind this proactive approach extend beyond IT operations into broader digital transformation initiatives powered by AI and IoT that reshape how organizations interact with their customers.
Customer experience gains from AIOps compound over time as the platform accumulates operational data and refines its predictive models, becoming progressively better at anticipating and preventing the specific failure modes that impact each organization’s unique service delivery chain. Early AIOps deployments may focus on reducing the most frequent and impactful incidents, but mature implementations develop the predictive sophistication to catch novel failure patterns that have not previously occurred, extending the protective envelope of proactive monitoring into territory that no amount of manual analysis could cover.
Data-Driven Decision Making in Real Time
Building on improved customer experience outcomes, AIOps creates a foundation for data-driven decision making that extends beyond the operations team to inform business strategy, capacity planning, and technology investment decisions. AIOps platforms generate continuous intelligence about system performance, resource utilization, and service delivery quality that, when analyzed alongside business metrics, reveals the operational drivers of revenue, customer retention, and competitive differentiation. This intelligence enables business leaders to make informed decisions about technology investments based on empirical evidence rather than intuition or vendor promises, aligning IT spending with the operational capabilities that deliver measurable business outcomes.
Real-time operational intelligence from AIOps platforms also transforms how organizations approach capacity planning and infrastructure investment, replacing annual forecasting exercises with continuous, data-driven resource optimization. Traditional capacity planning relies on conservative estimates and significant safety margins that result in over-provisioning, while AIOps provides the predictive accuracy needed to right-size infrastructure investments with confidence. This precision in resource allocation is not merely a cost-saving measure; it represents a fundamental improvement in how organizations translate operational data into strategic decisions about where to invest, what to optimize, and which capabilities will drive future growth. The analytical frameworks that support this decision making share conceptual foundations with big data analytics approaches that have transformed other business functions from marketing to supply chain management.
AIOps enables a feedback loop between operational outcomes and engineering practices that accelerates organizational learning and continuous improvement. When every incident generates structured data about its causes, resolution steps, and downstream impact, teams can analyze these datasets to identify systemic patterns that inform architectural decisions, deployment practices, and testing strategies. This data-driven approach to operational improvement replaces anecdotal experience and tribal knowledge with empirical evidence that guides investment in reliability improvements where they will have the greatest impact.
Change management also benefits from AIOps intelligence, as platforms can analyze the operational risk associated with proposed deployments by comparing them against historical patterns of change-related incidents. When AIOps data shows that deployments affecting specific components during specific time windows have historically correlated with elevated incident rates, teams can adjust their deployment schedules and risk mitigation strategies accordingly. This capability transforms change management from a process driven by organizational policies and approval hierarchies into an evidence-based practice that reduces the risk of change-related outages while maintaining deployment velocity.
Building Organizational Resilience with AIOps
Organizational resilience in the context of IT operations means more than preventing individual incidents; it means building the institutional capacity to absorb disruptions, adapt to changing conditions, and continue delivering value even when unexpected failures occur. AIOps contributes to resilience by creating an operational intelligence layer that gives organizations visibility into their risk posture, identifies single points of failure before they are tested by real incidents, and enables rapid recovery through automated remediation and informed decision making. This resilience extends into smart infrastructure initiatives where cities and enterprises alike are deploying AI-powered systems to maintain critical services under adverse conditions, applying the same principles of predictive monitoring and automated response that AIOps brings to IT operations.
Resilient organizations nurture AIOps as part of a broader reliability engineering practice that treats operational intelligence as a continuous discipline rather than a tool implementation. These organizations invest in data quality, model training, and process integration that improve AIOps effectiveness over time, recognizing that the platform’s value grows as it accumulates organizational knowledge and operational context. The alternative, treating AIOps as a point solution that is deployed once and left to operate independently, typically produces disappointing results because the platform lacks the contextual richness needed to make accurate predictions and relevant recommendations in complex, evolving environments.
Risks and Challenges When Adopting AIOps
Every transformative technology carries implementation risks, and AIOps is no exception. The most common failure mode in AIOps deployments is poor data quality, where the garbage-in-garbage-out principle amplifies the consequences of inconsistent log formats, incomplete metric coverage, and fragmented monitoring architectures. AIOps models can only learn from the data they receive, and when that data is noisy, incomplete, or unrepresentative of actual system behavior, the resulting predictions and correlations degrade rather than improve operational outcomes. Organizations that rush to deploy AIOps without investing in data normalization, monitoring coverage, and telemetry governance often find that the platform generates unreliable insights that erode trust before it has a chance to demonstrate value.
