Introduction
One-Hot Encoding (OHE) is a pivotal step in preparing categorical data for machine learning algorithms. Machine learning models predominantly require numerical input for effective learning and prediction. OHE offers a practical and efficient way to convert categorical data into a numerical form that algorithms can understand.
Real-world data often contains a mix of numerical and categorical variables. While numerical variables can be fed directly into algorithms, categorical variables need to be converted to a suitable numerical form. One-Hot Encoding is a widely used technique for this conversion, serving as a bridge between the data and the algorithm.
In machine learning and data science, preprocessing decisions are critical. Selecting the right encoding method for categorical variables can significantly impact a model’s performance. This makes understanding One-Hot Encoding essential for anyone involved in data science or machine learning.
Table Of Contents
- Introduction
- Definition Of One Hot Encoding
- Understanding One-Hot Encoding
- The Mechanics of One-Hot Encoding: A Step-by-Step Guide
- Simplification Of Categorical Data for Machine Learning Algorithms Using One Hot Encoding
- One-Hot Encoding vs. Label Encoding
- Real-World Applications Where One-Hot Encoding Is Used
- Understanding the Trade-offs of One-Hot Encoding
- Benefits Of One Hot Encoding
- Limitations of One Hot Encoding
- One-Hot Encoding in Various Programming Languages
- Tips for Efficient One-Hot Encoding
- Combining One-Hot Encoding with Other Preprocessing Methods
- The Future of One-Hot Encoding in Machine Learning
- References
Definition Of One Hot Encoding
One-Hot Encoding effectively transforms categorical data into a format that can be provided to machine learning algorithms as clear, numerical input. In this encoding scheme, each unique category within a feature is converted into a new categorical feature (or binary column), which is then filled with binary values of ‘1’ or ‘0’.
For example, let’s consider a dataset that includes a feature labeled “Color,” comprising three categories: Yellow, Purple, and Pink. Using One-Hot Encoding, this original “Color” feature would be replaced by three new binary columns: “Is_Yellow,” “Is_Purple,” and “Is_Pink.” Whenever a data point belongs to the category ‘Yellow,’ the “Is_Yellow” column would contain the value ‘1,’ while “Is_Purple” and “Is_Pink” would contain ‘0.’
As you navigate through each row of your dataset, you’ll assign values to these newly formed binary columns depending on the category for that specific data point. Continuing with our “Color” example, if a specific row had its original “Color” value marked as ‘Purple,’ then the “Is_Purple” column would contain ‘1,’ whereas “Is_Yellow” and “Is_Pink” would be set to ‘0.’
This collection of ‘1’ and ‘0’ across the newly created columns for each data point is commonly known as a one-hot vector. The dataset, once transformed, will have these one-hot vectors as its new features, replacing the original “Color” column.
One of the primary benefits of One-Hot Encoding is that it avoids the introduction of any arbitrary ordinal relationship among the categories. When encoding categories as numbers, as one might do with numerical labels like 1 for Yellow, 2 for Purple, and 3 for Pink, an unwanted ordinal relationship is introduced.
This could misleadingly suggest that the category ‘Pink’ is somehow “greater” than ‘Purple’ or ‘Yellow,’ which may not be an accurate representation for nominal categories like colors. One-Hot Encoding ensures that each category is treated independently, capturing the categorical nature of the feature without introducing any misleading ordinalities.
Also Read: What Are Word Embeddings?
Understanding One-Hot Encoding
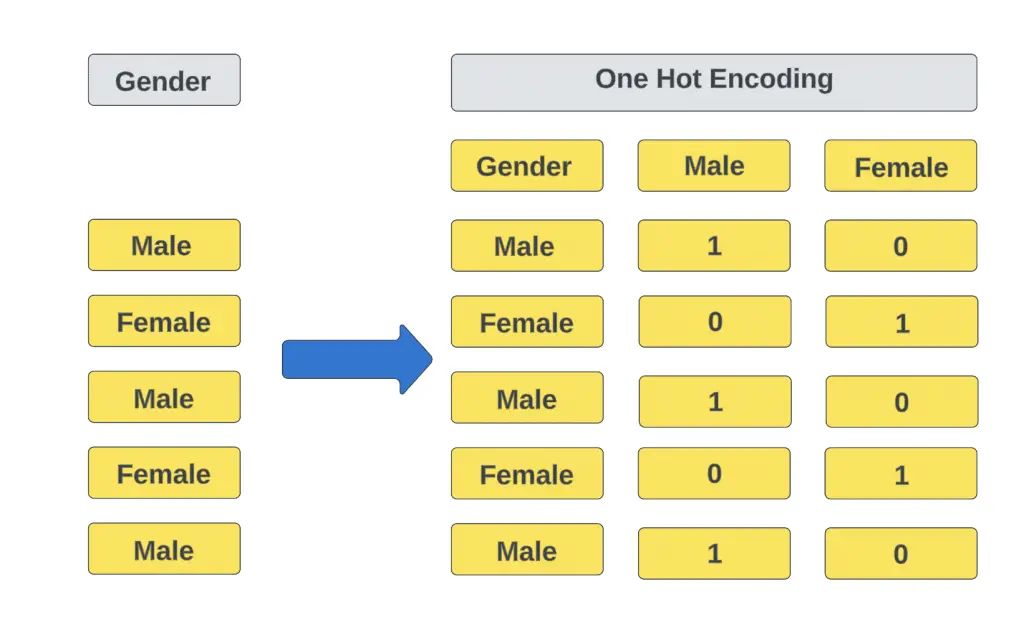
One-Hot Encoding can be easily understood through a simple example involving a dataset with a “Gender” column containing two categories: ‘Male’ and ‘Female.’ In a traditional dataset, you might see a column like you see on the left.
