Classification And Regression Trees or CART for short is a term used to describe decision tree algorithms that get used for classification and regression tasks. This term was first introduced in 1984 by Leo Breiman, Jerome Friedman, Richard Olshen, and Charles Stone. Before talking about classification and regression trees, we need to first investigate what a decision tree is.
Basically, a decision tree is a series of if-else statements that can be used to predict a certain outcome based on data. The goal of a decision tree is to create a model that can predict the value of the target variable by learning decision rules which are inferred from the data. Decision trees are drawn upside down with the root at the top. It will then split at branches, and the end of these branches are the leaves which is where the decisions are no longer split.
Introduction to Classification and Regression Trees in Machine Learning
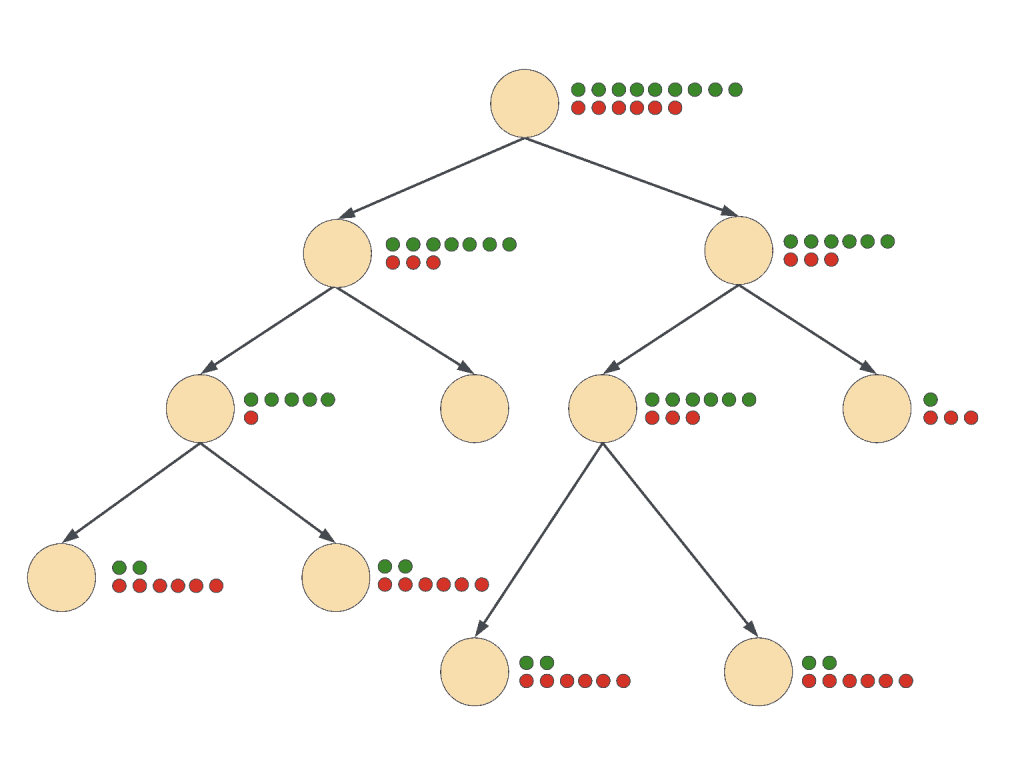
This example is a very simple decision tree. A real dataset will have way more branches and thus be a bigger tree. To create a decision tree, we need to know which features to choose from a dataset and what conditions to use for splitting. Finally, we need to know where to stop.
Advantages and Disadvantages of Decision Trees
There are advantages and disadvantages of using decision trees for machine learning. Some advantages include:
Decision trees are very easy to understand and interpret because they can be visualized.
Does not require data to be normalized. This makes it require very little data preparation.
It can handle both numeric data and categorical data.
It can handle multiple output problems.
A decision tree can be validated using statistical tests. This makes it possible to calculate how reliable the model is.
There are also disadvantages when using decision trees. Some disadvantages include:
Sometimes decision tree learners may over complicate the tree and not generalize the data well. This problem is known as overfitting.