Integration complexity represents another significant challenge, particularly for organizations operating large portfolios of legacy monitoring tools with limited API support and proprietary data formats. AIOps platforms need access to data from across the technology stack, and when integration barriers prevent complete data ingestion, the platform operates with partial visibility that limits its analytical capabilities. A candid assessment published by Cribl in 2025 noted that IT leaders who adopted AIOps were sometimes disappointed when months-long integrations were hampered by poor data quality and data access challenges that delayed the expected return on investment. These integration challenges are not insurmountable, but they require realistic planning, phased implementation, and executive sponsorship that sustains investment through the initial integration period before benefits materialize.
Organizational resistance to AIOps adoption also presents a meaningful challenge, as operations teams may perceive automated diagnosis and remediation as a threat to their expertise and job security rather than an enhancement of their capabilities. Successful AIOps deployments address this concern directly by positioning the platform as a tool that amplifies human expertise rather than replacing it, freeing engineers from repetitive tasks so they can focus on creative, high-value work that automation cannot perform. Building this cultural alignment requires transparent communication about how AIOps will change workflows, what new skills teams will need to develop, and how the organization values the strategic contributions that become possible when routine operational burden is automated.
The Ethical Dimension of AI-Driven Operations
The deployment of AI in operational contexts raises ethical considerations that responsible organizations must address proactively, including transparency about how automated decisions are made, accountability when those decisions produce unintended consequences, and fairness in how AI-driven systems affect workforce roles and career development. AIOps platforms that make automated remediation decisions need clear governance frameworks defining when automation should act independently, when it should recommend actions for human approval, and what escalation procedures apply when automated actions produce unexpected results. Organizations committed to responsible AI practices that equip businesses for long-term success extend these principles to their AIOps deployments, ensuring that automation operates within boundaries that reflect organizational values and risk tolerance.
Transparency in AIOps decision making builds the organizational trust that sustained adoption requires, as engineers who understand why the platform recommended a specific action are more likely to follow that recommendation and provide the feedback that improves future accuracy. Explainable AI techniques that articulate the reasoning behind automated diagnoses and recommendations address the black-box concerns that can undermine confidence in AI-driven operations. Organizations leading in AIOps maturity treat explainability not as a technical feature but as an organizational commitment to maintaining human oversight over automated systems, ensuring that efficiency gains from automation never come at the cost of accountability for operational outcomes.
Where AIOps Is Heading Next
Looking beyond current challenges, the future of AIOps is being shaped by the convergence of generative AI, autonomous remediation, and agentic AI architectures that promise to extend automation from diagnosis into end-to-end incident management with minimal human intervention. Thoughtworks reported that across their 2025 AIOps engagements, the rise of agent-native AIOps platforms built around generative AI and orchestration frameworks demonstrated strong reasoning and automation capabilities, though three foundational components remained consistently missing: reliable agent frameworks for long-running operational workflows, context engineering layers providing enterprise-specific memory, and open observability layers for tracing and auditing agent behavior. These gaps define the engineering frontier for the next generation of AIOps platforms, where the technology will transition from cognitive augmentation to more autonomous operational agency.
The expansion of AIOps into adjacent domains beyond traditional IT operations represents another significant trajectory, as organizations apply the same intelligent monitoring and predictive analytics capabilities to contact center operations, supply chain management, and industrial IoT environments. These extensions broaden the organizational value of AIOps investments by applying operational intelligence to every domain where data-driven monitoring and automated response can improve outcomes. The organizations that will capture the most value from this expansion are those that have already established strong data governance, cross-functional collaboration, and cultural readiness for AI-augmented operations through their initial AIOps deployments. Cloud-based AIOps adoption already exceeds 62 percent of enterprise deployments, reflecting increasing demand for scalable and intelligent IT monitoring solutions across industries.
The SME segment represents an emerging growth frontier for AIOps, expanding at an 18.9 percent compound annual growth rate as cloud-based, usage-priced platforms with guided onboarding lower the technical and financial barriers that previously restricted AIOps to large enterprises with dedicated platform engineering teams. This democratization of AIOps capabilities means that smaller organizations can achieve enterprise-grade uptime and operational intelligence without the large IT teams and specialized expertise that early AIOps adoption required. As the technology matures and pricing models evolve, the benefits of AIOps will become accessible to a broader range of organizations, extending the operational advantages that large enterprises have cultivated to the midmarket and small business segments that drive the majority of economic activity.
