
Introduction
Word embeddings are the invisible engine behind every modern AI system that processes human language, from search engines to chatbots to translation tools. The global text embedding models market reached $4.8 billion in 2025 and is projected to climb to $22.6 billion by 2034, reflecting how central this technology has become to the AI ecosystem. At their core, word embeddings convert human language into numeric vectors that machines can process, compare, and reason about. This transformation allows computers to capture the meaning behind words rather than treating them as arbitrary strings of characters. Every time you ask a virtual assistant a question or receive a product recommendation, word embeddings are doing the heavy lifting beneath the surface. The technique originated from neural network research in the early 2000s but accelerated dramatically after Google released Word2Vec in 2013. Understanding how word embedding works is essential for anyone building, evaluating, or managing AI-powered products in 2026 and beyond.
Quick Answers on Word Embeddings
What are word embeddings in AI?
Word embeddings are numerical vector representations of words that capture semantic meaning, allowing machines to understand relationships between words. They position similar words close together in a multidimensional vector space.
How are word embeddings created?
Word embeddings are created by training neural networks on large text corpora, learning patterns from how words appear near each other. Models like Word2Vec, GloVe, and BERT use different architectures to generate these vector representations.
Why are word embeddings important for machine learning?
Word embeddings give machine learning models the ability to process text as structured numeric data. They encode semantic similarity, syntactic relationships, and contextual nuances that raw text cannot provide to algorithms.
Key Takeaways
- The embedding landscape is shifting from static, context-free representations toward contextual and multimodal models that power large language models and retrieval-augmented generation systems.
- Word embeddings transform text into dense numerical vectors that capture meaning, enabling machines to perform tasks like sentiment analysis, translation, and search.
- Major word embedding models include Word2Vec, GloVe, FastText, ELMo, and BERT, each offering distinct advantages for different NLP applications.
- Bias embedded in training data propagates through word embeddings into downstream applications, making fairness auditing a critical step in any NLP pipeline.
Table of contents
- Introduction
- Quick Answers on Word Embeddings
- Key Takeaways
- Understanding Word Embeddings in AI
- Why Machines Need Numeric Representations of Language
- From One-Hot Encoding to Dense Vectors
- How Word Embeddings Are Created
- The Word Embedding Matrix Explained
- Types of Word Embeddings in Modern NLP
- Word2Vec: The Model That Changed NLP
- GloVe: Global Vectors for Word Representation
- FastText and Subword Embeddings
- Contextual Word Embeddings: ELMo and BERT
- How Word Embedding Models Are Trained
- The Role of Word Embeddings in Machine Learning Pipelines
- Applications Powered by Word Embeddings
- Bias and Ethics in Word Embedding Systems
- Limitations and Risks of Word Embeddings
- How to Build and Train Word Embeddings for Your Projects
- Word Embeddings in the Era of Large Language Models
- The Market and Industry Landscape for Embedding Technology
- Where Word Embeddings Are Heading Next
- Key Insights
- Comparing Word Embedding Approaches
- How Organizations Are Applying Word Embeddings Across Industries
- Lessons From Word Embedding Deployments in Practice
- Frequently Asked Questions About Word Embeddings
Understanding Word Embeddings in AI
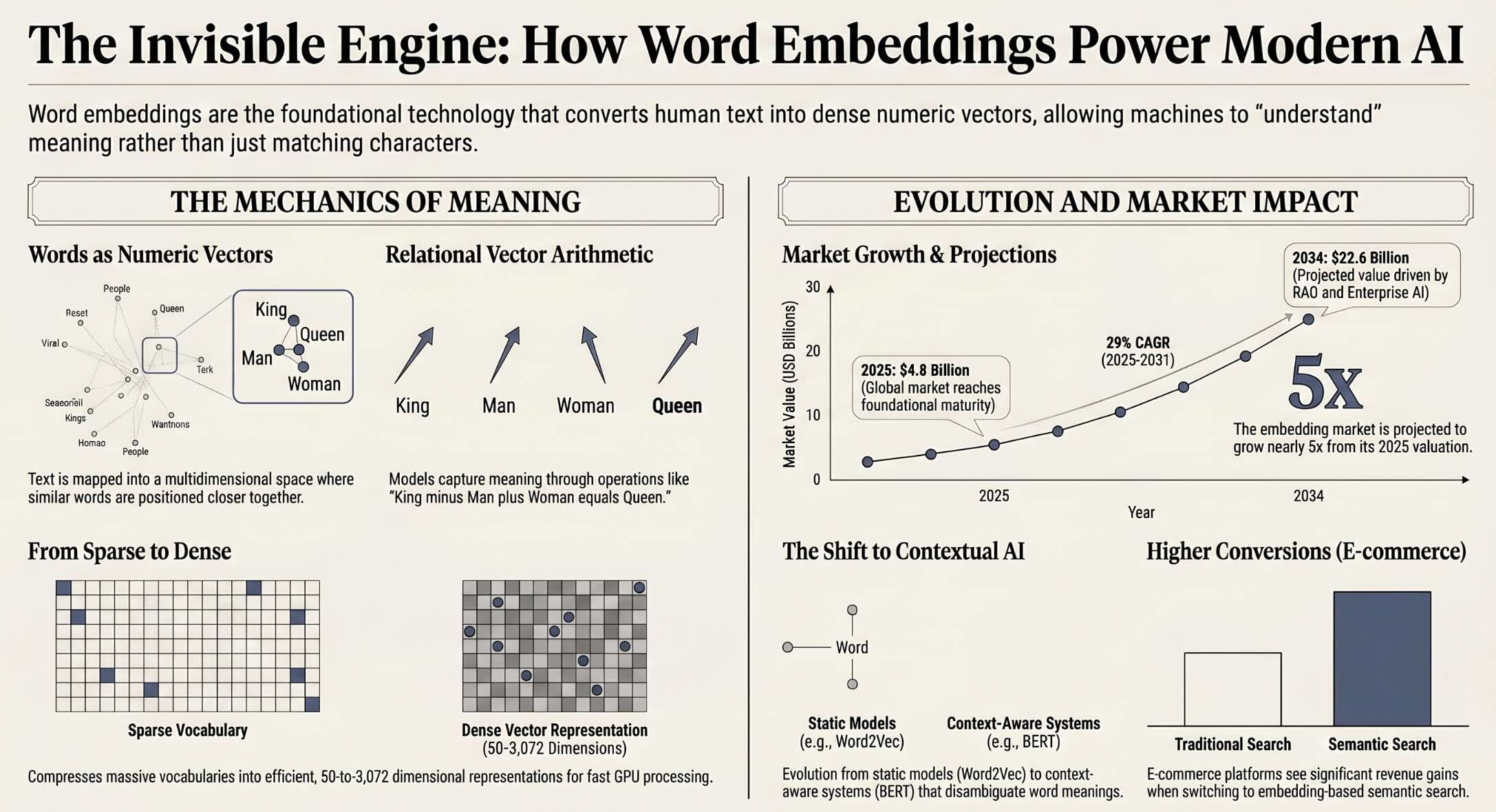
A word embedding is a learned representation that maps a word to a vector of real numbers in a continuous, lower-dimensional space. The word embedding definition is straightforward: it is a technique that converts text into numbers while preserving the relationships between words, so that words with similar meanings receive similar vector representations. These vectors typically range from 50 to 3,072 dimensions depending on the model, and they encode semantic and syntactic properties that allow mathematical operations on language. For example, the famous analogy “king minus man plus woman equals queen” demonstrates how word vector embeddings capture relational meaning in their numeric structure. The word embedding meaning extends beyond simple translation of text to numbers; it represents a fundamental shift in how machines interpret language. Word embeddings are the bridge between human communication and computational reasoning, making them foundational to every NLP system operating today.