Using One-Hot Encoding, you would replace the single “Gender” column with two new binary columns: one called “Male” and another called “Female.”
For each row in the dataset, if the original “Gender” value was ‘Male,’ you would place a ‘1’ in the “Male” column and a ‘0’ in the “Female” column. Conversely, if the original value was ‘Female,’ you’d place a ‘0’ in “Male” and a ‘1’ in “Female.” The transformed dataset would look like the one on the right.
The Mechanics of One-Hot Encoding: A Step-by-Step Guide
To implement One-Hot Encoding, the first step involves identifying the categorical columns in the dataset, which are often referred to as categorical features. Once these features are isolated, enumerate all the unique categories within each feature to understand the extent of encoding needed. For every unique category within a categorical feature, a new binary column, also known as a dummy variable, is generated.
For each row in the dataset, examine the original categorical values and fill in the appropriate binary columns, also known as binary variables. These binary variables make up what is often termed as the one-hot vector.
For example, if a row in the ‘Color’ categorical feature is marked as ‘Red,’ you would place a ‘1’ in the corresponding ‘Is_Red’ binary column while marking ‘0’ in all other associated binary columns. These binary variables, once filled, signify the categorical integer features for each row.
After processing each row, the next step is to remove the original categorical columns from the dataset, retaining only the newly formed binary columns. These binary vectors then serve as the transformed representation of the original categorical features, making the dataset more suitable for machine learning algorithms.
This especially holds true for models where the output variable or target is highly sensitive to the input type and does not accommodate categorical form or ranking for category values, unlike methods like Ordinal Encoding which assign a ranking to each category.
Also Read: Multinomial Logistic Regression
Simplification Of Categorical Data for Machine Learning Algorithms Using One Hot Encoding
Machine learning algorithms perform optimally with numerical inputs, and One-Hot Encoding serves as a method to convert categorical data into such a machine-friendly format. Through the Encoding process, each original category within a feature is translated into a separate binary column, often referred to as dummy variables.
This variable encoding technique eliminates the potential for algorithms to misunderstand implicit orders or hierarchies in the data, a problem that can often result from methods like Integer or Ordinal Encoding. By doing so, One-Hot Encoding clarifies the relationships between features and target variables, thus enhancing the algorithm’s ability for pattern recognition.
In practical terms, each row of the dataset after applying One-Hot Encoding will contain a binary vector representing the original categorical features. The result of this encoding is a sparse matrix largely populated with zeros. While the matrix does introduce additional features, it does so without creating interdependent features, meaning each binary feature stands as an independent representation of the original category it was derived from.
This characteristic of the One-Hot Encoding results allows machine learning algorithms to process the data more efficiently, as they can quickly zero in on the meaningful patterns that are now represented as numerical features.
Despite its advantages, it’s worth noting that One-Hot Encoding can sometimes lead to poor performance due to the introduction of many additional features, especially in large datasets. This can add computational complexity and can sometimes make the model less interpretable.
For many algorithms, the ability to turn categorical data into numerical values that maintain independent features outweighs these potential drawbacks, making One-Hot Encoding a popular choice in a wide range of machine learning applications.
Also Read: How To Get Started With Machine Learning In Julia
One-Hot Encoding vs. Label Encoding
Both One-Hot Encoding and Label Encoding are popular techniques for converting categorical data variables into a format that machine learning algorithms can understand. Specifically, they transform these variables into numeric values suitable as input variables for different types of algorithms.
One-Hot Encoding operates by creating separate binary columns, often termed ‘dummy variables,’ for each of the distinct categories within an original column. On the other hand, Label Encoding is an integer encoding method that assigns a unique integer to each category within a feature.
Label Encoding is particularly useful for dealing with ordinal variables, where the categories have a natural order like “Low,” “Medium,” and “High.” In such cases, the integer representation captures the relationship between categories effectively.