Key Insights
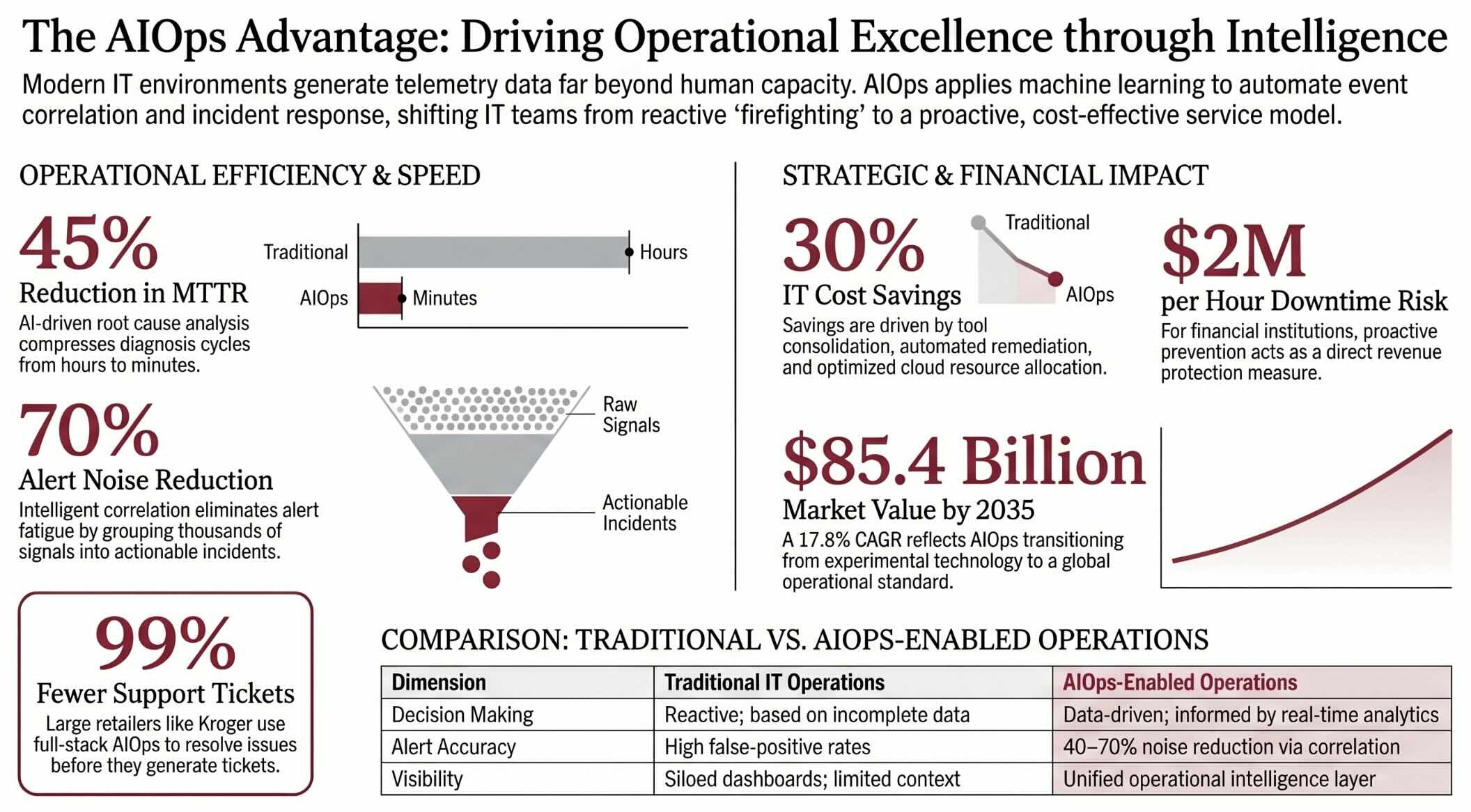
- The AIOps market reached an estimated USD 16.6 billion in 2025 and is projected to grow to USD 85.4 billion by 2035, reflecting a compound annual growth rate of 17.8 percent that signals mainstream enterprise adoption.
- Organizations implementing AIOps report MTTR reductions of up to 45 percent through automated event correlation and root cause analysis, translating downtime savings into measurable revenue protection.
- Across multiple Thoughtworks AIOps deployments in 2025, L1 and L2 ticket volumes dropped by 35 to 40 percent and root cause analysis cycles compressed from hours to minutes, freeing engineering capacity for strategic projects.