The concept builds on the distributional hypothesis first proposed by linguist J.R. Firth in 1957, which states that words appearing in similar contexts tend to carry similar meanings. Modern embedding words techniques operationalize this insight by training algorithms on billions of text samples to learn which words co-occur frequently. Unlike older methods that treated each word as an independent symbol, word embeddings create a shared mathematical space where proximity corresponds to similarity. This approach allows models to generalize across vocabulary items they have never seen paired together during training. The result is a representation that supports downstream tasks from text classification to question answering with remarkable efficiency.
Word Embedding Model Comparison Tool
Explore how different word embedding models compare across key performance dimensions. Adjust parameters to see how model choice affects your NLP pipeline.
Why Machines Need Numeric Representations of Language
Computers operate on numbers, not on the abstract symbols that compose human language. Every machine learning algorithm requires structured numeric input, which means raw text must be converted into a format that mathematical operations can manipulate. Early approaches to this problem, such as bag-of-words models, simply counted how often each word appeared in a document and discarded all information about word order and meaning. These frequency-based methods produced sparse, high-dimensional vectors that treated every word as completely independent from every other word. The inability to capture semantic relationships between words severely limited what early NLP systems could accomplish. A bag-of-words model has no way of knowing that "happy" and "joyful" share a meaning, or that "bank" can refer to a financial institution or a riverbank depending on context. The gap between human language understanding and machine language processing remained vast until word embeddings arrived to close it.
The limitations of sparse representations become especially clear when you consider vocabulary size. A typical English corpus might contain 100,000 unique words, meaning each word would need a vector with 100,000 dimensions under one-hot encoding. Most of those dimensions would be zero for any given word, wasting computational resources and providing no useful information about relationships between words. Dense word embeddings solve this by compressing the representation down to 100 to 300 dimensions while retaining far more information about each word. This compression is not arbitrary; it is learned through exposure to massive amounts of text, where the model discovers which features of a word actually matter for predicting its context. The result is a representation that is both computationally efficient and semantically rich.
The practical implications of this shift are enormous for machine learning pipelines. When words are represented as dense vectors, algorithms can compute similarities between any pair of words using simple mathematical operations like cosine similarity. This enables applications such as semantic search, where a query about "automobile repair" can match documents discussing "car maintenance" even though the exact words differ. Clustering algorithms can group related concepts together, recommendation engines can find items described in similar language, and translation systems can align words across languages. Without word embeddings, each of these tasks would require extensive hand-crafted rules that could never scale to the full complexity of human language. The embedding approach replaces brittle rules with flexible, learned representations that improve as more data becomes available.
From One-Hot Encoding to Dense Vectors
One-hot encoding is the simplest method of representing words as numbers, and it illustrates exactly why better approaches were needed. In a one-hot scheme, each word in the vocabulary gets assigned a unique vector where one position is set to 1 and every other position is set to 0. For a vocabulary of 50,000 words, each word becomes a vector with 50,000 dimensions, most of which carry no information at all. This approach is easy to implement but completely ignores the meaning of words and the relationships between them. Two synonyms like "fast" and "quick" receive vectors that are just as different from each other as "fast" and "dinosaur" under one-hot encoding. The vectors are orthogonal, meaning their cosine similarity is zero regardless of whether the words share meaning. No machine learning model can extract semantic relationships from a representation that encodes none.
The term-frequency inverse-document-frequency (TF-IDF) method improved on raw word counts by weighting words based on how informative they are within a corpus. Words that appear frequently in a specific document but rarely across the full corpus receive higher weights, which helps distinguish important terms from common ones like "the" or "is." TF-IDF remains useful for certain applications such as document retrieval and keyword extraction, and it served as a standard NLP technique for decades before neural methods emerged. The approach still treats words as independent units, missing the rich web of relationships that humans understand intuitively. A TF-IDF vector cannot tell you that "doctor" and "physician" mean the same thing. It can only tell you how often each word appears relative to other documents in the collection.
Dense word embeddings represented a paradigm shift by learning fixed-length vectors where each dimension encodes a latent feature of the word. Instead of 50,000 sparse dimensions, a word might be represented by 300 dense dimensions, each carrying a fraction of the word's overall meaning. These vectors are trained using neural networks that learn to predict words from their surrounding context, or vice versa, across millions of sentences. The training process forces the model to position related words near each other in the embedding space because words that appear in similar contexts receive similar gradient updates. For instance, "cat" and "dog" both appear near words like "pet," "food," "walk," and "veterinarian," so their learned vectors end up close together. This emergent structure enables the kind of semantic reasoning that one-hot and TF-IDF representations cannot support.
The transition from sparse to dense representations also brought significant computational advantages that accelerated NLP research. Dense vectors consume far less memory and allow faster matrix operations on modern hardware, especially GPUs designed for parallel numerical computation. Training a model with 300-dimensional embeddings is orders of magnitude faster than working with 50,000-dimensional sparse vectors, and the resulting representations transfer well across tasks. A set of word embeddings trained on a general corpus can serve as the starting point for sentiment analysis, named entity recognition, or machine translation with minimal additional training. This property, known as transfer learning, made dense embeddings one of the most impactful innovations in the history of NLP. Pre-trained embeddings democratized access to powerful language representations, allowing researchers with limited data to build effective models.
How Word Embeddings Are Created
The process of creating word embeddings begins with assembling a large text corpus that serves as the training data for the embedding model. This corpus might consist of Wikipedia articles, news archives, web crawl data, or domain-specific documents depending on the intended application. The size and quality of this corpus directly determine the quality of the resulting embeddings, because the model can only learn relationships that are present in the data it sees. Corpora used for popular pre-trained embeddings typically contain billions of words spanning diverse topics and writing styles. The principle driving all word embedding creation is the distributional hypothesis: words that appear in similar contexts share similar meanings. Training algorithms exploit this principle by analyzing co-occurrence patterns at scale, extracting statistical regularities that correspond to semantic and syntactic features. The resulting word embedding matrix contains one row per word in the vocabulary, with each row representing that word's learned vector.
The two dominant approaches to creating word embeddings are prediction-based methods and count-based methods. Prediction-based methods, exemplified by Word2Vec, use shallow neural networks to predict either a target word from its context (Continuous Bag of Words, or CBOW) or context words from a target word (Skip-gram). The network's internal weights, after training, become the word embedding matrix that maps each word to its vector representation. Count-based methods, exemplified by GloVe, first build a global co-occurrence matrix that records how frequently each pair of words appears near each other across the entire corpus. The algorithm then factorizes this matrix to produce dense vectors that capture the statistical relationships encoded in the co-occurrence counts. Both approaches produce high-quality embeddings, but they differ in how they balance local context and global statistics.
Training an embedding model involves iterating through the corpus millions of times, adjusting the model's parameters to minimize a loss function that measures prediction error. For Word2Vec's Skip-gram model, the loss function penalizes the model when it fails to predict the correct context words given a center word. The optimization process uses stochastic gradient descent, updating the embedding vectors incrementally with each training example. Techniques like negative sampling dramatically speed up training by approximating the full computation with a smaller set of randomly selected negative examples. The learning rate, embedding dimensionality, context window size, and minimum word frequency are hyperparameters that practitioners must tune for their specific corpus and application. Typical training times range from hours to days depending on corpus size and hardware, with GPU acceleration reducing these times substantially.
The Word Embedding Matrix Explained
The word embedding matrix is the central data structure that stores the learned vector representations for every word in the vocabulary. This matrix has dimensions of V by D, where V is the vocabulary size and D is the embedding dimensionality chosen during training. Each row of the matrix corresponds to a specific word, and each column represents one dimension of the learned representation. When a model needs to look up the embedding for a particular word, it retrieves the corresponding row from this matrix using the word's index. The word embedding matrix is essentially a lookup table that transforms discrete word tokens into continuous vectors, enabling mathematical operations on language. In practice, this matrix is initialized with random values before training begins and gradually refined as the model processes the training corpus. After training, the matrix encodes the semantic and syntactic relationships discovered across billions of word co-occurrences.
Using the word embedding matrix in downstream applications involves an embedding layer that converts input tokens into their vector representations before passing them to the rest of the model. In deep learning frameworks like TensorFlow and PyTorch, this layer is implemented as a simple matrix multiplication that is differentiable, allowing gradients to flow back through the embedding during fine-tuning. Practitioners can initialize this layer with pre-trained embeddings from Word2Vec, GloVe, or FastText and then either freeze the weights to preserve the general knowledge or allow them to update during task-specific training. The choice between freezing and fine-tuning depends on the size of the task-specific dataset: smaller datasets benefit from frozen pre-trained embeddings that prevent overfitting, while larger datasets can support fine-tuning that adapts the representations to the target domain. The embedding matrix typically accounts for a significant portion of a model's total parameters, especially for large vocabularies.
Types of Word Embeddings in Modern NLP
The landscape of word embedding models has evolved through several distinct generations, each addressing limitations of its predecessors. The first generation includes frequency-based methods like TF-IDF and co-occurrence matrices that capture word importance and basic statistical relationships without learning dense representations. The second generation introduced neural word embedding models like Word2Vec, GloVe, and FastText that learn dense, fixed vectors for each word in the vocabulary. These static embeddings assign a single vector to each word regardless of context, which means a polysemous word like "bank" gets the same representation whether it refers to a financial institution or a riverbank. The third generation brought contextual embeddings through models like ELMo and BERT, which generate different vectors for the same word depending on the sentence in which it appears. The fourth and most recent generation extends embeddings beyond text to include images, audio, and video in unified multimodal vector spaces.
Each type of word embedding carries distinct tradeoffs in terms of training cost, storage requirements, and downstream task performance. Static embeddings from Word2Vec or GloVe are lightweight, fast to query, and work well for many traditional NLP tasks where context sensitivity is less critical. Pre-trained versions of these models are freely available and can be loaded in seconds, making them accessible to teams without large compute budgets. Contextual embeddings from BERT or its variants capture nuanced meanings but require significantly more computation and memory, as they process entire sentences rather than individual words. The choice between embedding types depends on the specific application, the available computational resources, and the importance of capturing context-dependent word meanings. Many production systems in 2026 use a combination of approaches, employing lightweight static embeddings for initial retrieval and contextual embeddings for re-ranking or fine-grained understanding.
The distinction between types of word embeddings also maps to how they handle vocabulary coverage and out-of-vocabulary words. Word2Vec and GloVe cannot produce vectors for words they did not encounter during training, which creates gaps when processing novel terms, typos, or domain-specific jargon. FastText addressed this by decomposing words into character n-grams and constructing word vectors from the sum of their subword components. This means FastText can generate reasonable embeddings for words it has never seen by assembling them from familiar character sequences. Contextual models like BERT use subword tokenization schemes such as WordPiece that break all words into known subword units, effectively eliminating the out-of-vocabulary problem entirely. The evolution from fixed-vocabulary static models to flexible subword-based contextual models represents one of the most significant advances in NLP technology.
Word2Vec: The Model That Changed NLP
Word2Vec, introduced by Tomas Mikolov and colleagues at Google in 2013, marked a turning point in how researchers approached language representation. The model demonstrated that a shallow neural network trained on a simple prediction task could produce word embeddings that captured rich semantic relationships, including analogies like "king minus man plus woman equals queen." Word2Vec proved that meaningful word vector representations did not require deep architectures or complex training procedures. The model operates through two complementary architectures: Continuous Bag of Words (CBOW) and Skip-gram. CBOW predicts a target word from its surrounding context words, while Skip-gram does the reverse, predicting context words from a given target word. Skip-gram tends to perform better on smaller datasets and rare words, while CBOW is faster to train and works well with frequent words. The simplicity and effectiveness of Word2Vec made it the default word embedding model for years and inspired a wave of research into distributed word representations.
The training efficiency of Word2Vec comes from several technical innovations that made large-scale embedding training practical. Negative sampling replaced the computationally expensive softmax output layer with a much cheaper approximation that samples a small number of "negative" words for each training example. Subsampling of frequent words reduced the dominance of common terms like "the" and "of" that carry little semantic information but appear in nearly every context. These optimizations allowed Word2Vec to train on billions of words in a matter of hours on a single machine, a feat that was impossible with previous neural language models. The resulting embeddings captured not just word similarity but also structured relationships that could be explored through vector arithmetic. Researchers quickly discovered that Word2Vec embeddings organized words into meaningful clusters corresponding to topics, grammatical categories, and even geographic or temporal relationships.
Word2Vec's impact extended far beyond academic research into practical applications across industries. Search engines used Word2Vec embeddings to improve query understanding and document matching, connecting searches to relevant results even when exact keyword matches were absent. Recommendation systems employed word embeddings to model user preferences and item descriptions in a shared vector space, enabling more nuanced content discovery. The word embedding model became a standard preprocessing step in virtually every NLP pipeline, from sentiment analysis to chatbot development. Pre-trained Word2Vec models trained on Google News (containing about 100 billion words) became one of the most downloaded resources in machine learning history. Even as newer models have surpassed Word2Vec on benchmark tasks, its conceptual framework and vocabulary continue to influence how practitioners think about and work with word representations.
GloVe: Global Vectors for Word Representation
GloVe, developed at Stanford University by Jeffrey Pennington, Richard Socher, and Christopher Manning in 2014, took a fundamentally different approach to creating word embeddings. While Word2Vec learns embeddings through local context window predictions, GloVe constructs a global word co-occurrence matrix and then learns vectors that encode the ratios of co-occurrence probabilities. This design philosophy reflects the insight that meaning is captured not just by which words appear together, but by how the probability of a word appearing near one context word compares to its probability of appearing near another. GloVe's strength lies in combining the advantages of global matrix factorization methods with the efficiency and quality of local context window methods. The model produces embeddings that perform competitively with or better than Word2Vec on word analogy tasks while providing a more transparent mathematical framework. Pre-trained GloVe vectors trained on Common Crawl (840 billion tokens) remain one of the most widely used embedding resources in the NLP community.
The co-occurrence matrix at GloVe's core records how frequently each pair of words appears within a specified context window across the entire training corpus. This matrix captures global statistical information that local prediction-based methods process only implicitly through repeated iterations over the data. GloVe's training objective minimizes the difference between the dot product of two word vectors and the logarithm of their co-occurrence count, weighted to reduce the influence of very frequent and very rare co-occurrences. The optimization is computationally efficient because it operates on the non-zero entries of the co-occurrence matrix rather than scanning through every word in the corpus. GloVe tends to excel at capturing both semantic similarity (words with related meanings) and syntactic patterns (words that play similar grammatical roles), making it versatile across a range of NLP tasks. The model's mathematical elegance and strong performance have kept it relevant even as contextual embedding models have risen to prominence.
FastText and Subword Embeddings
FastText, released by Facebook's AI Research lab in 2016, addressed one of the most persistent limitations of Word2Vec and GloVe: their inability to handle words not present in the training vocabulary. The core innovation of FastText is representing each word as a bag of character n-grams rather than as an atomic unit. For example, the word "embedding" with n-grams of length 3 to 6 would be decomposed into fragments like "emb," "mbe," "bed," "embe," "mbed," and so on. The word's final vector is computed as the sum of the vectors for all its constituent n-grams, which means the model can generate embeddings for any word by assembling it from known character sequences. This subword approach makes FastText especially valuable for morphologically rich languages and for applications that encounter frequent misspellings, slang, or neologisms. Social media analysis, customer review processing, and medical text mining all benefit from FastText's robustness to vocabulary variations.
The architecture of FastText extends Word2Vec's Skip-gram model by augmenting the word representation with character n-gram information during training. Each training example updates not just the target word's vector but also the vectors of all its constituent n-grams, distributing the learned information across subword components. This design means that rare words with common morphological roots still receive high-quality embeddings because their n-grams appear in many other words. For instance, the rare medical term "cardiomyopathy" shares n-grams with "cardio," "myopathy," "cardiac," and other related terms that appear more frequently. The model automatically learns that these shared fragments carry shared meaning, producing a reasonable embedding for even very infrequent terms. FastText also supports supervised text classification, making it a versatile tool that goes beyond pure embedding generation.
