
What is Julia?
Julia is a relatively new programming language that came out in 2018. It is a high level and high-performance language. High level means that it uses natural language elements, is easier to use, and is more understandable than a low-level language. The design philosophy behind this language was to make it have the speed of C and C++, while being easy to use like Python. Julia is a great language when looking to try and solve complex problems. Some fields that adopted the use of Julia early are Biology, Chemistry, and Machine Learning. Julia can also be used for other tasks such as game development and web development.
Table of contents
Why use Julia?
Why should we use Julia for machine learning when other languages like Python already exist? Well first the main advantage Julia has over other languages in the field is its speed. It has this speed advantage because it is compiled and has been designed for parallelism. Julia is a high-level language, so it does not have complex syntax like other languages such as Java. This makes it easy for python programmers to switch over to Julia. Finally, Julia is still relatively new, so it is still growing and getting new libraries added to it every day. Since it is open source, anyone can create a new library!
Getting started with Julia
Before starting with Julia, we need to first download an application that can run it. One such application is known as Jupyter notebook. Jupyter notebook is an open-source integrated development environment or IDE. An IDE is simply a software that helps computer programmers write and develop code easier. It will normally contain a source code editor, automation tools, and a debugger. Generally, they are much easier to use for people new to a language. Jupyter notebook can be downloaded on the official Project Jupyter website, https://jupyter.org/.
Next, you will need to download Julia from their official website, https://julialang.org/downloads/. After that is downloaded, to add Julia to Jupyter notebook you need to first open the Julia command line. Once that is open, you type in the command “using Pkg” and press enter. Afterwards type in the command “Pkg.add(“IJulia”) and press enter. This will take some time to install. Once it is done, you can then open the IDE Jupyter notebook, click on new to the top right of the screen and select Julia from there. Congratulations, you can now begin programming using Julia!
Preparing Data for Julia
Before we can start using Julia for Machine learning, we first must prepare a data set. For the following examples I will be using the Iris data set. It can be found at the website https://archive.ics.uci.edu/ml/datasets/iris. There are three different ways to import and prepare data. These ways are importing a CSV file, one hot coding a categorical variable, and making a train-test split. The methods are more in depth below.
- Importing a CSV file. A CSV file stands for comma separated file and is simply a file that allows data to be structured in a table format. To import a CSV file in Julia, you first need to add the libraries “DataFrames” and “CSV”. After this is done, then you simply use the built-in function “CSV.file” to read the CSV file and convert it into a data frame. The code below shows how to accomplish this.

- Hot coding a categorical variable. On some occasions you may need to use one hot encoding for categorical variables. With one-hot, we convert each categorical value into a new categorical column and assign a binary value of 1 or 0 to those columns. The library used for to do this is called “Lathe”. We use this library because it has the one hot code function prebuilt in already. Below is an example.

- Train test split. Train test splits are used to estimate the performance of a machine learning algorithm. It can also be used for model evaluation. The library used to do is called “Random”. This library is very large, to learn more about it visit the official website here https://docs.julialang.org/en/v1/stdlib/Random/. Below is an example of a test train split.

Machine learning using Julia
Now that all the data preparation has been completed, we can finally begin using Julia for machine learning. Since Julia is still a relatively new language, it does not have as many libraries as other languages like Python. This article will focus on the two biggest libraries in Julia, MLJ and Scikit Learn.
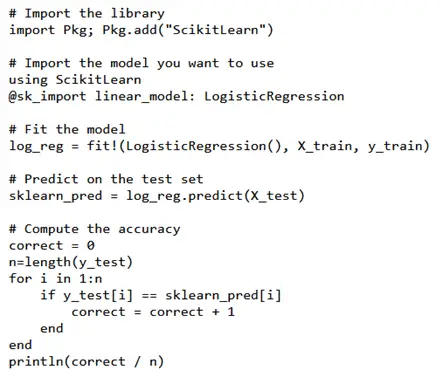
- Scikit Learn. If you are familiar with Python, you will recognize this library. It features many classifications, clustering algorithms, and regressions in Python and works similarly in Julia. Below is an example of using Scikit Learn for logistic regression. The “fit!” syntax is used to train the model.
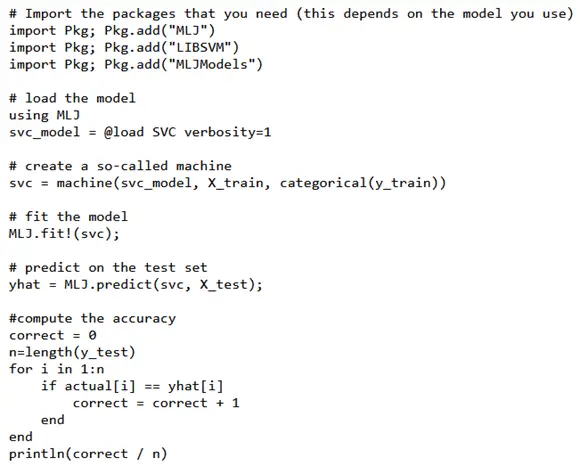
- MLJ stands for machine learning in Julia and provides algorithms for tuning, selecting, composing, evaluating, and comparing over 100 machine learning models. This library is unique to Julia and is supported by the Alan Turing Foundation. You can learn more about MLJ on the official website https://juliapackages.com/p/mlj. There are some differences when using MLJ. For example, you must load a model using the “using” command instead of importing packages like Python does. Below is an example of MLJ:
Conclusion
Julia is still developing as a language, but it can be easy to learn for those already familiar with Python. The library MLJ could make Julia become the leader in the machine learning world, overtaking Python. However, it still needs more trust and support from the community before it can accomplish that. I hope this article has taught you a little bit about where to start when trying to learn Julia. Thank you for reading.

References
Kilpatrick, Logan. “Learn Julia for Beginners – the Future Programming Language of Data Science and Machine Learning Explained.” FreeCodeCamp.org, FreeCodeCamp.org, 28 Dec. 2021, https://www.freecodecamp.org/news/learn-julia-programming-language/.
Tuychiev, Bekhruz. “The Rise of the Julia Programming Language - Is It Worth Learning in 2022?” DataCamp, DataCamp, 19 May 2022, https://www.datacamp.com/blog/the-rise-of-julia-is-it-worth-learning-in-2022.