- Over 84 percent of organizations are currently using or planning to use AIOps to enhance IT operations, indicating that AIOps has crossed the adoption threshold from experimental technology to operational standard.
- Companies adopting AI-driven operations can achieve IT cost savings of up to 30 percent through improved automation, tool consolidation, and resource optimization, according to McKinsey research.
- Enterprise NOCs report alert noise reduction from 2,000 daily alerts to fewer than 200 meaningful incidents after AIOps deployment, eliminating the alert fatigue that drives operator burnout and missed critical events.
- The healthcare segment is experiencing a 16.66 percent CAGR in AIOps adoption through 2031, driven by strict audit trail requirements and patient safety imperatives that demand intelligent operational automation.
- Financial institutions invest heavily in AIOps because a single hour of downtime costs upwards of USD 2 million in lost transactions and compliance penalties, making proactive incident prevention a direct revenue protection measure.
These insights collectively demonstrate that AIOps has matured from an emerging technology concept into a proven operational discipline with measurable business outcomes. The convergence of market growth, enterprise adoption rates, and quantified operational improvements validates the strategic importance of nurturing AIOps capabilities as a long-term organizational investment. Organizations that delay AIOps adoption face growing operational risk as infrastructure complexity outpaces the capacity of traditional monitoring and manual processes to maintain service quality. The evidence points toward AIOps becoming as fundamental to IT operations as monitoring itself, transforming from an optional enhancement into a baseline requirement for competitive digital service delivery.
How AIOps Benefits Compare Across Key Operational Dimensions
| Dimension | Traditional IT Operations | AIOps-Enabled Operations |
|---|---|---|
| Transparency | Siloed dashboards with limited cross-domain visibility; teams operate independently with fragmented context | Unified operational intelligence layer providing full-stack visibility across applications, infrastructure, and security domains |
| Participation | Sequential escalation through rigid tiers; collaboration limited to war rooms during major incidents | Cross-functional, real-time collaboration enabled by enriched incident context shared through ChatOps and ITSM integrations |
| Trust | Engineers distrust alert systems due to high false positive rates; over-reliance on individual expertise and tribal knowledge | Dynamic baselines and validated correlations build confidence in automated insights; explainable AI reasoning supports human verification |
| Decision Making | Reactive decisions based on incomplete data and manual log analysis; delayed by dependency on senior engineers for diagnosis | Data-driven decisions informed by real-time analytics, historical pattern matching, and predictive models that surface actionable intelligence |
| Misinformation | False positives and redundant alerts obscure genuine incidents; operators waste time investigating non-issues | Intelligent correlation eliminates noise, reducing false positives by 40 to 70 percent and ensuring alerts represent verified, prioritized incidents |
| Service Delivery | Service quality degrades during incidents with extended MTTR; recovery depends on individual engineer availability and expertise | Consistent, automated incident response maintains service quality; MTTR reduced by up to 45 percent through machine-speed root cause analysis |
| Accountability | Incident ownership unclear across siloed teams; post-mortems rely on incomplete manual documentation | Automated audit trails capture every detection, correlation, diagnosis, and remediation action with full timestamp and context for governance review |
Real-World Examples
TD Bank’s AIOps-Driven IT Monitoring Transformation
TD Bank deployed the Dynatrace AIOps platform to unify its IT monitoring infrastructure, automating incident resolution and enhancing the digital experience for millions of banking customers across North America. The deployment produced a 25 percent increase in proactive issue detection, a 20 percent faster response rate, and a 60 percent reduction in IT-related customer complaints, demonstrating the direct link between operational intelligence and customer satisfaction in financial services. The platform’s ability to correlate application performance data with underlying infrastructure health enabled TD Bank to identify degradation patterns before they affected online banking availability. Critics note that financial services AIOps deployments face ongoing challenges around regulatory data sovereignty requirements that limit where telemetry data can be processed and stored, constraining the flexibility of cloud-based AIOps architectures.
Photobox’s 80 Percent MTTR Reduction Through Intelligent Observability
Photobox, a leading European e-commerce platform for personalized photo products, implemented Dynatrace AIOps to bring real-time observability and automated root cause analysis to its dynamic, containerized technology stack. The results were striking: an 80 percent reduction in mean time to resolution and a 60 percent decrease in critical incidents, outcomes that directly protected revenue during peak seasonal ordering periods when system availability is most critical to business performance. AIOps enabled Photobox’s engineering team to detect performance anomalies in individual microservices before they cascaded into customer-facing outages, shifting the team’s focus from reactive firefighting to proactive reliability engineering. A limitation of this approach is the significant dependency on comprehensive instrumentation coverage; any uninstrumented service or component creates a blind spot that the AIOps platform cannot monitor or correlate.