FastText's practical advantages have made it a popular choice for production NLP systems, especially in multilingual and low-resource settings. Facebook released pre-trained FastText embeddings for 157 languages, providing a crucial resource for researchers and developers working with languages that lack large annotated datasets. The subword approach naturally handles the agglutinative structures of languages like Turkish, Finnish, and Korean, where a single word can contain multiple morphemes that modify its meaning. FastText models are also fast to train and lightweight to deploy, running efficiently on CPU hardware without requiring expensive GPU clusters. These characteristics make FastText the embedding of choice for mobile and edge computing applications where computational resources are constrained. The combination of vocabulary flexibility, multilingual support, and deployment efficiency ensures that FastText remains relevant alongside more powerful but more expensive contextual models.
Contextual Word Embeddings: ELMo and BERT
The transition from static to contextual word embeddings represents the single largest leap in embedding quality since Word2Vec's introduction. Static models like Word2Vec and GloVe assign one fixed vector per word, which means "bank" receives the same representation in "I went to the bank to deposit money" and "I sat on the bank of the river." ELMo (Embeddings from Language Models), introduced by researchers at the Allen Institute for AI in 2018, solved this by generating word representations that depend on the entire sentence. ELMo uses a deep bidirectional LSTM language model trained on a large corpus, and it produces embeddings by combining the hidden states from all layers of this model. The resulting word vectors change based on context, capturing polysemy and nuanced meaning variations that static embeddings miss entirely. ELMo demonstrated that contextual representations could dramatically improve performance on a wide range of NLP benchmarks, pushing the field toward context-aware language understanding.
BERT (Bidirectional Encoder Representations from Transformers), released by Google in 2018, took contextual embeddings to another level by leveraging the transformer architecture instead of LSTMs. Unlike ELMo, which processes text left-to-right and right-to-left in separate passes, BERT reads the entire sequence simultaneously through self-attention mechanisms that weigh the relevance of every word to every other word. BERT is pre-trained using two objectives: masked language modeling (predicting randomly hidden words) and next sentence prediction (determining whether two sentences follow each other logically). This bidirectional training produces deep contextual representations that encode rich semantic and syntactic information. BERT's pre-trained model can be fine-tuned on specific downstream tasks with minimal additional data, achieving state-of-the-art results on question answering, named entity recognition, text classification, and many other benchmarks. The model fundamentally changed how word embedding in deep learning is approached by making contextualization the default expectation.
The impact of BERT on the NLP landscape has been transformative, spawning an entire family of transformer-based models. RoBERTa optimized BERT's training procedure by using more data and longer training times. DistilBERT compressed the model for faster inference while retaining most of its performance. ALBERT reduced parameter counts through factorization techniques, and DeBERTa introduced disentangled attention mechanisms. Each variant addresses a specific tradeoff between model size, training cost, inference speed, and task performance. In production systems, the choice of which contextual model to use depends on latency requirements, hardware budget, and the complexity of the language understanding task at hand. The embeddings produced by these models power the semantic search, retrieval-augmented generation, and conversational AI systems that define the current state of the art in NLP.
The relationship between static and contextual embeddings is complementary rather than competitive in many real-world deployments. Static embeddings remain valuable for tasks that process individual words or short phrases at high volume, such as autocomplete suggestions, spelling correction, and basic keyword matching. Contextual embeddings excel at tasks requiring sentence-level or paragraph-level understanding, such as reading comprehension, document summarization, and complex question answering. Many production architectures use static embeddings for a fast initial retrieval stage and then apply contextual embeddings to re-rank or refine the results. This hybrid approach balances computational cost with representation quality, delivering the benefits of both embedding families. Understanding when each type of embedding is appropriate remains one of the most important practical skills in modern NLP engineering.
How Word Embedding Models Are Trained
Training a word embedding model requires three essential components: a large text corpus, a model architecture, and an optimization algorithm. The corpus provides the raw language data from which statistical patterns are extracted, and its quality determines the ceiling on how good the resulting embeddings can be. Corpora commonly used for training include Wikipedia, Common Crawl (a dataset containing petabytes of web text), and domain-specific collections like PubMed for biomedical applications. The model architecture defines the mathematical relationship between input words and output predictions, whether that is a shallow network like Word2Vec or a deep transformer like BERT. The optimization algorithm, typically some variant of stochastic gradient descent, adjusts the model's parameters incrementally to minimize the difference between predicted and actual word co-occurrences. The interplay between these three components, corpus quality, architecture choice, and optimization strategy, determines the final quality and characteristics of the learned embeddings.
The context window is a critical hyperparameter that controls how many words on either side of a target word the model considers during training. A narrow window of 2 to 5 words tends to produce embeddings that capture functional and syntactic similarity, grouping words that play similar grammatical roles. A wider window of 5 to 15 words tends to produce embeddings that capture topical and semantic similarity, grouping words that discuss related subjects. The embedding dimensionality is another key choice: smaller dimensions (50 to 100) are faster to train and deploy but may lose fine-grained distinctions, while larger dimensions (200 to 300) capture more information at the cost of increased memory and computation. Practitioners typically experiment with multiple hyperparameter configurations and evaluate the resulting embeddings on intrinsic benchmarks (word analogy tasks, similarity judgments) and extrinsic benchmarks (performance on the target downstream task). The optimal settings depend heavily on the specific application and dataset.
Modern embedding training has evolved to incorporate techniques that improve both quality and efficiency at scale. Subword tokenization methods like Byte Pair Encoding (BPE) and WordPiece break words into smaller units, allowing models to handle any input text without an explicit vocabulary limit. Mixed-precision training uses lower-precision floating-point numbers to reduce memory consumption and accelerate computation on GPU hardware. Distributed training across multiple GPUs or even multiple machines enables processing of corpora containing hundreds of billions of tokens. Knowledge distillation techniques compress large embedding models into smaller ones that retain most of the original model's quality while running faster at inference time. These advances collectively mean that high-quality word embeddings are more accessible than ever, with open-source tools and models available for virtually any language and domain.
The Role of Word Embeddings in Machine Learning Pipelines
Word embeddings serve as the input layer for virtually every machine learning model that processes text data, converting raw language into the structured numeric format that algorithms require. In a typical NLP pipeline, raw text is first tokenized into individual words or subword units, and then each token is mapped to its corresponding embedding vector using the word embedding matrix. These vectors are then fed into downstream models such as convolutional neural networks (CNNs), recurrent neural networks (RNNs), or transformers that perform the specific task at hand. The quality of the input embeddings directly affects the performance of these downstream models, which is why so much research effort has focused on improving embedding techniques. Pre-trained word embeddings provide a powerful initialization that encodes general language knowledge, allowing task-specific models to converge faster and generalize better even with limited labeled data. The embedding layer effectively compresses the vast complexity of human language into a fixed-dimensional representation that is compatible with standard machine learning optimization methods.
The versatility of word embeddings in machine learning extends across supervised, unsupervised, and semi-supervised learning paradigms. In supervised learning, embeddings serve as input features for classifiers that predict labels like sentiment, topic, or intent. In unsupervised learning, embeddings enable clustering of documents, discovery of latent topics, and visualization of vocabulary structure through dimensionality reduction techniques like t-SNE or UMAP. In semi-supervised and self-supervised settings, embeddings pre-trained on unlabeled data provide the foundation for fine-tuning on smaller labeled datasets. This flexibility makes word embeddings the most widely adopted text representation across all branches of machine learning. The recent explosion of retrieval-augmented generation (RAG) systems has created yet another critical role for embeddings: encoding documents and queries in a shared vector space that enables semantic search over knowledge bases. Over 65% of Fortune 1000 companies have initiated internal knowledge base modernization projects incorporating semantic search powered by embeddings, reflecting the technology's central role in enterprise AI strategy.