For nominal data where no such ordinal relationship exists, Label Encoding could inadvertently introduce an ordinality that may skew the algorithm’s understanding and potentially lead to issues with predictions. This is where One-Hot Encoding proves advantageous; its representation technique treats each category as a distinct entity, without implying any ordinal relationship among categories.
While One-Hot Encoding offers a more nuanced approach for nominal data, it has its own challenges, particularly in increasing the dimensionality of the dataset. This can pose computational challenges and contribute to increased memory consumption, factors that can be detrimental in the context of algorithms sensitive to high-dimensional data, such as Support Vector Machines or certain deep learning models.
The explosion in dimensionality could affect the reliability of output values generated by these algorithms. However, despite these potential drawbacks, the one-hot scheme ensures that each category is treated as independent, making it a suitable choice for algorithms that require categories to be represented as single labels without any ordinal or integer association.
Also Read: Cross Entropy Loss and Uses in Machine Learning.
Real-World Applications Where One-Hot Encoding Is Used
In the e-commerce industry, recommendation systems play a pivotal role in providing users with personalized shopping experiences. One-Hot Encoding is frequently employed to handle various types of categorical data, such as product categories, vendor types, or customer reviews.
For example, product categories like “Electronics,” “Clothing,” and “Books” can be one-hot encoded into separate binary columns, allowing machine learning algorithms to accurately capture user preferences without any ambiguity. This numerical translation enables algorithms to make more targeted recommendations, thereby increasing the likelihood of user engagement and, consequently, sales.
In the healthcare sector, One-Hot Encoding is instrumental in making sense of diverse patient records that often contain a mix of numerical and categorical data. Factors like blood type, diagnosis codes, or even treatment types are typically categorical in nature. One-Hot Encoding these variables facilitates their incorporation into predictive models that focus on patient outcomes or personalized treatment plans.
This allows healthcare professionals to leverage machine learning for tasks ranging from predicting patient readmission rates to tailoring individualized treatment protocols, thereby improving the overall standard of care.
Within the financial sector, One-Hot Encoding proves invaluable in the development of risk assessment and fraud detection models. Data points like transaction types (e.g., credit, debit, transfer), customer segmentation labels (e.g., high-net-worth, retail, corporate), and loan statuses (e.g., approved, pending, defaulted) are commonly present in financial databases as categorical variables.
By converting these into a numerical format through One-Hot Encoding, machine learning models can better analyze these features for patterns that might indicate fraudulent activity or credit risk. This numeric translation enables more accurate decision-making, streamlining policy enforcement, and potentially saving institutions from significant financial loss.
Understanding the Trade-offs of One-Hot Encoding
One of the primary limitations of One-Hot Encoding is the potential for high dimensionality, especially when a feature has a large number of unique categories. The resulting binary matrix can become unwieldy, increasing both computational costs and memory usage.
This can be particularly problematic in machine learning projects where resources are limited or in models like Linear Regression and Logistic Regression, which are sensitive to multicollinearity. High dimensionality also poses the risk of overfitting, where the model learns the noise in the data rather than the underlying pattern. This challenge makes the selection of the right encoding technique crucial.
While there are other common methods like Count Encoding or Binary Encoding, each has its own set of challenges, including challenges with label encoding such as introducing unwanted ordinal relationships among label values.
Sparse matrices, where most of the elements are zero, can offer some relief in terms of storage requirements. However, the computational complexity associated with handling large sparse matrices remains a significant concern. Even though sparse matrix representations are more storage-efficient, they can still slow down machine learning algorithms, particularly in real-time processing applications.
This limitation prompts a careful consideration of the trade-offs involved in choosing One-Hot Encoding vs other types of encoding like Categorical or Binary Encoding, especially in projects where computational efficiency plays a crucial role.
Interpretability is another challenge that comes with the use of One-Hot Encoding. The sudden inflation in the number of features can make it difficult to understand the contribution of each feature to the model’s predictions. This can be particularly concerning when explaining the model’s behavior is important, as is often the case in regulated industries like healthcare and finance.
The Variance Inflation Factor, a measure often used to detect multicollinearity, can become harder to interpret with many features. Therefore, while One-Hot Encoding is a powerful technique for handling categorical variables, it necessitates a balanced consideration of its impact on both performance and interpretability.
Benefits Of One Hot Encoding
The primary benefit of One-Hot Encoding is its ability to convert categorical data into a format that machine learning algorithms can understand without introducing incorrect ordinal relationships. This often leads to more accurate models, as the algorithm interprets the data as intended.
For algorithms like linear regression, One-Hot Encoding can improve model performance. The transformed features allow for a clearer relationship between input and output, resulting in better predictions.