Kroger’s 99 Percent Support Ticket Reduction with Full-Stack AIOps
Kroger, one of the largest grocery retailers in the United States, deployed Dynatrace AIOps to bring AI-powered root cause detection and full-stack observability to its technology environment, which supports both in-store and digital customer experiences. The deployment achieved a remarkable 99 percent reduction in support tickets through automated anomaly detection and correlation that identified and resolved issues before they generated support requests from store operations or digital commerce teams. This dramatic reduction freed Kroger’s IT organization to accelerate innovation initiatives rather than consuming engineering capacity on reactive support workflows. The challenge for retail AIOps deployments of this scale lies in maintaining model accuracy across highly heterogeneous environments that combine legacy point-of-sale systems, modern cloud applications, and edge computing infrastructure with very different telemetry characteristics.
Case Studies
HCL Technologies Streamlines Cloud Operations with AIOps
HCL Technologies, a global IT services company managing infrastructure and applications for enterprise clients worldwide, faced growing challenges as cloud migration accelerated the volume and complexity of operational incidents across its client portfolio. The company deployed the Moogsoft AIOps platform to bring machine learning-driven incident correlation and automated triage to its managed services operations, replacing manual alert processing workflows that consumed significant engineering capacity. The results validated the investment: HCL Technologies reduced MTTR by 33 percent and cut service desk tickets by 62 percent through AI-driven incident automation that grouped related alerts, identified probable root causes, and routed enriched incidents to the appropriate resolution teams. Proactive monitoring capabilities enabled HCL to identify emerging issues in client environments before they triggered SLA breaches, improving uptime guarantees and strengthening client relationships.
Despite these gains, HCL’s experience highlighted the challenges of deploying AIOps across diverse client environments with varying data quality standards, monitoring tool ecosystems, and operational maturity levels. The platform’s effectiveness varied significantly between clients with well-instrumented, cloud-native architectures and those operating legacy environments with limited telemetry coverage and inconsistent log formatting. This variability underscores the importance of data readiness as a prerequisite for AIOps success, a lesson that HCL has incorporated into its client onboarding process by establishing minimum instrumentation and data quality standards before initiating AIOps platform deployment.
WPP Cuts Cloud Costs by 30 Percent with IBM AIOps and FinOps
WPP, the world’s largest advertising and communications company, struggled with rapidly escalating cloud costs as its global network of agencies expanded their use of cloud infrastructure without centralized visibility into resource utilization or spending patterns. WPP partnered with IBM to deploy an AIOps and FinOps solution combining IBM Apptio Cloudability for cloud cost visibility with IBM Turbonomic for automated resource optimization across the company’s sprawling multi-cloud estate. The deployment delivered a 30 percent reduction in cloud costs, saving USD 2 million in just three months, while IBM Apptio Cloudability provided 99 percent visibility into cloud usage and IBM Turbonomic automated over 1,000 monthly resizing actions that optimized resource efficiency without degrading application performance.
The WPP case illustrates how AIOps benefits extend beyond incident management into financial governance, where intelligent resource optimization directly impacts the bottom line. Critics observe that the FinOps dimension of AIOps is still maturing, and organizations should be cautious about assuming that cost optimization recommendations are universally applicable across different application architectures and workload profiles. Automated resizing that works well for stateless web services may produce unintended consequences when applied to stateful databases or memory-intensive analytics workloads, requiring ongoing human oversight of optimization actions even in mature AIOps deployments.
A Telecommunications Provider Transforms NOC Efficiency
A major telecommunications provider operating a network operations center that processed over 2,000 alerts daily deployed an AIOps platform to address chronic alert fatigue that was degrading operator performance and contributing to missed critical incidents. The platform applied machine learning-based event correlation to group related alerts, suppress duplicates, and prioritize incidents based on business impact rather than technical severity, reducing the daily alert volume to fewer than 200 meaningful incidents that operators could process effectively. This transformation allowed the NOC team to shift from constant reactive triage to proactive capacity planning and maintenance scheduling, improving both service quality and operator job satisfaction. The telecom industry’s integration of AIOps into 5G core networks is further reducing outage penalties and enabling the operational agility needed to manage next-generation network architectures.
The challenge for telecommunications AIOps deployments lies in the extreme heterogeneity of network environments, where legacy copper infrastructure, fiber-optic backhaul, wireless access points, and cloud-native core network functions all generate telemetry in different formats and at different frequencies. Achieving comprehensive event correlation across these diverse data sources requires significant investment in data normalization and integration engineering that extends the time-to-value for AIOps deployments. The telecommunications provider addressed this challenge through a phased implementation approach that prioritized the highest-volume, highest-impact data sources for initial AIOps integration, expanding coverage incrementally as data quality and integration maturity improved.
Frequently Asked Questions About AIOps Benefits
AIOps stands for Artificial Intelligence for IT Operations. It applies machine learning and analytics to automate monitoring, event correlation, anomaly detection, root cause analysis, and incident remediation across complex IT environments. The technology transforms reactive operations into proactive, data-driven management of digital infrastructure.
Initial benefits such as alert noise reduction and faster incident triage typically appear within weeks of deployment, as event correlation algorithms immediately begin grouping related alerts. Predictive analytics and advanced root cause analysis capabilities mature over three to six months as machine learning models accumulate sufficient historical data to establish accurate baselines and detect meaningful patterns.
AIOps augments human expertise rather than replacing it, automating repetitive tasks like alert triage, log analysis, and routine remediation while freeing engineers to focus on strategic work such as architecture design, reliability engineering, and innovation projects. The technology amplifies the impact of skilled professionals by handling the volume of operational work that exceeds human cognitive capacity.
AIOps platforms ingest metrics, logs, traces, events, and alerts from infrastructure, applications, network devices, and cloud services. The platform also benefits from topology data that maps dependencies between services and change management data that correlates incidents with recent deployments, configuration changes, or maintenance activities.
Traditional monitoring tools use static thresholds and manual rules to generate alerts, while AIOps uses machine learning to establish dynamic baselines that adapt to changing conditions. AIOps correlates events across multiple data sources automatically, identifies root causes through pattern recognition, and can trigger automated remediation, capabilities that traditional tools cannot replicate at scale.
Observability provides the raw data and instrumentation that AIOps platforms analyze, making the two disciplines complementary rather than competitive. AIOps adds intelligence and automation on top of observability data, transforming metrics, logs, and traces into actionable insights, predicted failures, and automated responses that observability alone cannot deliver.
Yes, the AIOps SME segment is expanding at an 18.9 percent CAGR as cloud-based, usage-priced platforms lower the financial and technical barriers to adoption. Small and midsize organizations can achieve enterprise-grade operational intelligence without large IT teams by selecting AIOps platforms designed for modular deployment and guided onboarding.
AIOps platforms automate the collection of compliance-relevant data, maintain auditable logs of all operational actions and incidents, generate automated reports for regulatory examinations, and provide continuous monitoring for configuration drift that could violate security policies. These capabilities reduce the manual burden of compliance while improving audit readiness.
The primary risks include poor data quality that produces unreliable insights, integration complexity with legacy monitoring tools, organizational resistance from teams that perceive automation as a threat, and unrealistic expectations about time-to-value. Addressing these risks requires phased implementation, executive sponsorship, data governance investment, and transparent communication about how AIOps will change workflows.
AIOps reduces costs through three primary mechanisms: consolidating redundant monitoring tools to reduce licensing expenses, automating routine tasks to redirect engineering labor toward higher-value activities, and optimizing cloud resource provisioning to eliminate waste from over-provisioned or idle infrastructure.
Machine learning is the analytical engine of AIOps, powering dynamic baselining, anomaly detection, event correlation, root cause analysis, and predictive analytics. Models continuously learn from operational data, improving their accuracy over time and adapting to changes in the environment without requiring manual threshold tuning or rule updates.
AIOps creates a shared intelligence layer that provides a unified view of system health across development, operations, security, and business teams. Enriched incidents containing full contextual information are shared through ChatOps integrations, enabling real-time cross-functional collaboration during incident response without the delays of sequential escalation.
Yes, AIOps delivers value in on-premises, hybrid, and fully cloud-native environments. Organizations operating traditional data center infrastructure benefit from the same noise reduction, root cause analysis, and predictive analytics capabilities, and AIOps can ease the transition to cloud and hybrid architectures by providing unified visibility across both environments.
Key evaluation criteria include breadth of data source integrations, quality of machine learning models for anomaly detection and correlation, automation and remediation capabilities, explainability of AI-driven insights, scalability to handle growing data volumes, and vendor ecosystem compatibility with existing monitoring, ITSM, and ChatOps tools.