Applications Powered by Word Embeddings
Search engines represent one of the most impactful applications of word embeddings in daily life. Traditional keyword-based search required exact matches between query terms and document content, which failed whenever users and authors chose different words to express the same concept. Embedding-powered semantic search projects both queries and documents into the same vector space, allowing retrieval based on meaning rather than surface-level word matching. E-commerce platforms using embedding-based semantic product discovery have reported conversion rate improvements of 18 to 32 percent compared to traditional search approaches. The vector database ecosystem supporting this capability, including tools like Pinecone, Weaviate, Qdrant, Milvus, and Chroma, collectively raised over $450 million in venture capital in 2024 and 2025. Word embeddings power the shift from "search for what you type" to "search for what you mean," a transformation that is reshaping how users interact with information across every industry.
Machine translation is another domain where word embeddings have driven remarkable progress. Early translation systems relied on phrase tables and hand-crafted rules that could not scale to the full complexity of natural language. Modern neural machine translation systems use word embeddings as the foundation for encoder-decoder architectures that translate entire sentences while preserving meaning, tone, and grammatical structure. Cross-lingual embeddings, which map words from different languages into a shared vector space, enable zero-shot translation between language pairs that the model has never seen during training. This capability is especially valuable for low-resource languages that lack the large parallel corpora traditionally required for training translation systems. The ability of embeddings to bridge linguistic gaps extends to multilingual search, content moderation, and global customer support systems that operate across dozens of languages simultaneously.
Sentiment analysis, recommendation engines, and healthcare NLP represent three additional application areas where word embeddings are indispensable. Sentiment analysis systems use word embeddings to classify text as positive, negative, or neutral, powering brand monitoring, product review analysis, and social media listening tools used by marketing teams worldwide. Recommendation systems embed both user preferences and item descriptions in a shared vector space, enabling content discovery that goes beyond simple collaborative filtering. In healthcare, clinical NLP systems use word embeddings trained on medical literature to extract diagnoses, medications, and treatment outcomes from unstructured clinical notes, accelerating research and improving patient care. Each of these applications depends on the ability of word embeddings to capture the semantic nuances that distinguish useful information from noise. The breadth of these applications explains why word embeddings have become a fundamental infrastructure component for AI-driven organizations.
Bias and Ethics in Word Embedding Systems
Word embeddings learn their representations from human-generated text, which means they inevitably absorb and encode the biases present in that text. Research has consistently demonstrated that popular word embedding models associate male terms more strongly with science and career concepts while associating female terms more strongly with family and arts concepts. These associations are not design choices; they emerge automatically from the statistical patterns in training data drawn from sources like news articles, books, and web pages. The problem becomes critical when biased embeddings are deployed in downstream applications such as hiring platforms, loan approval systems, and criminal justice tools. A recruitment system built on biased word embeddings might rank male candidates higher for technical roles and female candidates higher for administrative roles, directly perpetuating workplace discrimination. Biased embeddings in search engines can influence which content users see, shaping public opinion in ways that reinforce existing stereotypes rather than challenging them. The ethical stakes are high enough that bias auditing has become a required step in responsible AI development.
The mechanisms through which bias enters word embeddings operate at multiple levels. Training data bias occurs when the corpus over-represents certain perspectives, demographics, or time periods, encoding those skews into the learned vectors. Cultural and historical context means that corpora drawn from older texts may reflect outdated attitudes about race, gender, disability, and other social categories. Model architecture and training procedures can amplify existing biases by over-weighting frequent patterns, which tend to reflect dominant cultural narratives. The interaction between these factors creates a compounding effect where small biases in the data become larger biases in the model, which become even larger biases in the application. Researchers at institutions like the Allen Institute, Stanford, and MIT have catalogued extensive examples of harmful associations in publicly available word embeddings, including supposedly "debiased" models. The challenge of eliminating bias from word embeddings is not purely technical; it requires engagement with social science, ethics, and the communities affected by biased AI systems.
Several debiasing strategies have been developed to mitigate bias in word embeddings, though none provides a complete solution. Pre-processing methods modify the training data before embedding creation by balancing representation across demographic groups or removing explicitly biased text. In-processing methods modify the training algorithm itself to constrain the embedding space and prevent the formation of biased associations during learning. Post-processing methods, such as the hard debiasing technique proposed by Bolukbasi et al., identify the direction in the embedding space that corresponds to a bias dimension (such as gender) and project word vectors to remove that component. Each approach reduces measurable bias on standard benchmarks but may fail to address subtler or intersectional biases that are harder to define and measure. The ongoing tension between bias reduction and representation quality reflects a deeper truth: word embeddings mirror the language they learn from, and language itself is shaped by the inequities of the societies that produce it.
Organizations deploying word embedding systems bear a responsibility to monitor for biased outcomes and mitigate them proactively. This means going beyond technical debiasing to establish governance frameworks that include diverse teams, regular bias audits, and clear accountability for AI fairness outcomes. Industry standards are emerging that require documentation of training data sources, known limitations, and bias mitigation steps taken during embedding development. The Word Embedding Association Test (WEAT) and similar tools provide quantitative measures of bias that can be tracked over time and across model versions. Community engagement is essential because bias is context-dependent: what counts as biased in one application or culture may differ from another. Building equitable AI systems requires continuous vigilance and a willingness to revisit assumptions about what constitutes a "neutral" representation of language.
Limitations and Risks of Word Embeddings
Static word embeddings suffer from the polysemy problem, where a single word with multiple meanings receives only one fixed vector representation. The word "cell" has vastly different meanings in biology, telecommunications, and criminal justice, but Word2Vec or GloVe assigns it a single vector that blends all these meanings together. This blending can degrade performance on tasks where distinguishing between word senses is critical, such as medical text analysis or legal document processing. Contextual models like BERT address polysemy by generating different vectors for each usage of a word, but they come with their own costs in terms of computation and latency. The tradeoff between static simplicity and contextual accuracy remains one of the central design decisions in any NLP system. Choosing the wrong embedding approach for a given application can lead to errors that are subtle but consequential, especially in high-stakes domains like healthcare and finance.
Computational cost is a practical limitation that affects how word embeddings can be used in production systems. Training a large contextual model like BERT-large requires hundreds of GPU hours and access to expensive cloud computing infrastructure. Storing and serving contextual embeddings in real time demands significant memory and fast inference hardware, which increases operational costs. For applications that process millions of queries per day, the per-query cost of computing contextual embeddings can become prohibitive without careful optimization. Techniques like model distillation, quantization, and caching help reduce these costs, but they introduce their own tradeoffs in model quality and system complexity. The computational burden of working with advanced embedding models creates a barrier to entry for smaller organizations and researchers with limited budgets.
Data dependency represents another fundamental risk associated with word embeddings. Embeddings are only as good as the data they are trained on, and training data can be stale, incomplete, or unrepresentative. A model trained primarily on English text from Western sources will produce embeddings that poorly represent concepts, expressions, and cultural references from other linguistic traditions. Domain shift is a related challenge: embeddings trained on general web text may perform poorly when applied to specialized domains like law, medicine, or engineering where terminology and usage patterns differ significantly. Fine-tuning on domain-specific data can mitigate this gap, but it requires labeled data and expertise that may not be available. The risk of deploying general-purpose embeddings in specialized contexts is that the model will make confident but incorrect predictions based on associations that hold in general language but break down in the target domain.
How to Build and Train Word Embeddings for Your Projects
Step 1: Define Your Use Case and Select an Embedding Strategy
Before writing any code, determine what your NLP application needs to accomplish and how word embeddings fit into the overall pipeline. If your task involves general-purpose text classification with a large vocabulary, pre-trained static embeddings from Word2Vec or GloVe may be sufficient and cost-effective. For tasks requiring context-sensitive understanding, such as question answering or coreference resolution, contextual embeddings from BERT or its variants will deliver significantly better results. Consider your deployment constraints: edge devices and mobile applications may require lightweight models, while cloud-based services can accommodate larger architectures. Your choice of embedding strategy sets the foundation for every subsequent decision in the pipeline.
Pro Tip: Start with a pre-trained model and only train custom embeddings if domain-specific vocabulary or performance requirements demand it.
Step 2: Prepare and Clean Your Text Corpus
Assemble a text corpus that represents the language your model will encounter in production, including domain-specific terminology and writing styles. Clean the text by removing HTML tags, special characters, and encoding errors that could introduce noise into the training data. Normalize text by lowercasing (unless case sensitivity matters for your application) and handling contractions, abbreviations, and common misspellings. Tokenize the text into individual words or subword units using a tokenizer appropriate for your chosen embedding model.
import re
from collections import Counter
def clean_text(text):
# Remove HTML tags
text = re.sub(r'<[^>]+>', '', text)
# Remove special characters, keep alphanumeric and spaces
text = re.sub(r'[^a-zA-Z0-9\s]', '', text)
# Lowercase and strip whitespace
text = text.lower().strip()
return text
def tokenize(text, min_freq=5):
words = text.split()
word_counts = Counter(words)
# Filter out rare words below minimum frequency
vocab = {w for w, c in word_counts.items() if c >= min_freq}
return [w for w in words if w in vocab]Filter out words that appear fewer than a minimum threshold (typically 5 to 10 occurrences) to reduce noise from typos and extremely rare terms. Verify that your cleaned corpus is representative and large enough by checking vocabulary size and token counts against recommended minimums for your chosen model.
Step 3: Train Word2Vec Embeddings Using Gensim
The Gensim library provides a straightforward interface for training Word2Vec models on custom corpora in Python. Install Gensim and prepare your data as a list of tokenized sentences, where each sentence is a list of word strings. Configure the key hyperparameters: vector_size (dimensionality, typically 100 to 300), window (context window size, typically 5 to 10), min_count (minimum word frequency), and sg (0 for CBOW, 1 for Skip-gram).
from gensim.models import Word2Vec
# sentences is a list of lists: [['word1', 'word2', ...], ...]
model = Word2Vec(
sentences=tokenized_sentences,
vector_size=300,
window=5,
min_count=5,
sg=1, # Skip-gram
workers=4, # Parallel threads
epochs=10
)
# Save the model for later use
model.save("custom_word2vec.model")
# Find similar words
similar = model.wv.most_similar("embedding", topn=10)
print(similar)Monitor training by checking that loss decreases across epochs, and evaluate the resulting embeddings using word similarity and analogy tests relevant to your domain. Warning: Using too few training epochs will produce low-quality embeddings, while too many epochs can lead to overfitting on frequent word patterns.
Step 4: Load Pre-Trained Embeddings for Transfer Learning
If training from scratch is impractical, load pre-trained embeddings and adapt them to your task through fine-tuning in a neural network framework. Download pre-trained vectors from official sources: Google's Word2Vec trained on Google News, Stanford's GloVe trained on Common Crawl, or Facebook's FastText trained on Wikipedia and Common Crawl.
import numpy as np
def load_glove_embeddings(filepath, embedding_dim=300):
embeddings = {}
with open(filepath, 'r', encoding='utf-8') as f:
for line in f:
values = line.split()
word = values[0]
vector = np.array(values[1:], dtype='float32')
embeddings[word] = vector
print(f"Loaded {len(embeddings)} word vectors")
return embeddings
glove = load_glove_embeddings("glove.6B.300d.txt")Build an embedding matrix that maps your task-specific vocabulary to the pre-trained vectors, handling out-of-vocabulary words with random initialization or zero vectors. This matrix becomes the initial weight of your model's embedding layer.
Step 5: Evaluate Embedding Quality and Iterate
Assess your embeddings using both intrinsic and extrinsic evaluation methods to ensure they meet quality standards before deploying them in production. Intrinsic evaluations test the embedding space directly through word similarity benchmarks (comparing model scores to human judgments) and word analogy tests (testing if vector arithmetic produces correct results). Extrinsic evaluations measure how the embeddings perform as input features for your specific downstream task, which is the ultimate measure of their utility. Compare your custom embeddings against pre-trained baselines to determine whether the additional training effort is justified by improved task performance.
# Intrinsic evaluation: word analogy test
result = model.wv.evaluate_word_analogies('questions-words.txt')
print(f"Analogy accuracy: {result[0]:.4f}")
# Word similarity check
similarity = model.wv.similarity('king', 'queen')
print(f"Similarity (king, queen): {similarity:.4f}")If performance is below expectations, iterate by adjusting hyperparameters, expanding the training corpus, or switching to a different embedding model architecture. Document your evaluation results and model configuration for reproducibility and future reference.
Word Embeddings in the Era of Large Language Models
The rise of large language models (LLMs) like GPT-4, Claude, and Llama has not made word embeddings obsolete; instead, it has elevated their importance and expanded their scope. Every LLM contains an embedding layer as its first component, which converts input tokens into the dense vector representations that the transformer layers process and refine. The embeddings produced by these massive models are far richer than those from standalone Word2Vec or GloVe models because they benefit from training on trillions of tokens with billions of parameters. Researchers are increasingly extracting word and sentence embeddings from LLMs and using them as features for downstream tasks, a practice that combines the general knowledge of large models with the efficiency of simpler classifiers. The LLM era has not replaced word embeddings but rather supercharged them, making embedding quality and strategy more important than ever. A popular trend in NLP research involves benchmarking embeddings extracted from decoder-only models against those from traditional encoder models, revealing that both families produce valuable representations for different use cases.
Retrieval-augmented generation (RAG) has emerged as one of the most commercially significant applications of word embeddings in the LLM era. RAG systems use embedding models to encode both a knowledge base and user queries into the same vector space, then retrieve the most relevant documents to provide context for the LLM's generation. This approach grounds LLM responses in factual information, reducing hallucination and enabling the model to access knowledge that was not part of its training data. The quality of the embedding model directly determines retrieval precision, which in turn determines the quality of the generated response. Leading embedding models for RAG include OpenAI's text-embedding-3 family, Cohere's Embed-4, and open-source alternatives like Nomic embed-text-v1 and Sentence-BERT. The vector databases that store and search these embeddings have become critical infrastructure for enterprise AI, powering semantic search across millions of documents in financial services, healthcare, legal, and technology organizations.
The competitive landscape of embedding models has intensified dramatically, with both proprietary and open-source options vying for market dominance. OpenAI's text-embedding-3-large (3,072 dimensions) remains the most widely deployed commercial embedding API, while Mistral and Cohere offer strong multilingual alternatives at competitive prices. Open-source models like Nomic embed-text-v1 eliminate licensing costs entirely and allow full customization through fine-tuning on domain-specific data. The Massive Text Embedding Benchmark (MTEB) provides a standardized evaluation framework that helps practitioners compare models across retrieval, classification, clustering, and semantic similarity tasks. Entry of new players like Anthropic and xAI into the embedding space is driving rapid innovation and price competition, benefiting the broader NLP community. Embedding models are evolving from static representations toward adaptive, task-aware systems that automatically optimize for specific retrieval and classification objectives.
The Market and Industry Landscape for Embedding Technology
The commercial importance of word embeddings and text embedding technology is reflected in market data that shows explosive growth across the sector. The global NLP market is projected to reach $70.11 billion in 2026 and grow to $249.97 billion by 2031, with word embeddings forming a foundational layer of virtually every NLP application. The text embedding models market specifically reached $4.8 billion in 2025, growing at a compound annual growth rate of 18.8 percent, driven by enterprise adoption of semantic search, RAG pipelines, and AI-powered document processing. North America commanded the largest share of the global text embedding market at 38.5 percent in 2025, representing approximately $1.85 billion in market value. Industries investing most heavily in embedding technology include financial services (for compliance and document search), healthcare (for clinical NLP and drug discovery), e-commerce (for semantic product search), and technology (for code search and developer tools). The infrastructure supporting embedding deployments, including vector databases, embedding APIs, and MLOps platforms, has attracted over $450 million in venture capital funding.
The competitive dynamics of the embedding market reflect a broader trend toward specialization and domain adaptation. General-purpose embedding APIs from OpenAI, Google, and Cohere serve as the default starting point for most enterprise deployments, offering high quality and easy integration at per-token pricing. Specialized providers like Voyage AI have carved out niches in legal and medical document embedding where domain-specific training data produces significantly better retrieval results. Open-source alternatives from Nomic AI and others appeal to organizations prioritizing data sovereignty, customization, and cost control. The decision between proprietary and open-source embeddings depends on factors including data privacy requirements, fine-tuning needs, deployment infrastructure, and budget constraints. Most enterprise AI strategies now include explicit embedding model selection as part of their technology stack decisions, recognizing that the right embedding choice can materially impact the quality and cost of AI-powered products.
Where Word Embeddings Are Heading Next
The next generation of word embeddings is moving toward multimodal representations that encode text, images, audio, and video in a unified vector space. Models like CLIP (Contrastive Language-Image Pre-training) have already demonstrated that a single embedding space can meaningfully relate a photograph to a text description, enabling search across media types. Future embedding models will extend this capability to include sound, video, 3D objects, and even sensor data from IoT devices, creating universal representations that bridge all forms of human and machine-generated information. This multimodal convergence will enable applications like searching a video archive using a text query, or finding relevant research papers by uploading a diagram. The demand for multimodal AI solutions is projected to reach $4.5 billion by 2026, indicating strong commercial interest in cross-modal embedding technology. The future of word embeddings is not just about words; it is about building a shared mathematical language for every type of information.
Efficiency and adaptability are becoming the defining priorities for the next wave of embedding innovation. Matryoshka representation learning, pioneered in OpenAI's text-embedding-3 models, allows embeddings to be truncated to variable dimensions without retraining, letting users trade precision for storage and speed depending on their application's requirements. On-device embedding models are being distilled and quantized to run natively on smartphones and edge devices, enabling real-time NLP without cloud connectivity. Domain-adaptive embeddings that automatically fine-tune themselves using retrieval feedback loops are emerging from research labs and moving toward production deployment. These advances collectively reduce the cost and complexity of deploying high-quality embeddings, making the technology accessible to a broader range of organizations and use cases. By 2027, embedding models are expected to function as living infrastructure components that continuously optimize themselves based on real-world usage patterns.
The ethical and regulatory dimensions of word embeddings will become increasingly prominent as embedding-powered systems influence more decisions with real-world consequences. The EU AI Act and similar regulations are creating requirements for transparency and fairness in AI systems, which directly apply to the embedding models that underpin them. Organizations will need to document their embedding training data, disclose known biases, and demonstrate mitigation efforts as part of regulatory compliance. The development of interpretable embedding techniques that allow humans to understand why two items are considered similar or different will become a competitive differentiator. Bias auditing tools, fairness benchmarks, and community-driven evaluation frameworks will mature into standard components of the embedding development lifecycle. The word embeddings of the future will not just be more powerful; they will also be more accountable, transparent, and aligned with the values of the communities they serve.
Key Insights
- According to a MarketsandMarkets report, the global NLP market is projected to grow from $70.11 billion in 2026 to $249.97 billion by 2031 at a 29 percent CAGR, with word embeddings forming a foundational technology layer across the sector.
- The text embedding models market reached $4.8 billion in 2025 and is projected to hit $22.6 billion by 2034, growing at an 18.8 percent CAGR driven by enterprise semantic search and RAG adoption.
- E-commerce platforms implementing embedding-based semantic search have reported conversion rate improvements of 18 to 32 percent compared to traditional keyword-based approaches in controlled A/B tests.
- Over 65 percent of Fortune 1000 companies had initiated or completed internal knowledge base modernization projects incorporating semantic search powered by embedding models as of early 2026.
- Research published through the ACL Anthology demonstrates that embeddings extracted from large decoder-only language models can match or exceed traditional encoder-based embeddings on standard NLP benchmarks.
- The vector database ecosystem, including Pinecone, Weaviate, Qdrant, Milvus, and Chroma, raised over $450 million in venture capital in 2024 and 2025, signaling strong investor confidence in embedding-powered search infrastructure.
- Studies from Springer and the ACM have shown that word embeddings consistently encode gender, racial, and cultural biases from their training data, with these biases persisting even after debiasing techniques are applied.
The data paints a clear picture: word embeddings have evolved from an academic curiosity into critical commercial infrastructure worth billions of dollars annually. The technology's growth trajectory mirrors the broader expansion of NLP and AI, where every gain in language understanding translates directly into business value through better search, more accurate classification, and more natural human-computer interaction. Enterprise adoption has reached a tipping point, with the majority of large organizations now treating embedding strategy as a core technology decision rather than a niche technical choice. The tension between powerful but biased models and the growing demand for ethical AI remains unresolved, creating both a challenge and an opportunity for organizations willing to invest in responsible embedding practices. Open-source alternatives are narrowing the quality gap with proprietary models, democratizing access to high-quality embeddings for smaller teams and under-resourced languages. The convergence of text, image, and audio embeddings into unified multimodal representations signals the next phase of this technology's evolution, one that will reshape how humans and machines interact with information across all modalities.
Comparing Word Embedding Approaches
| Dimension | Static Embeddings (Word2Vec, GloVe) | Subword Embeddings (FastText) | Contextual Embeddings (BERT, ELMo) |
|---|---|---|---|
| Transparency | Vectors are interpretable through analogy tests and nearest neighbor analysis | Subword decomposition provides partial interpretability of how vectors are constructed | Black-box transformer layers make individual embedding dimensions difficult to interpret |
| Participation | Open-source models and pre-trained vectors are freely available for any developer | Pre-trained models cover 157 languages, broadening access for multilingual communities | Large model sizes and compute requirements limit participation to well-resourced teams |
| Trust | Well-studied properties and decades of research provide high confidence in behavior | Vocabulary robustness builds trust in production systems handling messy real-world text | Superior task performance builds trust but complexity reduces ability to audit decisions |
| Decision Making | Fixed representations simplify debugging but miss context-dependent meaning | Subword approach reduces out-of-vocabulary errors that could cause incorrect decisions | Context-aware representations enable more accurate decisions in ambiguous situations |
| Misinformation | Static vectors cannot distinguish sarcasm, irony, or context-dependent meaning | Same limitations as static models for context-dependent language understanding | Better context modeling improves detection of sarcasm, irony, and misleading content |
| Service Delivery | Low latency and minimal compute requirements enable real-time service at scale | Similar performance profile to static models with better vocabulary coverage | Higher latency and compute costs require optimization for real-time service delivery |
| Accountability | Simple models are easy to audit for bias and track changes across versions | Subword mechanics add complexity but remain auditable with proper documentation | Complex architectures require specialized tools and expertise for meaningful accountability |
How Organizations Are Applying Word Embeddings Across Industries
Google's Search Quality Transformation Through Embedding Models
Google's integration of word embeddings into its search infrastructure represents one of the most consequential deployments of the technology. The company's BERT-based search update, launched in 2019 and refined continuously through 2025, uses contextual word embeddings to understand the intent behind search queries rather than relying solely on keyword matching. According to Google's AI blog, the BERT integration affected approximately 10 percent of all English-language search queries at launch, improving results for complex, conversational queries where prepositions and context words significantly change the meaning. The system processes both the query and the indexed content through embedding models, comparing their vector representations to surface the most semantically relevant results. Critics note that the reliance on embedding models makes the search ranking process less transparent and harder for website owners to optimize for, creating a tension between search quality and the openness of the search ecosystem.
Spotify's Embedding-Powered Recommendation Engine
Spotify uses word embeddings and related vector representation techniques to power its music recommendation system, processing over 600 million users' listening patterns. The company's engineering team treats songs, playlists, and user listening sessions analogously to sentences and words, applying Word2Vec-inspired algorithms to learn vector representations of tracks based on their co-occurrence in playlists and listening sessions. Songs that frequently appear in similar playlists receive similar embeddings, enabling the system to recommend tracks that share musical characteristics even if they come from different genres or artists. This approach has been credited with driving engagement on Spotify's Discover Weekly feature, which delivers personalized playlists to millions of users each Monday. The limitation is that embedding-based recommendations can create filter bubbles, where users receive increasingly narrow suggestions that reinforce existing preferences rather than exposing them to genuinely novel music.