They don’t have very good stability. One small variation in data may cause the tree to completely change.
Decision trees are not good at extrapolating data because they are not smooth or continuous.
Decision trees have issues learning XOR, parity, or multiplexer problems.
Classification Tree
Now that we know the advantages and disadvantages of using general decision trees, we can look at what a classification tree is. A classification tree is an algorithm used when the target variable is either fixed or categorical. This algorithm is then used to identify the class within which the target variable would most likely fall. An example of when to use a classification tree would be to find out who will or who will not graduate from college. A classification tree splits data based on the homogeneity of the data itself. In general, classification trees are used for classification type problems.
Regression trees on the other hand are used when the response variable is continuous. For example, if the response variable is the temperature of an object, then a regression tree is used. A regression tree model is fit to the target variable using each of the independent variables. Keep in mind an independent variable is one that stands alone and does not change by the other variables that you are measuring. The data in a regression tree is split on independent variables. In general, regression trees should be used for prediction type problems.
Advantages of Classification and Regression Trees
So why do we use classification and regression trees over regular decision trees? Well, the purpose of them is to create a lot of if-else conditions until we have enough data for an accurate classification or prediction of a case. They have some advantages over normal decision trees, these include:
The results from classification and regression trees are simpler compared to those from decision trees. Having simpler data allows for quicker classification of new observations.
Classification and regression trees are nonparametric and nonlinear. Nonparametric means the data can be collected from a sample that does not follow a specific distribution. Nonlinear means there is no correlation between the independent and dependent variables. This allows classification and regression trees to be very useful when data mining because there is no beforehand knowledge about how different variables will be related.
Classification and regression trees have a built-in function that performs feature selection. Feature selection is method of noise removal by only using relevant data. Since the tree is split from the top with the most important variables, feature selection is already done.
Disadvantages of Classification and Regression Trees
Classification and regression trees are used often in machine learning, however there are some disadvantages to them. Below are some of them:
One common disadvantage that is prevalent in most machine learning models is overfitting. This occurs when the tree considers a lot of noise from the data and comes up with inaccurate results. Think of data as signal plus noise. The signal is the wanted behavior while the noise is the unwanted behavior.
Classification and regression trees suffer from high variance in predictions. As discussed above with general decision trees, low variance in the data will lead to high variance in the tree, thus giving classification and regression trees low stability.
Since classification and regression trees are usually complex, they suffer from low bias. This makes it tough for the models to account for new data.
How to use Classification and Regression Trees in Python
Now that we understand the basics of what classification and regression trees are, we can look at how to code them in Python. Lucky for us libraries for classification and regression trees already exist in Python as part of scikit-learn so we do not have to create them. We can simply import them as seen below:
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import DecisionTreeRegressor
First, we will look at how to use the classification tree. To do this we need to load datasets and create objects to store the data and target value respectively. In the below example we are using a wine dataset and using X to store objects and y to store data and target values:
dataset = datasets.load_wine()
X = dataset.data; y = dataset.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25)
Now let’s look at how to use a classification tree as a machine learning model. Below we fit the data using DecisionTreeClassifier:
model = DecisionTreeClassifier()
model.fit(X_train, y_train)
print(model)
Now let’s look at the setup for regression trees. It is very similar to classification trees in code as seen below. In the example, we use a dataset of Chicago.
dataset = datasets.load_chicago()
X = dataset.data; y = dataset.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25)
Setting up the regression tree as a machine learning model is also very similar to classification trees as seen below:
model = DecisionTreeRegressor()
model.fit(X_train, y_train)
print(model)
Classification and regression trees are used to predict outcomes based on predictor values. The best-case use for them is when you require very little preprocessing. They are also easy to understand which gives them an edge over other models.
References
Breiman, Leo. Classification and Regression Trees. Routledge, 2017.
“Classification and Regression Trees.” Series in Machine Perception and Artificial Intelligence, WORLD SCIENTIFIC, 2019, pp. 23–49, http://dx.doi.org/10.1142/9789811201967_0002. Accessed 14 June 2023.
Rokach, Lior. Data Mining with Decision Trees: Theory and Applications. World Scientific, 2008.