Ease of use is another strong point for One-Hot Encoding. The method is well-supported across various machine learning frameworks and programming languages. This makes it an accessible and versatile tool for data scientists and machine learning practitioners.
Limitations of One Hot Encoding
Dimensionality is a major concern in One-Hot Encoding. When dealing with features with many unique categories, the resulting binary matrix can grow significantly, leading to increased computational and memory requirements.
Multicollinearity is another issue, particularly in linear models. In such cases, the values of one binary column can often be inferred from the others, affecting the stability of some machine learning algorithms.
Maintaining One-Hot Encoding in a dynamic dataset can also be challenging. As new categories appear, the encoding and possibly the model will need to be updated, making it less suitable for datasets that are continually evolving.
One-Hot Encoding in Various Programming Languages
In Python, One-Hot Encoding is easily achievable thanks to widely used libraries like Pandas and scikit-learn. The Pandas library offers the ‘get_dummies’ function for straightforward one-hot encoding, converting a categorical feature into its binary representation. Similarly, the scikit-learn library provides a ‘OneHotEncoder’ class that can transform an array of integers into a sparse or dense matrix.
This extensive support simplifies the encoding process, offering Python users an efficient way to tackle the categorical variable issue in machine learning projects. For instance, you could use scikit-learn’s OneHotEncoder to convert a categorical feature like color into multiple binary features, each representing a unique color.
In the R programming language, functions like model.matrix() or dummyVars() in the caret package are often used for One-Hot Encoding. These functions allow users to create a design matrix, essentially facilitating the actual encoding of categorical variables into binary form.
Alternative encoding methods, including Ordinal and One-Hot Encodings, can also be applied based on the specific requirements of the machine learning model in use. This makes R a versatile platform for data scientists who wish to explore both binary and one-hot state encodings while examining feature interaction.
Other programming languages and environments also offer ways to perform One-Hot Encoding. Julia, MATLAB, and SQL, for example, provide their own native functions or packages to hot encode categorical variables. In MATLAB, the “dummyvar” function can be used for this purpose. SQL can implement One-Hot Encoding by using case statements to create binary columns.
The wide-ranging support for One-Hot Encoding across various programming languages makes it a universally accessible technique. Whether dealing with encoding by inspection, Encoding in Code, or encoding with Pandas and other libraries, data scientists have a plethora of options to fit their specific needs and preferred coding environments.
Tips for Efficient One-Hot Encoding
Efficiency in One-Hot Encoding is often linked to managing dimensionality. Techniques like feature engineering or bucketing less frequent categories can help reduce the number of binary columns generated.
Utilizing sparse matrix formats can be another way to maintain efficiency. Sparse matrices only store non-zero elements, conserving memory.
Being mindful of the machine learning algorithm in use is important. Some algorithms, like decision trees, handle high dimensionality better than others. In such cases, extensive dimensionality reduction may not be necessary.
Combining One-Hot Encoding with Other Preprocessing Methods
Normalization and scaling are common preprocessing steps that can be combined with One-Hot Encoding. In situations where a dataset contains both continuous and categorical variables, it is often effective to apply One-Hot Encoding first, followed by scaling of the numerical variables.
Imputation of missing values is another preprocessing method that can be used in conjunction. It is generally advisable to handle missing values before applying One-Hot Encoding to avoid generating binary columns for ‘missing’ categories.
Principal Component Analysis (PCA) is also sometimes used after One-Hot Encoding, particularly when dimensionality becomes an issue. However, it is crucial to understand that applying PCA changes the interpretability of individual features.
The Future of One-Hot Encoding in Machine Learning
Embeddings are gaining popularity as an alternative to One-Hot Encoding, particularly in deep learning. Embeddings offer a more compact representation of categorical variables, addressing some of the dimensionality issues associated with One-Hot Encoding.
Another emerging trend is the use of autoencoders to learn a compressed representation of categorical data. This can be particularly useful when handling high-dimensional data or when seeking a richer representation of categories.
With the advancement of automated machine learning (AutoML) tools, One-Hot Encoding may become a more automated step in the data preprocessing pipeline. However, as machine learning models become increasingly complex, understanding the fundamentals of techniques like One-Hot Encoding will remain important for effective model building and interpretation.

References
Deshpande, Anand, and Manish Kumar. Artificial Intelligence for Big Data: Complete Guide to Automating Big Data Solutions Using Artificial Intelligence Techniques. Packt Publishing Ltd, 2018.
Müller, Andreas C., and Sarah Guido. Introduction to Machine Learning with Python: A Guide for Data Scientists. “O’Reilly Media, Inc.,” 2016.
Subramanian, Vishnu. Deep Learning with PyTorch: A Practical Approach to Building Neural Network Models Using PyTorch. Packt Publishing Ltd, 2018.