JPMorgan Chase's Compliance Document Search
JPMorgan Chase deployed embedding-powered semantic search across its compliance and legal document repositories, processing millions of pages of regulatory documents, contracts, and internal policies. The system uses fine-tuned embedding models to encode legal and financial text into vectors that capture domain-specific meaning, allowing compliance officers to search for conceptually related regulations rather than relying on exact keyword matches. According to JPMorgan's technology reports, the semantic search system reduced the time required for regulatory compliance reviews by over 30 percent while improving the completeness of document retrieval. The implementation required extensive fine-tuning on financial and legal corpora to ensure that domain-specific terminology was accurately represented in the embedding space. The primary challenge has been maintaining embedding quality as regulations change, requiring periodic retraining and validation to ensure the model captures new terminology and regulatory concepts.
Lessons From Word Embedding Deployments in Practice
Case Study: Amazon's Product Search Embedding Overhaul
Amazon faced the challenge of connecting customer search queries to relevant products across a catalog containing hundreds of millions of items in dozens of languages. The company's product search team implemented a dual-encoder architecture that uses separate embedding models to encode queries and product descriptions into a shared vector space, enabling semantic matching at massive scale. The system improved search relevance metrics by 15 to 20 percent for queries where traditional keyword matching was weakest, particularly for long-tail and conversational queries. The deployment required custom training on Amazon's product catalog data and careful optimization to serve embedding lookups at sub-50-millisecond latency for billions of daily queries. A key limitation was the cold-start problem for new products that lacked sufficient text descriptions to produce high-quality embeddings, requiring fallback mechanisms for items added within the previous 24 hours. The ongoing challenge of keeping embeddings current as product catalogs and customer language patterns evolve requires continuous retraining and evaluation cycles.
Case Study: The Mayo Clinic's Clinical NLP Pipeline
The Mayo Clinic developed a clinical NLP pipeline that uses domain-adapted word embeddings to extract structured information from millions of unstructured clinical notes, discharge summaries, and pathology reports. The team fine-tuned BERT-based embeddings on clinical text from their electronic health records, creating representations that accurately capture medical terminology, abbreviations, and contextual references that general-purpose embeddings handle poorly. The system extracts diagnoses, medications, adverse events, and treatment outcomes with significantly higher accuracy than approaches using general-purpose embeddings, reducing the time required for clinical research studies from months to days. According to Mayo Clinic Proceedings, the pipeline has been used to support retrospective studies on treatment effectiveness across patient populations numbering in the hundreds of thousands. The primary controversy surrounds patient privacy: even anonymized clinical text can contain identifiable patterns, and the embedding models trained on this data may encode patient-specific information in ways that are difficult to detect or control.
Case Study: Airbnb's Listing Embedding System
Airbnb developed a listing embedding system that encodes property descriptions, amenities, location features, and guest reviews into vector representations used for search ranking and recommendation. The system treats each listing as a "word" and each user session (a sequence of listings viewed and booked) as a "sentence," applying Word2Vec-style training to learn which listings are functionally similar from a traveler's perspective. The embedding approach improved booking conversion rates for search results and enabled personalized recommendations that account for each user's demonstrated preferences. Airbnb published its approach in a KDD conference paper, demonstrating measurable improvements in click-through and booking rates compared to previous feature-engineering approaches. The limitation is that the embeddings capture correlation rather than causation, meaning the system cannot distinguish between listings that are truly similar and listings that happen to attract the same users for unrelated reasons.
Frequently Asked Questions About Word Embeddings
A word embedding is a way of representing a word as a list of numbers that captures the word's meaning. These numbers are learned from large amounts of text so that words with similar meanings get similar number patterns. The technique allows computers to process language mathematically rather than treating words as meaningless symbols.
Word embeddings capture meaning by analyzing patterns of word co-occurrence across billions of sentences in training data. Words that consistently appear in similar contexts receive similar vector representations because the training algorithm assigns nearby positions in the vector space. This process encodes semantic relationships, syntactic patterns, and conceptual associations into the numeric structure of each word's vector.
Word2Vec uses a prediction-based approach with a shallow neural network that learns embeddings by predicting context words from target words or vice versa. GloVe uses a count-based approach that constructs a global word co-occurrence matrix and learns vectors that encode co-occurrence probability ratios. Both produce high-quality embeddings, but GloVe captures global statistical patterns more explicitly while Word2Vec focuses on local context windows.
Word embeddings are more relevant than ever because every large language model uses an embedding layer as its first processing step. LLMs have also created new demand for standalone embedding models that power retrieval-augmented generation systems, semantic search, and vector databases. The embedding model market is growing at an 18.8 percent compound annual growth rate precisely because LLM adoption drives embedding demand.
Static embedding models like Word2Vec assign a single vector per word, blending all meanings into one representation. Contextual models like BERT generate different vectors for the same word depending on the surrounding sentence, effectively disambiguating between meanings. If your application deals with polysemous words in context-dependent ways, contextual embeddings are the better choice.
The word embedding matrix is a two-dimensional array where each row corresponds to a word in the vocabulary and each column represents one dimension of the embedding. The matrix stores the learned vector for every word and serves as a lookup table during model inference. Its dimensions are vocabulary size (V) by embedding dimensionality (D), typically resulting in a matrix with millions of entries.
The main types include frequency-based methods (TF-IDF), static neural embeddings (Word2Vec, GloVe, FastText), contextual embeddings (ELMo, BERT, GPT), and multimodal embeddings (CLIP). Each type represents a different generation of the technology with increasing sophistication and capability. The choice depends on the task requirements, available compute resources, and the importance of context sensitivity.
Word embeddings are trained by exposing a neural network or matrix factorization algorithm to large text corpora and optimizing it to predict word co-occurrence patterns. The model adjusts vector values through gradient descent to minimize prediction errors across millions of training examples. Training typically requires billions of tokens and takes hours to days depending on hardware and model complexity.
Yes, word embeddings routinely encode biases present in their training data, including gender stereotypes, racial associations, and cultural prejudices. These biases can propagate into downstream applications and cause discriminatory outcomes in hiring, lending, and content moderation systems. Debiasing techniques exist but do not eliminate all forms of bias, making ongoing monitoring and auditing essential.
Common dimensionalities range from 50 to 3,072 depending on the model and use case. Word2Vec and GloVe typically use 100 to 300 dimensions, while BERT uses 768 dimensions for its base model and 1,024 for its large variant. Modern commercial embedding APIs like OpenAI's text-embedding-3-large support up to 3,072 dimensions with the option to truncate for efficiency.
Start by evaluating your task requirements: context sensitivity, vocabulary coverage, computational budget, and latency constraints. Use static embeddings for simple, high-throughput tasks and contextual embeddings for tasks requiring nuanced language understanding. Test multiple models on your specific data and measure downstream task performance rather than relying solely on benchmark scores.
Word embeddings represent individual words as vectors, while sentence embeddings represent entire sentences or paragraphs as single vectors. Sentence embeddings are typically computed by pooling or aggregating word-level representations from contextual models like BERT. Sentence embeddings are essential for tasks like semantic search, document similarity, and passage retrieval where meaning operates at the sentence level.
In deep learning, word embedding refers to the learned representation layer that converts discrete word tokens into continuous vectors that neural networks can process. This embedding layer is typically the first layer of any deep learning model that processes text. The layer can be initialized with pre-trained vectors and then fine-tuned during task-specific training.
Word embeddings enable semantic search by projecting both queries and documents into the same vector space, allowing matching based on meaning rather than exact keyword overlap. A search for "affordable electric vehicles" can retrieve documents about "budget-friendly EVs" even without shared keywords. This capability dramatically improves search relevance and user satisfaction across web search, enterprise search, and e-commerce platforms.