Tatsat, Hariom, et al. Machine Learning and Data Science Blueprints for Finance. “O’Reilly Media, Inc.,” 2020.
Introduction
Classification And Regression Trees or CART for short is a term used to describe decision tree algorithms that get used for classification and regression tasks. This term was first introduced in 1984 by Leo Breiman, Jerome Friedman, Richard Olshen, and Charles Stone. Before talking about classification and regression trees, we need to first investigate what a decision tree is.
Table of contents
What Is A Decision Tree?
Basically, a decision tree is a series of if-else statements that can be used to predict a certain outcome based on data. The goal of a decision tree is to create a model that can predict the value of the target variable by learning decision rules which are inferred from the data. Decision trees are drawn upside down with the root at the top. It will then split at branches, and the end of these branches are the leaves which is where the decisions are no longer split.
An example of a decision tree can be seen below:
This example is a very simple decision tree. A real dataset will have way more branches and thus be a bigger tree. To create a decision tree, we need to know which features to choose from a dataset and what conditions to use for splitting. Finally, we need to know where to stop.
Advantages and Disadvantages of Decision Trees
There are advantages and disadvantages of using decision trees for machine learning. Some advantages include:
There are also disadvantages when using decision trees. Some disadvantages include:
Classification Tree
Now that we know the advantages and disadvantages of using general decision trees, we can look at what a classification tree is. A classification tree is an algorithm used when the target variable is either fixed or categorical. This algorithm is then used to identify the class within which the target variable would most likely fall. An example of when to use a classification tree would be to find out who will or who will not graduate from college. A classification tree splits data based on the homogeneity of the data itself. In general, classification trees are used for classification type problems.
Also Read: How to Use Linear Regression in Machine Learning
Regression Tree
Regression trees on the other hand are used when the response variable is continuous. For example, if the response variable is the temperature of an object, then a regression tree is used. A regression tree model is fit to the target variable using each of the independent variables. Keep in mind an independent variable is one that stands alone and does not change by the other variables that you are measuring. The data in a regression tree is split on independent variables. In general, regression trees should be used for prediction type problems.
Advantages of Classification and Regression Trees
So why do we use classification and regression trees over regular decision trees? Well, the purpose of them is to create a lot of if-else conditions until we have enough data for an accurate classification or prediction of a case. They have some advantages over normal decision trees, these include:
Disadvantages of Classification and Regression Trees
Classification and regression trees are used often in machine learning, however there are some disadvantages to them. Below are some of them:
How to use Classification and Regression Trees in Python
Now that we understand the basics of what classification and regression trees are, we can look at how to code them in Python. Lucky for us libraries for classification and regression trees already exist in Python as part of scikit-learn so we do not have to create them. We can simply import them as seen below:
First, we will look at how to use the classification tree. To do this we need to load datasets and create objects to store the data and target value respectively. In the below example we are using a wine dataset and using X to store objects and y to store data and target values:
Now let’s look at how to use a classification tree as a machine learning model. Below we fit the data using DecisionTreeClassifier:
Now let’s look at the setup for regression trees. It is very similar to classification trees in code as seen below. In the example, we use a dataset of Chicago.
Setting up the regression tree as a machine learning model is also very similar to classification trees as seen below:
Also Read: Introduction to XGBoost and its Uses in Machine Learning
Conclusion
Classification and regression trees are used to predict outcomes based on predictor values. The best-case use for them is when you require very little preprocessing. They are also easy to understand which gives them an edge over other models.
References
Breiman, Leo. Classification and Regression Trees. Routledge, 2017.
“Classification and Regression Trees.” Series in Machine Perception and Artificial Intelligence, WORLD SCIENTIFIC, 2019, pp. 23–49, http://dx.doi.org/10.1142/9789811201967_0002. Accessed 14 June 2023.
Rokach, Lior. Data Mining with Decision Trees: Theory and Applications. World Scientific, 2008.
Tatsat, Hariom, et al. Machine Learning and Data Science Blueprints for Finance. “O’Reilly Media, Inc.,” 2020.
Share this: